
Paco Nathan's latest column dives into data governance.
Introduction
Welcome back to our monthly burst of themes and conferences. This month’s article features updates from one of the early data conferences of the year, Strata Data Conference – which was held just last week in San Francisco. In particular, here’s my Strata SF talk “Overview of Data Governance” presented in article form. It includes perspectives about current issues, themes, vendors, and products for data governance.
My interest in data governance (DG) began with the recent industry surveys by O’Reilly Media about enterprise adoption of “ABC” (AI, Big Data, Cloud). I introduced these themes in “Three surveys of AI adoption reveal key advice from more mature practices” and explored them in even more detail in “Episode 7” of this column. Let’s take a look at the results for one survey question in particular, “Which solutions is your organization currently building or evaluating?”
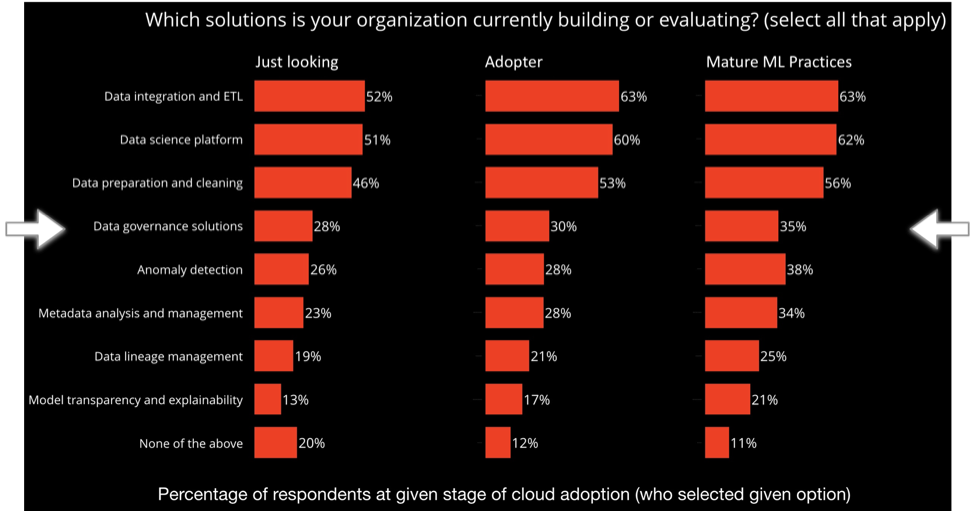
The top three items are essentially “the devil you know” for firms which want to invest in data science: data platform, integration, data prep. Rinse, lather, repeat. Those are table stakes in this game.
Data governance shows up as the fourth-most-popular kind of solution that enterprise teams were adopting or evaluating during 2019. That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Plus, the more mature machine learning (ML) practices place greater emphasis on these kinds of solutions than the less experienced organizations. Taken together, those points warranted a much deeper review of the field.
Granted, I’m no expert in DG. I have expertise in data science, plus adjacent fields such as cloud computing, software architecture, natural language, data management… So I should have a good working knowledge about the topic – but I didn’t. That presented an opportunity to learn, putting me in the same position as much of the audience. Plus it’s well-nigh time for “machine learning natives” to jump into the dialog about DG. Perhaps we can help explore these issues starting from a different set of perspectives and priorities?
So this month let’s explore these themes:
- 2018 represented a flashpoint for DG fails, prompting headlines worldwide and resulting in much-renewed interest in the field.
- Consider: what impact does ML have on DG and vice versa?
- Here’s a survey of issues, tools, vendors, standards, open source projects, and other considerations.
- Changes in system architecture get reflected as substantial changes in how we collect, use, and manage data, and therefore become drivers for DG.
That last point is what I’ll take away as my north star for DG. Look toward the evolving changes in system architecture to understand where data governance will be heading.
Definition and Descriptions
To explore DG and give the topic a fair treatment, let’s approach from a few different angles. We’ll start with standard definitions – the currently accepted wisdom in the industry. Then, for contrast, we’ll tack over to the “cynical perspectives” which are also quite prevalent in the industry. Next, we’ll take a historical look at the evolution of system architectures which has had so much impact on the complexities of DG.
One other note: some people ask why this includes so much detail about security. The short answer is it’s not practical (or responsible) to separate the concerns of security, data management, and system architecture. They co-evolve due to challenges and opportunities among any of the three areas. The longer answer is that in the context of machine learning use cases, strong assumptions about data integrity lead to brittle solutions overall. In other words, don’t plan on 100% security, 100% privacy, 100% correctness, 100% fairness, etc. Those days are long gone if they ever existed. Instead, we must build robust ML models which take into account inherent limitations in our data and embrace the responsibility for the outcomes. In other words, #adulting. For a much more detailed explanation, see the interview between Ben Lorica and Andrew Burt linked toward the end of this article.
For definitions, let’s start with a standard textbook/encyclopedia definition:
“Data governance encompasses the people, processes, and information technology required to create a consistent and proper handling of an organization’s data across the business enterprise.”
Probably the best one-liner I’ve encountered is the analogy that:
DG is to data assets as HR is to people.
That definition plus the one-liner provide good starting points. Also, while surveying the literature two key drivers stood out:
- Risk management is the thin-edge-of-the-wedge for DG adoption in the enterprise.
- Process efficiency (cost reduction) is generally a second priority﹣at least it has been so far – although that could change.
One other anecdote… during the three most recent recessions, DG spending increased faster than overall IT spending. So it appears relatively recession-proof. Not that I’m implying anything about current economic conditions vis-a-vis the timing of this report… #justsayin.
Cynical Perspectives
At that point, I began to run into more cynical perspectives. Those are great for counterpoint. For example, looking at top hits in a Google search, Rob Karel's article in Computerworld stuck out – ignoring its somewhat unfortunate title. To paraphrase, even among people who have years of experience working in data management, the topic of DG often gets dismissed because: (1) it’s hard; and (2) there’s been a long, just-begging-you-for-an-eye-roll history of false starts.
The on-the-ground reality of DG presents an almost overwhelming array of topics. Some of the finer points seem amorphous at best. While there are many point solutions for the diverse aspects of governance, the word “data” implies many different things in technology now, with oh-so-many touch points – which we’ll review below.
So when I asked people who are experts in this field, it was no surprise that their responses came back posed as questions. Overall, I’m not convinced there are many people who are complete experts in DG. It’d be a difficult landscape for anyone to maintain a fully comprehensive view. Even so, there’s a growing apprehension that we need to figure it out. And soon!
Considering some of the possible motivations for some of those cynicisms … my friend Alistair Croll, who’s co-chair for Strata, wrote an interesting article, “Different continents, different data science,” last year on Medium. Admittedly, the article makes sweeping generalizations about geographic differences in how people regard data. Even so, these generalizations ring true:
- China: people worry about the veracity of the data (because the government tends to be preoccupied about efforts to collect data at scale).
- Western Europe: people worry about storage and analysis of data (because the region has historical precedents for terrible misuses of stored data).
- North America: people worry about unintended consequences of acting on data (because, well, there are so damn many lawyers preoccupied with giving people more reasons to worry about the unintended consequences of everything).
Arguably, any of those worries might cause some distrust of – or at least serious questions about – DG solutions. However, in summary, Alistair leverages those points to frame an important perspective:
“The reality is, any solid data science plan needs to worry about veracity, storage, analysis, and use.”
Well said.
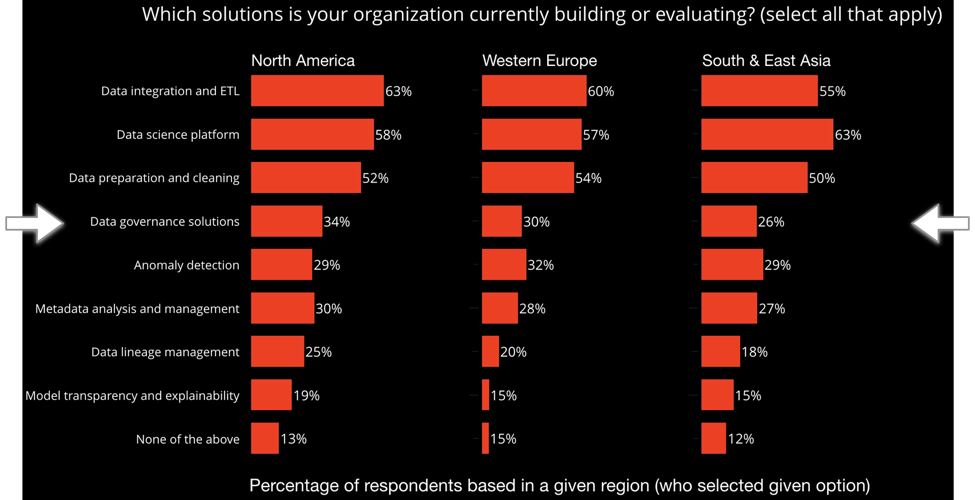
Looking at our survey results segmented by geography, it is interesting how those regions prioritize DG and the adjacent topics: North America (highest), Western Europe (middle), South and East Asia (lowest):
At this point, we have definitions and counterpoint. In other words, DG as it’s intended to be implemented along with perspectives about the reality of how DG has been implemented. I’ll gladly take the bad with the good, then try to see where we’re headed next. To get a better sense of the present situation of DG and the near-term outlook, first, let’s take a careful look at the history of how we got to this point. How did the challenges and opportunities related to security, data management, and system architecture get braided together throughout the past ~6 decades of IT?
A brief pictorial history
As the story goes, the general history of DG is punctuated by four eras:
- “Application Era” (1960–1990) – some data modeling, though not much concern overall
- “Enterprise Repository Era” (1990–2010) – first generation DG solutions
- “More Policies Emerged” (2010-2018)
- “Flashpoint” (2018) – GDPR went into effect, plus major data blunders happened seemingly everywhere
Wall St Journal labeled the year 2018 as “a global reckoning on data governance” in reference to investigations about Cambridge Analytica, Facebook getting grilled by US Congress about data misuse, billions of people affected by data breaches occurring across a wide range of companies, schools, government agencies, etc.
That certainly helps to set expectations. Concern about DG is highly warranted now; however, that comes at a time when the realities of DG are becoming even more complex.
Considering those complexities, I felt compelled to draw pictures – attempting to sketch the “how” and “where” throughout the history of DG, to help make those issues cohere better.
1970s and earlier
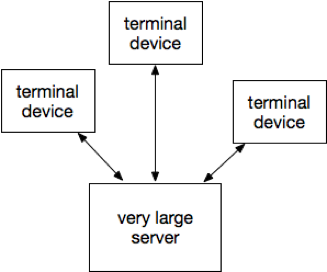
The general idea is that there’s a very large server, plus some terminals connected over proprietary wires. In other words, mainframes prevail during this period. Data is part of the applications running within that very large server. Even so, there isn’t much differentiation within that architecture about governing data – other than system controls for access permissions, backups, and so on. In other words, DG was not quite a thing yet.
FWIW, I asked during the talk “Who started programming during this period of punch cards and teletypes?” MVS, VSAM, JCL, APL, etc. Fortunately, a few other people raised their hands. Otherwise, I’d start feeling old now. Or perhaps “older” is a better way to say that. Or something.
1980s
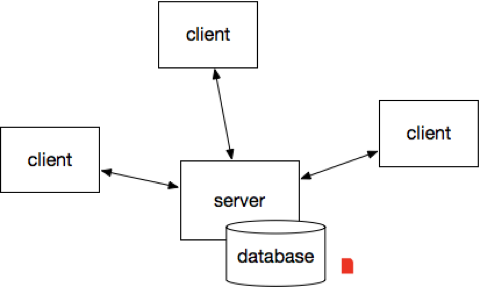
During the 1960s and 1970s, Unix happened, the C programming language happened, minicomputers happened, ARPAnet happened, Ethernet happened, UUCP happened. Networks emerged. Architectures changed. Programming styles changed. Software startups gained much more attention. Many novel ideas challenged the conventional wisdom of having a very large server connected to some terminals. While the outcomes of these many changes took several years to coalesce, eventually people began to think in terms of a new architectural pattern called client-server.
Client-server applications ran on one server, then communicated with other servers via networking. Email is a good example.
Fun fact: in the early 1980s I attended a Systems seminar by some of our department’s grad students and professors, plus their colleagues from a nearby university with bears, who presented about a thing called the “Stanford University Network” workstation. They’d launched a startup for building these “SUN Workstations” which were becoming popular. Upstairs another professor was planning the launch of a new networking protocol suite called TCP/IP. Around the corner, a couple of sysadmins for the DEC computer systems used across campus were busy co-opting grad students and university resources to build blue plastic “Gandalf boxes” – which we used to switch terminals between different local area networks. They got busted and moved off campus, renaming their company Cisco. At the time I was more concerned with midterms, playing keyboards in New Wave bands, and a weird area of research called “neural networks” so I stayed mostly oblivious to how those companies – DEC, Sun, Cisco – were rapidly becoming the emblematic success stories of the client-server era.
So far, DG was limited (see the tiny red dot above) but growing: applications were no longer simply all running on one very large server, so login passwords don’t quite cover access controls anymore. In other words, we had an inkling that DG would be needed eventually, but nobody had quite gotten around to it. Surely there must have been standards committees busy on the problem somewhere? (Can you cite earlier examples? Tweet suggestions on my public timeline at @pacoid)
1990s
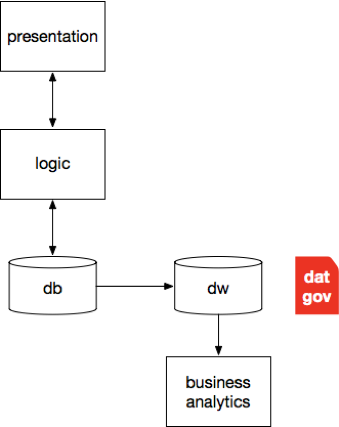
Aha! Here’s where the DG action began to happen. By the 1990s, internetworking (TCP/IP) had become a popular thing. Applications running on the Internet drove substantial changes in architecture, which changed our notions of how to govern data.
Fun fact: I co-founded an e-commerce company (realistically, a mail-order catalog hosted online) in December 1992 using one of those internetworking applications called Gopher, which was vaguely popular at the time. Several concerned people inquired whether the practice was even legal… Seriously, engaging in commerce over computer networks which were hosted by universities and companies and government organizations, using file transfer and email for profit – was that really okay? Turns out it was. Except that our oddball media collective converted over to WWW just a few months later, by popular demand. Along with the rest of the world. Sorry Gopher.
As a consequence of the web, the two tiers of the client-server era gave way to a three-tier architecture. The presentation layer moved UX into the browser. Business logic which had been in the applications before was now refactored into a middle-tier layer – rapidly becoming called “middleware” a.k.a. application servers. Increasingly, these were simply web servers. Most of the data management moved to back-end servers, e.g., databases. So we had three tiers providing a separation of concerns: presentation, logic, data.
Note that data warehouse (DW) and business intelligence (BI) practices both emerged circa 1990. Given those two, plus SQL gaining eminence as a database strategy, a decidedly relational picture coalesced throughout the decade. Thus the “Enterprise Repository Era” of DG emerged as an industry practice then and there, in that lower-third tier amidst all the relational-ness.
Those times were relatively simple: keep all your data in your database, far behind the network perimeter, far removed from attackers, subject to well-defined permissions policies – and, oh yeah, remember to perform backups.
2000s
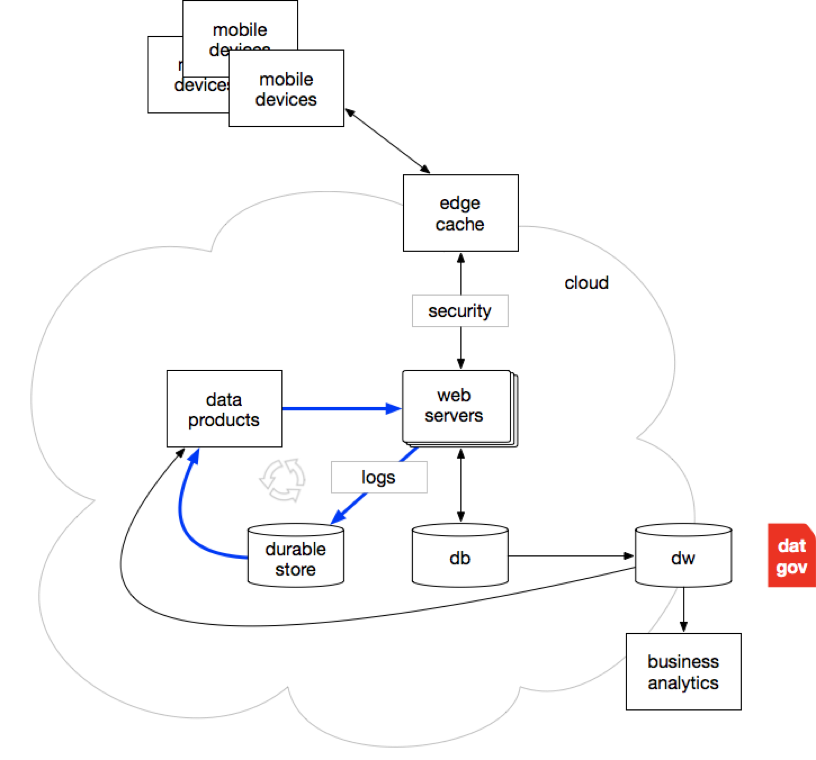
Now the picture starts getting more cluttered. Cloud gets introduced: Amazon AWS launched in public beta in 2006. Mobile gets introduced: the term “CrackBerry” becomes a thing in 2006, followed by the launch of the iPhone the following year. Edge caches become crucial for managing data on its way from web servers to mobile devices. Network security mushrooms with VPNs, IDS, gateways, various bump-in-the-wire solutions, SIMS tying all the anti-intrusion measures within the perimeter together, and so on. E-commerce grows big and serves as a forcing function for so many security concerns (e.g., credit cards). Data is on the move.
The companies emerging as tech giants during the early part of the 2000s had much common ground. The initial four recognized, independently, how the exorbitant costs of RDBMS licensing would hamstring their growing businesses. Instead, they refactored their monolithic web apps (e.g., middleware) circa late 1997 based on horizontal scale-out approaches and significantly less direct use of SQL. That resulted in server farms, collecting volumes of log data from customer interactions, data which was then aggregated and fed into machine learning algorithms which created data products as pre-computed results, which in turn made web apps smarter and enhanced e-commerce revenue. Moreover, that data is starting to fly all the way out to mobile devices and back, in mass quantities. Andrew Ng later described this strategy as the “Virtuous Cycle of AI” – a.k.a. the flywheel effect. In other words, those early tech giants invented Cloud, Big Data, and the early Data Science practices in one fell swoop. Booyah!
Note how the DW+BI thing is over in the back-end server corner of the diagram, with DG as a component. So much has evolved throughout the remainder of the diagram, but not this part – where DG is still happily enjoying its “Enterprise Repository Era” halcyon days. So much data is flowing through the other parts, but that’s not the concern of DG solutions. Not yet.
Fun fact: in 2011 Google bought remnants of what had previously been Motorola. They sold off most of the company later, retaining some of its IP, and are known to have kept copies of internal documents. Somewhere in that archive is a 1990 internal white paper about “Smartphone applications using neural networks with hardware acceleration” – co-authored by yours truly – which the top Motorola execs in charge of bold tech initiatives read and didn’t find especially interesting. I find that amusing.
2010s
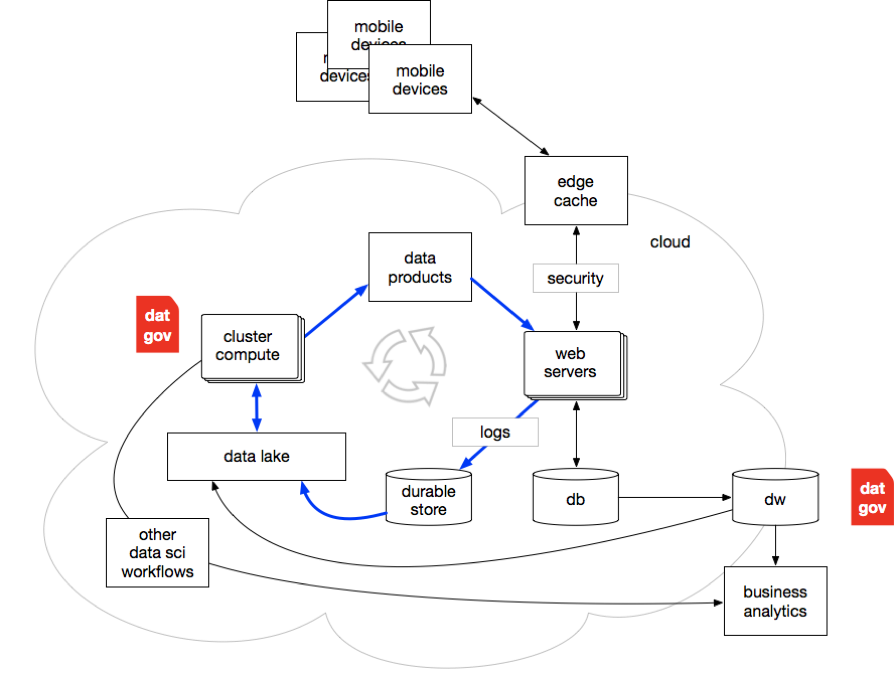
Cloud evolves. E-commerce becomes ginormous. Now almost everyone gets a smartphone. That log data we mentioned earlier now accounts for most of the data in the world. Data Science gets its own tech conference.
Data coming from machines tends to land (aka, data at rest) in durable stores such as Amazon S3, then gets consumed by Hadoop, Spark, etc. Somehow, the gravity of the data has a geological effect that forms data lakes.
Also, data science workflows begin to create feedback loops from the big data side of the illo above over to the DW side. That would’ve been heresy in earlier years. DG emerges for the big data side of the world, e.g., the Alation launch in 2012.
In short, the virtuous cycle is growing. We keep feeding the monster data. We find ways to improve machine learning so that it requires orders of magnitude more data, e.g., deep learning with neural networks.
Fun fact: Satyen Sangani and I met at an iconic, Seattle-based coffeehouse chain in Mountain View following a big data meetup in 2012, where he sketched ideas about how to handle data governance for big data tooling – starting with data catalog to track datasets and their provenance – on the back of a proverbial napkin. Wish I’d kept his napkin, but it probably would have seemed creepy. I visited Satyen a few months later at the new Alation office in Palo Alto, and they were already landing large banks as customers.
2020s
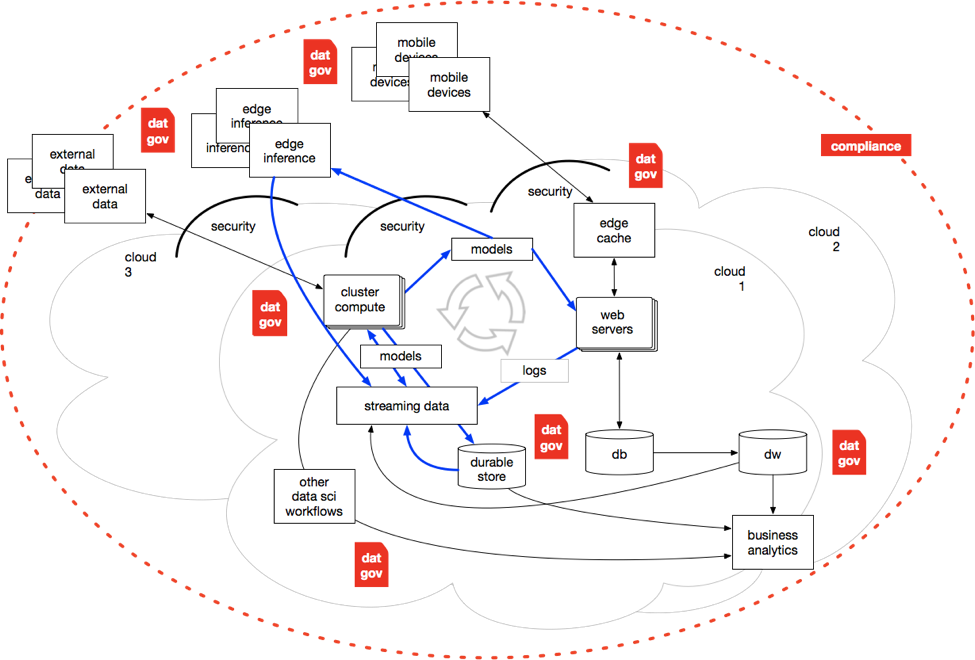
In other words, looking ahead from the point where we are now. It’s a multi-cloud world. It’s a hybrid-cloud world. There are many more mobile devices. However, there’s also an enormous tsunami of edge inference devices getting deployed. There are data APIs, various SaaS services, partnering, etc. All of which pose potential issues regarding governance and compliance.
Security is no longer located on the perimeter of an organization's networked assets. Instead, much of the intelligence about security has pushed out to a new generation of edge caches (using HSTS for MITM, DDoS). Architectural changes follow such as JAMstack and an overall turn toward “serverless” as a pattern for the second decade of cloud computing.
The virtuous cycle is growing and becoming faster. Streaming data and pub/sub architectures push data through Kafka, Pulsar, etc., in lieu of simply landing in a data lake. Newer work in machine learning (e.g., reinforcement learning) requires orders of magnitude more data and needs it to be streaming.
There are models everywhere. Models get used for e-commerce, but now for many other use cases. They get embedded in low-power devices, sometimes they get even used for data management. Now there are calls for model governance.
The stakes of the game have changed. Nation states watch their polity get undermined due to problems with data privacy and system misuses of data by bad actors. Billions of people have become victims of data breaches. Hacking is really not funny anymore. Data is weaponized.
A ginormous ring of compliance circles all of the above. GDPR (General Data Protection Regulation) has happened in the EU, but it pertains to any EU data used anywhere in the world. California followed within months by enacting CCPA (California Consumer Privacy Act) and other US states follow suit. In other words, GDPR-ish is becoming a done deal.
There are DG point solutions, although not much which connects the pieces. Balkanized might be a good descriptor. Larger vendors are starting to talk about a new kind of “fabric” that allows the same DG policies and processes to be applied across multi-cloud, hybrid cloud, on-prem, etc., to reconcile the various point solutions into a more pervasive approach. Frankly, that makes sense, if implemented well.
Fun fact: here’s where we all stand, right now. Together. Arguably, somewhat bewildered and perhaps a bit gunshy. Booyah!
Disconnects, in a nutshell
My read of that narrative arc is that some truly weird tensions showed up circa 2001:
- Arguably, it’s the heyday of DW+BI
- Agile Manifesto get published
- A generation of developers equates “database” with “relational”, with a belief that legibility of systems = legibility of the data within those systems (hint: nope)
- Even so, the newly emerging tech unicorns collectively make a sudden turn toward NoSQL, in reaction to RDBMS pricing
- Machine learning starts to become a large commercial endeavor, albeit DG solutions don’t account for ethics, bias, privacy, security, etc., in the context of ML
- Tech unicorns start to “move fast and break things” without paying sufficient attention to DG
By a show of hands, how many times does the term “data” get used in the Agile Manifesto? 5 times? 3 times? Once? Zero? If you answered “Zero” you win! Sorry, there is no data in agile.
Taking all of those factors into consideration, frankly, they don’t reconcile. It’s a mess. A very big mess since circa 2001, and now becoming quite a dangerous mess. To wit, the gist of the problem in my read of this history is that:
- A generation of mainstream developers was taught that “coding is imminenty, data is secondary”
- Meanwhile, the tech giants with first-mover advantage scrambled toward “learning is eminent, data is a competitive differentiator”
Please think about the tension between those two statements. If your organization is leaning toward the former, please rethink your situation.
Two decades later, we’re still mostly stuck while the landscape evolves to become even more complex due to edge inference, streaming data, multi-cloud, more security issues, etc. Fortunately, there’s a new C-level role called Chief Data Officer (CDO) which will magically solve these problems!

Wow, that’s a bunch to handle, Chief Data Officer! Please let me be the first to congratulate you on your new role. There are so many opportunities in which to move the needle.
Speaking of magic, I’ll just set this here, under the subheading of “Make the Quadrant Magic Again” (MQMA).
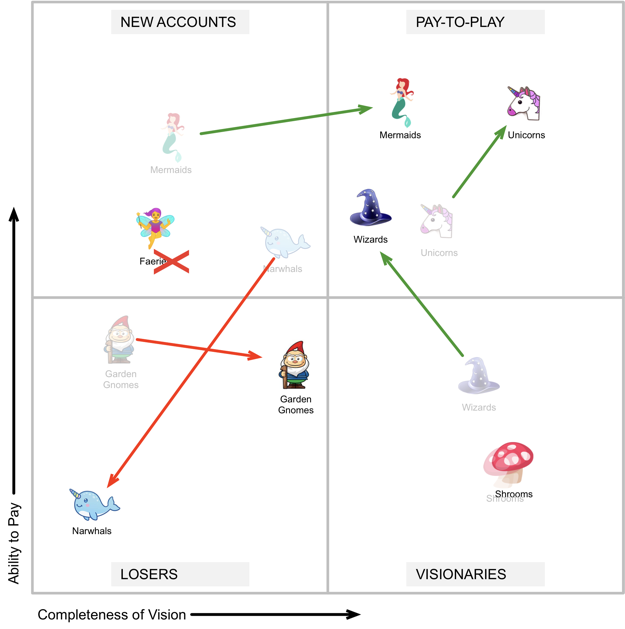
Near-term outlook
Let’s take a quick look at what resources are available now, and what near-term trends are emerging.
Vendor Landscape
The big fish – IBM, SAS, Informatica, SAP, etc. – have mature offerings, plus there are several tech ventures now in this space. I’ve been collecting info about ventures in this space into a spreadsheet, provided online as a resource. Note that the numbers are quoted from Crunchbase and may have some latency – some vendors have mentioned the numbers were deflated. Let me know about comments, corrections, suggestions, or anything else via @pacoid public timeline on Twitter.
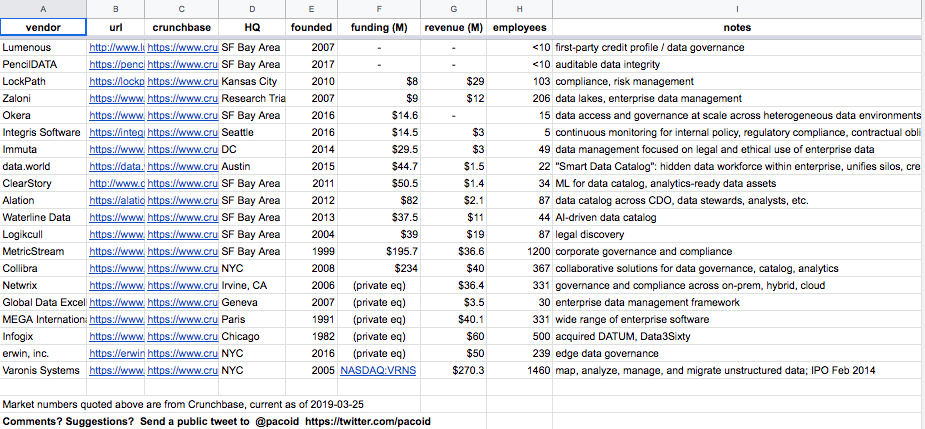
A quick tour through that vendor list shows a mix of early-stage, growth-stage, several firms taken by private equity, even a public listing – Varonis was the first tech IPO of 2014.
A quick tour through that vendor list shows a mix of early-stage, growth-stage, several firms taken by private equity, even a public listing – Varonis was the first tech IPO of 2014.
Note that our intention for presenting this material at Strata Data Conference was to attempt to prompt the vendors in the space to propose their own talks. I’m glad to report that our first presentation had much of the desired effect: we’re now looking toward a DG track at Strata, where 3-4 of these vendors are regularly among the conference sponsors. What was particularly interesting to me were conversations from vendors that aren’t identified strongly with DG solutions; however, their customer use cases demand strong DG needs. These firms want to include customer case studies in the mix, which is outstanding.
Open Source, Open Standards
A variety of open-source projects and emerging open standards addresses DG needs.
The Egeria project provides an enterprise catalog of data resources. Some of its top-selling points include:
- Provides open APIs, types, and interchange protocols.
- Allows metadata repositories to share and exchange.
- Adds governance, discovery, and access frameworks for automating the collection, management, and use of metadata.
- Validates products for conformance.
See also the paper “The Case for Open Metadata” by Mandy Chessell (2017–04–21) at IBM UK for compelling perspectives about open metadata.
Apache Atlas is a Hadoop-ish native reference implementation for Egeria. Apache NiFi also touches on some DG concerns.
Marquez is a project sponsored by WeWork and Stitch Fix to “collect, aggregate, and visualize a data ecosystem’s metadata” which sounds roughly akin to some aspects of Egeria. Perhaps there’s common ground emerging there?
WhereHows is a DG project from LinkedIn, focused on big data. Recently there was news from Uber about their Databook project that seems to have had inspiration from WhereHows.
W3C has the PROV family of standards “to enable the inter-operable interchange of provenance information in heterogeneous environments such as the Web”, along with an implementation in Python, plus the Open Provenance related research at King’s College London.
With a hat tip to Kim Valentine at NOAA, there’s a new Federal Data Strategy afoot in the US, which needs your input. Now’s the time to get in on the ground floor of how to leverage data as a strategic asset in the US.
Does machine learning change priorities?
The explosion of ML use cases and subsequent demands for data to train and test models poses new challenges:
- The need for reproducibility in analytics workflows becomes more acute.
- Model interpretability is hard since the word “interpret” has different meanings for legal, medical, journalism, finance, etc.
- BoD and exec staff are challenged by probabilistic systems and the unbundling of decision-making.
- ML tends to generalize from data, so we no longer assume 100% correctness, 100% privacy, 100% security, etc., and instead must recognize and own the outcomes.
- There’s now more focus on model governance – are models proxies for the data, and therefore a better focus for DG?
I won’t pretend to have the answers here. I barely understand the general outline of the initial questions – which circles back to my recent experiences asking DG experts.
One use case I believe is an excellent illustration of the near-term outlook is the Big Data Spain 2018 talk “Data Privacy @Spotify” by Irene Gonzálvez , product manager at Spotify in Stockholm.
I was lucky to get to talk with Irene at length, and came away with the distinct impressions that (1) those folks at Spotify are quite brilliant; and (2) perhaps GDPR wasn’t so bad after all. Her talk focuses on “Padlock”, which is a global key-management system at Spotify that also handles user-consents. In other words, data can only be persisted if it is first encrypted. That reduces the risks of data leaks; for example, an attacker might steal data, but it’ll be encrypted.
Moreover, one team manages the entire lifecycle for all customer data; other use cases within Spotify must request keys, per user, before they can use that data. Then when a customer requests the “right to be forgotten” per the GDPR requirements, compliance is simple: remove their key from Padlock.
Another great resource is a recent O’Reilly Data Show podcast interview “How machine learning impacts information security” with Andrew Burt from Immuta. This reviews a recent white paper that is highly recommended and addresses how privacy and security are converging, and how we’re going to have less source code and more source data.
Effective data governance will require much rethinking of the problems at hand. My hunch is that firms such as Spotify and Immuta (and many others!) are pointing out the shape of our collective near-term future. There are ways to adapt, even within a complex landscape of risks, edge cases, compliance, and other factors.
If you’d like to check out my whole talk, see the slides at https://derwen.ai/s/6fqt – and a video should be online (albeit behind the O’Reilly Media paywall) within a few weeks.
Kudos to Mark Madsen and Val Bercovici for guidance, and especially to Ben Lorica for twisting my arm to do this.

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.