Tensorflow, PyTorch or Keras for Deep Learning
Dr J Rogel-Salazar2022-01-18 | 13 min read
Machine learning provides us with ways to create data-powered systems that learn and enhance themselves, without being specifically programmed for the task at hand. As machine learning algorithms go, there is one class that has captured the imagination of many of us: deep learning. Surely you have heard of many fantastic applications where deep learning is being employed. For example, take the auto industry, where self-driving cars are powered by convolutional neural networks, or look at how recurrent neural networks are used for language translation and understanding. It is also worth mentioning the many different applications of neural networks in medical image recognition.
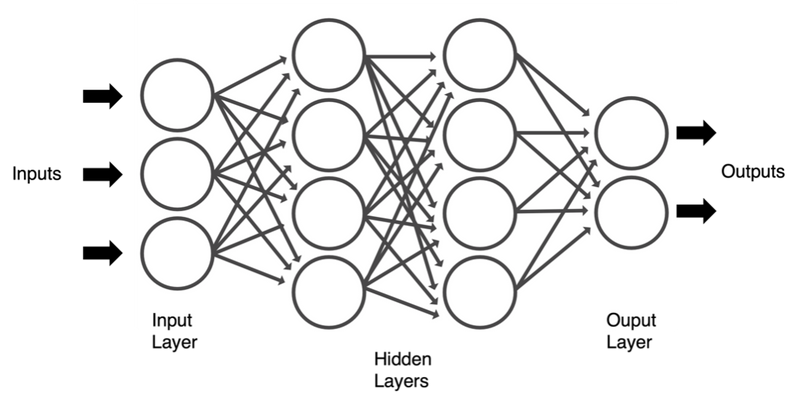
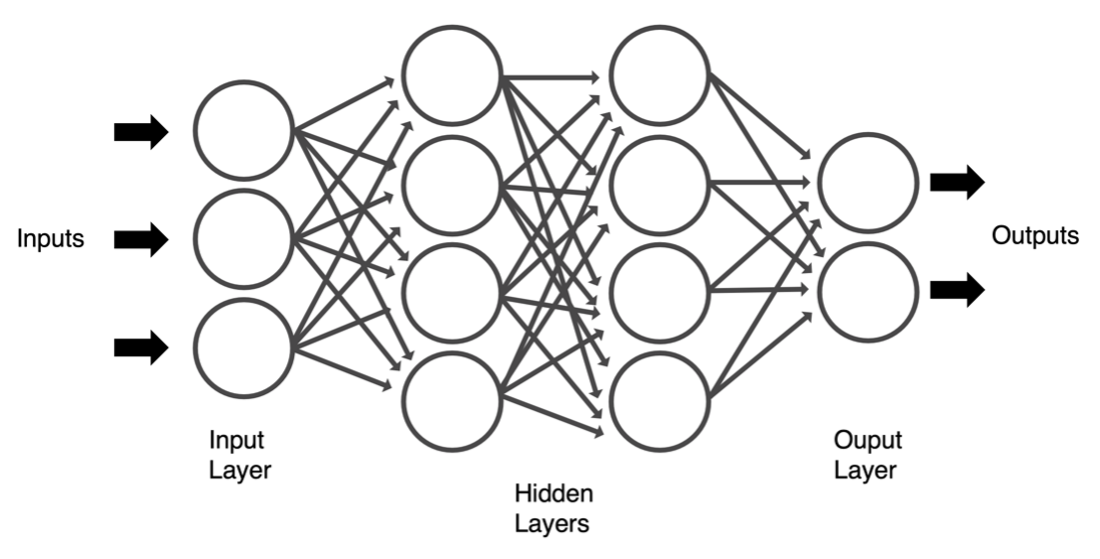
Deep learning can be considered one of the pillars of artificial intelligence and it takes inspiration from how neurons communicate with one another in the brain. Artificial neural networks (neural nets for short) are usually organised in layers; each layer is made up of several interconnected nodes that perform a transformation on the input they receive. See the diagram shown below. The transformation is referred to as the activation function and its output is directly fed to the next layer of neighboring neurons. The first layer in a network is called the input layer, and the last one is the output layer. The layers sandwiched between the input and output ones are called hidden layers, and in principle, we can have any number of them. The use of the adjective “deep” in deep learning refers to a large number of hidden layers in a neural network architecture. In a previous blog entry, we talked about how the computational tasks required in a deep neural network benefit from the use of GPUs. This is especially important as the number of parameters in our network grows, possibly into the tens of billions.
It is possible to write your own code to implement a neural network architecture that can approximate any function using a single hidden layer. As we add more layers we are able to create systems that learn complex representations by performing automatic feature engineering. I have addressed this subject as an introduction to neural networks in my book “Advanced Data Science and Analytics with Python”. Further to that, I highly recommend reading a recent post on this blog about deep learning and neural networks. Although this may be a very enlightening exercise, and it will give you an in-depth understanding of how neural networks work, you will also need to familiarise yourself with a number of frameworks if you are looking to build efficient implementations for sophisticated applications. Some examples of these frameworks include TensorFlow, PyTorch, Caffe, Keras, and MXNet. In this post, we are concerned with covering three of the main frameworks for deep learning, namely, TensorFlow, PyTorch, and Keras. We will look at their origins, pros and cons, and what you should consider before selecting one of them for deep learning tasks.
Deep Learning Frameworks: An Overview
TensorFlow
TensorFlow is one of the best-known deep learning frameworks out there. It started life as an internal project at Google Brain to help improve some of Google’s services such as Gmail, Photos, and the ubiquitous Google search engine. It was made public in late 2015, but it was not until 2017 that the first stable version (1.0.0) was released. Further improvements have given us TensorFlow 2.0, released in September 2019. The framework is available as an open-source project under the Apache License 2.0, and according to the TensorFlow Dev Summit 2020 keynote, the framework is reported to have been downloaded 76,000,000 times with more than 2,400 people contributing to its development. The name of this popular deep learning framework comes from the tensors used to perform operations and manipulations in a neural network. In this case, a tensor is effectively a multidimensional data array that “flows” through the layers of a neural net.
One of the most important features of TensorFlow is the abstraction that developers can achieve with it. This means that instead of dealing with low-level details of the operations required to traverse a neural network, a machine learning developer focuses on the higher-level logic of the application. This is achieved with the help of a dataflow graph that describes how a tensor moves through the series of layers and nodes in the neural net. In fairness, the APIs offered by TensorFlow are not only high-level, but also allow for some low-level operations. Furthermore, there are APIs that support Python, JavaScript, C++, and Java. On top of that, there are also some third-party language binding packages for C#, Haskell, Julia, R, Matlab, Scala, and others. Developers are also able to use Keras to create their own machine learning models. More on that later.
A further advantage of using TensorFlow is the availability of Tensor Processing Units or TPUs by Google. These are application-specific integrated circuits that are specifically tailored for use with TensorFlow for machine learning. As you can imagine, Google is a heavy user of TensorFlow. For instance, take a look at TF-Ranking, a library to develop learning-to-rank models. Companies such as GE Healthcare have used TensorFlow for brain anatomy identification during MRI scans; Spotify uses it to improve music recommendations for their users. Other use-cases are listed on the TensorFlow homepage.
PyTorch
PyTorch does not hide the fact that Python is at the centre of its development and design principles. PyTorch is also an open-source project (BSD License) that builds upon a few projects, primarily the now deprecated Lua Torch, a scientific computing framework now superseded by PyTorch itself, and the automatic differentiation libraries Chainer and HIPS autograd. Spearheaded by Meta’s research (formerly Facebook), PyTorch lets users create systems for computer vision, conversational AI, and personalisation. Version 1.0 was released in 2018 and version 1.10 in October 2021, the latter supports CUDA graph APIs among other improvements.
Given its Python credentials, PyTorch works with NumPy tensor-like objects for computation. Some developers consider it to be more “pythonic” than others. In any case, PyTorch is a very flexible framework: Although it relies on a graph to define the logic of a neural net architecture, we do not need to define it ahead of computation. Instead, we can add components to the graph in a dynamic fashion and independently from each other. This also brings advantages in the testing and debugging phases of our code.
Compared to TensorFlow, PyTorch has managed to build a great number of supporters thanks to its dynamic graph approach and flexibility for debugging and testing code. In response, TensorFlow has recently introduced an “eager execution” mode along the lines of PyTorch. Some popular use cases based on PyTorch include powering video-on-demand requirements at Tubi, training of self-driving cars at Lyft, or Disney’s animated character recognition efforts.
Keras
Keras is another important deep learning framework that is worth considering. Not only is it also based in Python like PyTorch, but it also has a high-level neural net API that has been adopted by the likes of TensorFlow to create new architectures. It is an open-source framework offered under an MIT License. It also runs on top of Aesara (the successor of Theano) and CNTK. I think of Keras as having the best of both worlds, and this is the main reason I chose this framework as the main centrepiece in the deep learning chapter in “Advanced Data Science and Analytics with Python”. It combines the readability and user-friendliness of Python with rapid prototyping and experimentation, making it a real contender in the deep learning space.
Keras was first developed as part of the Open-ended Neuro-Electronic Intelligent Robot Operating System (ONEIROS) research project. The acronym makes reference to the mythological Greek primordial deities known as Onieiroi. The name Keras comes from the Greek for “horn,” a further reference to Greek mythology, in this case alluding to the gates made from horn through which true dreams come from. Keras relies on a model that lets us add and remove layers from a neural net, enabling us to build both simple and complicated architectures in a sequential manner via its sequential API. Should we require models with various inputs and outputs, Keras also comes with a functional API. This lets us define complex models such as multi-output models, directed acyclic graphs, or models with shared layers.
Keras is used in a variety of tasks from predicting pneumonia to detecting malaria. It is also widely used in combination with TensorFlow by the likes of CERN in the Large Hadron Collider, or in the high-end computing capability within NASA.
Choosing a Framework for Deep Learning
We have addressed some of the aspects that you need to consider when choosing a machine learning framework. We stand behind the three aspects addressed in the post, namely:
- Evaluating your needs
- Parameter optimisation
- Scaling, training, and deployment
We highly recommend looking at that earlier post for further information in these areas. In this post, we concentrate on the pros and cons of the three deep learning frameworks. This, together with the three aspects above, should be a good start to choose among these three excellent options.
TensorFlow
Pros
- Great support for computational graphs, both for computation and visualisations (via TensorBoard)
- Support for Keras
- Library management supported by Google with frequent updates and releases
- Highly parallel pipelines with great scalability
- Availability of TPUs
- Able to use a debugging method for debugging code
Cons
- Steep learning curve due to low-level APIs
- Library management supported by Google with frequent updates and releases. We list this also as a pro, however sometimes the documentation for new releases may be a bit stale.
- The code can be a bit cluttered
- TPUs usage only allows the execution of a model, not training
- Supports only NVIDIA for GPU acceleration. It also only supports Python for GPU programming
- Limitations under Windows OS
PyTorch
Pros
- Easy to learn
- Dynamic graph logic supporting eager execution
- Developed natively in Python, making development very “pythonic”
- Support for GPU and CPU
- Support for distributed training
Cons
- API server needed for production
- Training process visualisation via Visdom is limited
- Currently not as popular as TensorFlow, although PyTorch continues to grow
Keras
Pros
- Excellent high-level API
- Seamless integration with TensorFlow, Aesara/Theano and CNTK
- Easy to learn with a simple way to build new architectures
- Provides multiple pre-trained models
- Fast experimentation
Cons
- Best when working with small datasets
- Sometimes seen as a “frontend” framework and maybe slower for backend used (compared to TensorFlow)
Comparing Deep Learning Frameworks
Element | Tensorflow | PyTorch | Keras |
|---|---|---|---|
Interface | C++, Python, CUDA | Python, C/C++, Julia | Python |
Architecture | Difficult to use | Simple to use, less readable | Simple to use |
Performance | High performance, suitable for large datasets | High performance, suitable for large datasets | Best suited for smaller datasets |
Learning Curve | Steep | Gentle | Easy |
License | Apache 2.0 | BSD | MIT |
Debugging | Complex to debug | Good debugging capabilities | Simple architecture requires less debugging |
Community Support and Popularity | First | Third | Second |
Speed | Fast | Fast | Slow |
Visualization | Excellent | Limited | Depends on the backend |
Summary
The number of available frameworks for deep learning has been steadily growing. Depending on your needs and wants, there may be one that is best suited for you. There is no denying the fact that TensorFlow is more mature and suitable for high performance. Furthermore, its popularity means that there is a lot of support out there, not only from Google, but also from the community in general. PyTorch is a great framework that wears its pythonista badge with pride, offering flexibility and excellent debugging capabilities. Finally, Keras should be seen more as a TensorFlow companion than a true rival. If you are interested in taking your first steps in deep learning, I strongly recommend starting up with Keras. It has a very easy learning curve and once you are ready you may want to move to full TensorFlow when required or to PyTorch to exploit its pythonic capabilities.
Additional Resources
- Check out the Domino Weekly Demo

Dr Jesus Rogel-Salazar is a Research Associate in the Photonics Group in the Department of Physics at Imperial College London. He obtained his PhD in quantum atom optics at Imperial College in the group of Professor Geoff New and in collaboration with the Bose-Einstein Condensation Group in Oxford with Professor Keith Burnett. After completion of his doctorate in 2003, he took a posdoc in the Centre for Cold Matter at Imperial and moved on to the Department of Mathematics in the Applied Analysis and Computation Group with Professor Jeff Cash.
SHARE

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.