Max Shron, the head of data science at Warby Parker, delivered a presentation on stakeholder-driven data science at a Data Science Popup. This blog post provides a session summary, a video of the entire session, and a video transcript of the presentation. If you are interested in attending a future Data Science Popup, the next event is November 14th in Chicago.
Session Summary
In this Data Science Popup Session, Max Shron, the head of data science at Warby Parker, delves into stakeholder-driven data science. His approach enables his data science team to work on the right kinds of things, deliver as much value as possible, and be seen as a driver of value across the company. Shron envisions a world where companies spend the same amount of money on data science that they spend on other major parts of their organizations. He advocates that in order to make this happen, data science work should do “the most good for people that we work with” and consider questions like “how do we make sure we build things of value? how do we make sure that a decade from now, data science as a whole, has the kind of mind share today that you get from technology?”
A few key highlights from the session include
- stakeholder-driven data science begins with data scientists spending more time listening and talking to stakeholders and less time doing data prep, math, and programming
- importance of creating mockups early on, to discover whether a deliverable will enable the stakeholder “to do something different”
- a recommended “priorities planning” framework that helps data science teams assess tradeoffs between “fits into stakeholder work flow”, “fidelity and accuracy”, “code quality and reproducibility”, “correct handling of uncertainty”, and “technically interesting”
- walk through of a retail site selection example that led the team to build two models, one at the city level that determines how many stores a city can hold and the second, at a census tract or site level, that considers “if I put a store here, how will it do?”
For more insights from the session, watch the video or read through the transcript.
Video Transcript of Presentation
Hi, everybody.
Thank you for sticking around this late in the day.
My name is Max Shron. I'm the head of data science at Warby Parker. This talk is going to be about how Warby Parker approaches the problem of working on the right kinds of things, and how do we make sure the data science team delivers as much value as possible. We want to make sure that the data science team doesn't end up a couple years from now being seen as a footnote in the company history. We want to be somebody who is really seen as a prime driver of value across the company.
If you aren't familiar with Warby Parker, we are a glasses company based in the US and Canada, originally online. We sell affordable glasses starting at $95, including lenses and frames shipped straight to people's houses. By comparison, if you buy a pair of glasses at a typical eyeglasses store or somewhere on a main street in the US, you'll usually find glasses-- a nice pair of good, quality glasses runs $400 or $500. We're selling them at a pretty steep discount. The company also is a B Corp. We have this stakeholder-driven value system. We're making sure that not only do we do well by our shareholders, but also well by our employees, the environment, our customers, and everybody who is the community that are involved in the work we do.
In addition to selling glasses, we also have a buy a pair, give a pair program, where we donate money to a handful of nonprofits in developing countries to train people to become opticians. They learn how to sell glasses themselves. We're able to really (rather than flooding the market with our own pairs of glasses) make sure that there's expertise around the world to deliver good quality glasses to everybody.
If you are not familiar with how a pair of glasses makes it on someone's face, this is a quick little diagram for this. Every pair of glasses somebody buys at Warby Parker starts with them having heard about it somewhere. They heard it from some advertising, or they heard from word of mouth of from a friend. Then they visit our website, or they visit one of our stores. We started off originally e-commerce. We're now majority retail. We're one of the most prominent examples of some of this new omnichannel-first kind of businesses.
Or they can have stuff sent to their home. We have a home try-on program where you can get five pairs of glasses sent to your house, try them on no cost, send them all back, and then we'll make you a pair and send you one that has the right prescription.
They go to a store, or they shop online. They look at a bunch of kinds of glasses. They have to pick a pair of glasses they actually want to get. They pick one, and then we have ourselves and through third party contractors for optical servicing. We have to cut out the glass and put in the frames to get people the glasses that they need to wear. That then gets shipped and makes it over to the customer, who hopefully is very happy and tells their friends, and we wind up with a virtuous cycle there.
Every step in this process, a lot of decisions had to get made. Every step in this process we had to decide “how do we run our marketing campaigns?”, “what should our website look like?”, “where should we put our stores?”, “how should we run our home try-on program?”, “what kinds of glasses should we have in our mix?”. We have to order glasses. It takes months to a year (sometimes plus) between when you design a pair of glasses… til they're actually on the shelf. How do we forecast the kinds of trends that are going to actually help us get ahead of that kind of thing? When we make our own glasses at our optical service labs, how do we decide where to put those labs?
Warby Parker has our own fully owned lab in Sloatsburg, New York, where we have to make an assembly line, have multiple shifts of workers, and all that kind of stuff. We have to then put those things on a truck or on an airplane and get them out and get them to customers. And then again, they have to be happy with it, and they're going to keep talking to us afterwards, hopefully, staying engaged.
Every one of these steps in the process, and others, have got whole teams at Warby Parker who are dedicated just to that. We have a supply chain team, whose only job really is to make sure that this part down here works well. And we have a merchandising planning team whose job basically is, among other things-- it's not their only job-- is to forecast inventory trends, design of a pair of glasses, and make sure that we have the right stuff in stock so customers really can get the things they want to get.
Across the whole company, we have, out of the several hundred people in our headquarters, about 30 of them are analysts of some kind. This does not include the data science team. And these are people who sit on those teams and do a lot of the day-to-day decision support that make these activities possible. The data science team is a centralized team, essentially an internal consulting group. Myself and a few of my colleagues came into Warby Parker from having had a small consulting shop. The perspective we bring to this, really, is that of a centralized consultancy trying to solve the problems that require more predictive analytics, more optimization, more machine learning, and more automation than you typically get in an analyst skill set.
I think-- just to turn this thing [slide projector] off for a second-- that the core thing we're trying to figure out is…. “how do we make sure we build things of value? How do we make sure that a decade from now, data science as a whole, has got the kind of mind share that today you get from technology?” I can see a world 10 years from now where most companies still only have two or three data scientists. I want to live in a world where, 10 years from now, companies spend the kind of money on data science that they spend on other major parts of their organization. So how do we make sure that we do the kind of work that actually delivers that value and don't get nerd sniped into the things that are maybe the most technically interesting, but not necessarily the things that are going to do the most good for the people that we work with?
My approach is something I like to call “stakeholder-driven data science”.
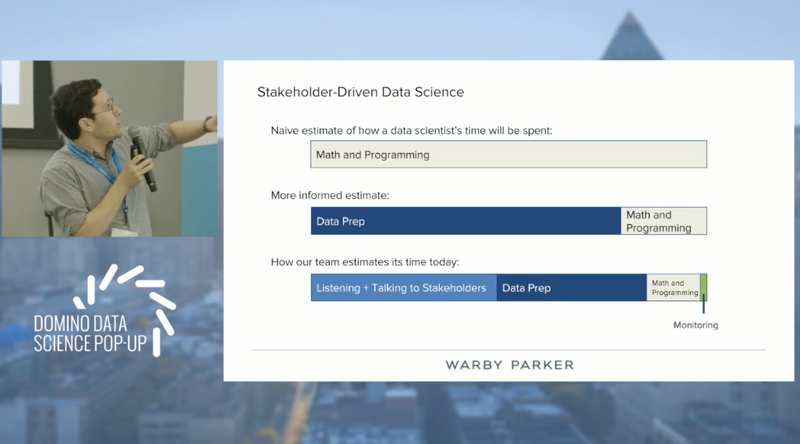
The way I think about this is, if you look at the top here [references the slide on the screen], so “what is the ‘naive estimate’ of how a data scientist thinks their time will be spent before they enter into the industry?” They assume it's all math and programming. We all know that actually a lot of that turns out to be data prep. But now, at this point, the place where we've ended up as a team, is realizing that something like a third of our time as a whole, is actually spent listening and talking to stakeholders across the company. Talking to the people who are the subject matter experts, who really are going to benefit from the work we do, and staying in contact with them the whole lifecycle of the work we're doing. Obviously, data prep still a core part of that. The math and programming isn't going to go away. That's the thing that really is the bit that delivers the value. And then the last thing I want to tack on here is monitoring. So in addition to all of this work, we have to make sure the thing we build stays useful to people, right? Stays actually relevant the whole way through.
I'm going to talk through a bit of the process that we use as a team to really make sure that we're nailing the first bit. And I'm going to talk through two quick examples of products we've done and kind of how they fit together.
First example, retail site selection. Warby Parker now has 50 stores-- actually, 52 as of today. We're opening 20 more this year, so we're growing very quickly. A core question is, do you open your first store in New York City? Or your first store in Cleveland? There's a clear trade-off there, as you're growing a company, where you decide to actually put your stores. They're coming into Warby Parker. When I got there, there already had been a data science team. They already had done some work. There was a pretty reasonable regression model that got to the first bit of this. But the question that we were tasked with was, “how can we build something even more helpful for us that understands more of cannibalization?”… more about how the different parts of the business fit together, and do some forecasting that is really going be helpful for the retail team.
The way that we approach a problem like this is, first and foremost, we start with mockups. We start with things that have no real analytical content except to verify that if we put this deliverable in front of a decision maker, could they actually do something different. I think this morning Jonathan Roberts talked about the importance of getting the right question. I absolutely agree. Then, with the direct question, the next question is, “what can I give you that will actually help you answer that question? Before I think at all about what the math or the programming looks like to deliver that”.
And so this first stage of this project, what we did is we actually put together-- so this map here [points to the screen], this is just a thing I pulled off of Google Images. This is a choropleth. I think they're showing the 311 calls in the city. But my instinct originally was to put a map in front of our retail team to say, “here's going to be a map of where to put stores. That's going to help you, right?” And they actually said no, that doesn't help them. Because it turns out they have two major decisions they have to make. One is which cities to focus on. And the second is, which sites, when they've been handed a site by a real estate consultant, do they want to go with? They don't get to look at a map and pick spots to put stores. They have to evaluate them as they come in off a stack.
We ended up realizing we needed to make two different models. One model which was at the city level, how many stores can the city hold. And a separate model where that was at the time the census tract or at the site level that says, “if I put a store here, how will it do? How many sales do we think it will actually get?” If you think about the priorities that we have to go through when we're deciding among a bunch of different competing projects, competing ways of attacking this thing, we really have to have some kind of priority…it tells us among the things we can do, what goes higher than the others. And this, in some sense, is the key slide for this presentation.
We realize that making something that fits into the workflow of our decision makers is the number one thing. More important, actually, than making an accurate model. And if I can spend an extra week building something that directly, just fits like a glove, into what they're already doing, and they know they're going to use it, that week is better spent than a week improving the model accuracy.
[Gestures to the slide] We fit into the workflow, fidelity and accuracy, after that, code quality and reproducibility. We don't want to keep working on the same thing over and over again, we want to build something and move on. We want to make sure that when the data changes upstream, we don't wind up having to go back and fix it. At the very least, it'll throw an error. It's not going to give somebody the incorrect result. So we spend a lot of time putting the guardrails on our projects, making sure we've really specified all of the invariance of the data sets that we expect are going to come through, so that the data that comes that flows through hopefully doesn't catch us off guard when it changes.
After that, after this code quality, is correct handling of uncertainty. This is now the priority that my inner stats nerd wishes this was number one. Having really accurate, great coverage on my confidence intervals, my credibility intervals, is the thing that I know that I do care about a lot. But I have to recognize that takes lower precedence than having an accurate model that fits into the workflow people have and that is reproducible.
And then lastly, the things that are technically interesting. It's on there [the slide] because it's a value. It is a priority, to do things that are: it's good for retention, it's good for finding new solutions, to do stuff that is technically innovative. But it's still lower priority than the other bits, for better or worse.
And so an example here for this project I mentioned about deciding where to put stores. Getting a sales forecast per site and city trade-offs was more important than maps, right? Even though the maps thing, in some sense, was the more elegant solution to the problem. Obviously, having good error is important. If we're going to say the store will make x millions of dollars, it should generally do that well. We want to make sure that our entire workflow is reproducible. We're not super cool in this. We're using literally makefiles, they work pretty well. We do spend some time validating our error bars. And we have tried some hierarchical approaches to this based on the demographics and various things. They're worth it, but ultimately, in this case I think correctly, abandoned those routes in favor of working more time on the other bits so we could get through this product to work on other things.
And just to give you a quick sense of what we ended up at. So we ended up building a model that says market penetration, for a given census tract, is going to be some function of distance. And that distance, that function, is going to change based on the demographics and other things about that census tract. If you think about what this looks like as a causal model, you can imagine that if I have a drug I want to give bunch of patients. I think that the result is dose dependent, where I give you a higher dose, I should expect a higher response. And some patients are going to have a bigger response because they're younger, or their genetics, or whatever predispose them to being really susceptible. And in the same way here, we can say that some census tracts-- you can think of this as like a zip code-- some census tracts are really susceptible. If I put a store right next to them, I'm getting a lot of customers. And some census tracts, if I put a store right next to them, nobody will show up.
The challenge here is that we didn't put our stores at random around the country. We put our stores in places where we thought they would do well. So there's a selection bias problem. We didn't get this thing out at random. I would love to say that we did a really deep, thoughtful approach to understanding the causal relationship here. What it meant was we sort of drew a fence around our parameter space and said we only have support in a certain range. And if you ask me to put a store in a place that I don't have a lot of support on whose neighborhood around that store is really different than any place I put before, I should at least tell you I have no idea. And I should, at the very least, tell you this is a problem that is outside my own expertise. Use whatever other models you have, but don't rely on ours. I think you should recognize people will always interpret your models causally. And so it is up to you to make sure that you've done the work to not lead them astray.
Finally, this is an example of a cute little HipChat bot that I think-- HipChat has their website –
where you can say “hey, give me the weather in San Francisco”, and it spits it back. Unfortunately, I can't show you the actual screenshot of this on our side, but the way we ended up delivering the site selection model is as a HipChat bot. There's a HipChat room where our retail team says, “give us the sales forecast we think for a site at this address”. The bot looks up the address, looks it up in our model, spits out the result. And so they have, one, a really natural way to interact with it. It is very low friction. It doesn't require them to memorize a URL. And two, they have a history. They have a log. It's just built into the chat program. It always says, six months ago when you asked about the site, they can just go back up and look at it. And as the model evolves or things change, they're able to recognize the history of what it was they thought they were going to get back then, which we found really useful.
Just to give a sense then, quickly, of the lifecycle of a project like this, how the pieces fit together. We typically spend somewhere between one to three weeks at the start of a project early on in the planning phase. As I said, because we're the centralized team, we tend to work on projects that are a little more a few months at a time. At the beginning, people have to surface an idea. We're not the ones who come up with these ideas for these things, typically. Sometimes we are. But we have meetings with all of the directors on a regular basis, we hold office hours, we run an analyst guild so the analysts across the company can hear about new cool techniques and technologies, and they often surface ideas to us.
We then spend some time thinking out the business value for a project. We then do rapid iteration, sort of an agile up front, using fake data or using messy data. Just to say, “hey, can we align on exactly what this thing is going to look like before we go and do all the hard work of all the data cleaning? let's just quickly get on board with that.” Once we've got a good sense, we then write up a plan. We write using plain English five to seven pages that says, “here's why we're doing this. Here's what we think the value is. Here's roughly what the risks are, and what our plan is”. And we want everybody who's involved in this to say, “yes, I read that, I understand that. This is in language I can get, and I'm going to actually make that decision differently afterwards.”
The other part of this, which I'll talk about in a second, is since we do this upfront, we no longer run into the problem of having built something, and then we deliver it, only to find out that more work has to be done by another team that hadn't been planned for. We used to build things that occasionally we'd get to the end, and we had vague conversations with another team about taking the work and doing their half of the implementation of it. But then it turns out that they had forgotten to put it on the roadmap, or they thought it was interesting but didn't really plan for it. Now we're like, they signed off on this thing, and we're going to keep throwing it in their face until eventually, when it gets to their turn, they know to pick up that baton when it comes running.
Finally, then we do the part that's actually data science in the traditional sense….all of the EDA, engineering, modeling, et cetera. That can take anywhere from a few weeks to a few months or longer, depending on the project. And then finally, we deliver the code, or reports, or microservices, or whatever it is that is the outcome of the work we do.
We set up some kind of monitoring to make sure that when it falls over, as it inevitably will because the world is complicated, we at least get email about it. Then we have a quick retrospective, where we get all the people in the room, both on the technical side and non-technical side, and say, “did this do what you thought it would do? Are you satisfied?” I try to have one-on-one conversations with people that are not on our team just to really make sure that they feel comfortable giving feedback and that helps us iterate and improve this process. And it feels like it's kind of heavy weight. And it’s true that we have just recently brought in a project manager around our team to make sure this is helpful. But the weight of doing this, I think, is a lot less than the weight of spending months working on something which doesn't actually succeed.
A quick second example in our time remaining. This is a map of delivery time estimates across the United States, where the little red dot there is Sloatsburg, which is where our factory is. This comes straight from the US Postal Service. They claim that this dark blob here is a one day delivery time, that the lighter blue is two days, and the really light blue is three days. That's their claim as to how long it takes for things to get from point A to point B. That is a very particular estimate. It's a single estimated number. We know that it's not super accurate for ourselves.
We know we can get better estimates where we already have a location, because we can look at all of our own sending and seeing how it does. But the question that came to us was, “what if we wanted to put a new lab here, here, here, or here? Can we forecast what the delivery time is going to look like from that place to every other zip code in the country?” Because that's the input to a whole bunch of different kinds of models.
Actually, I'll just skip ahead to this for a second. Getting good estimates of delivery time feeds into deciding which lab to allocate an order to. Remember I said every pair of glasses is made basically custom, right? They have to actually take your prescription and cut out the lens and stick them in there. So we have to decide where to send that order to. We negotiate contracts with our carriers to say, “here's what you said you would give us, here's what we think actually you can deliver on. Can you help come meet us somewhere here on price to make that make sense?” Also the most strategic thing here, of just deciding where to allocate the millions of dollars it takes to open an optical lab, we better have really accurate estimates of how long it's going to take to get to customers so they don't end up getting unhappy with us and deciding that we're a terrible company.
So on this theme of iterating with fake data, the way that we started off getting alignment on this-- and this is step one. It went further beyond this [gesturing to the slide]. But, is just saying, “hey, here's a couple of outputs. Here's a few different things that some different kinds of models could tell you. Which of these outputs is most useful to you?” Ignore for a second how accurate it is. Let's just say it was accurate. So we have number A here. The letter A, which is the carrier style. Here's how many days we think it'll take to get there. Here's our best guess. Maybe if you're a statistician, some sort of maximize likelihood estimate, or the mean, or something along those lines.
Then we have the thing-- which occurs most readily to me-- is say, “hey, we'll do a confidence interval. We'll know for sure that it's going to come somewhere in this range.” But that doesn't actually help our decision makers. They don't need a confidence interval. They need to know the worst case scenario, it turns out.
So the thing that we ended up modeling for them is this tail probability that says, what's the, for example, 95th percentile. We're pretty sure that 19 times out of 20, it's going to get there within six days. That approach then lends itself to different kinds of thinking about the probability, thinking about how these things fit together, and trying to build something which actually fits in to each of these different goals. Because there's actually different teams that need each of these things. And so we wanted to make sure that the work we did fit the goals of each of these teams.
And that if I said, “hey, I'm going to make you a magic box, let's wave magic wand. A few months from now, you'll have a magic box that gives you a number. What should that number look like so that it is as useful to you as possible? And just to rehash back through on the priorities side, how the same priorities worked out here.” So, it turned out that to fit into their workflow, they really cared much more about tail probabilities than they cared about the overall distribution. I mean, we might still model distribution, but we should really make sure that our tail probability estimates are accurate.
We wanted to make sure we had some good coverage to say, 99 times out of 100, if I tell you this is the 95th percentile, I'm correct. Obviously, reproducibility again asserts all over the place. The data we get from carriers is not the start and end date. It's every single time they take a measurement. Somebody scans the bar code on the box, it creates a data point for us. So we had every single one of those events. We have to make sure that when the postal service decides to change how it encodes events-- which they do-- that we'll at least know that something's changed, and not accidentally start saying everything will show up in two days. Correctly handling uncertainty. We've been thinking about ways of modeling the cumulative distribution function directly, because that's the thing we really care about, is this percentile. There's some interesting Bayesian approaches to doing that, which we're probably, frankly, not going to do. But at least we should be aware of what they would look like.
And finally on the technically interesting side, I'm really interested in this cost-time trade-off. So when we're presenting this decision of allocating to an optimal lab, not every lab charges the same amount of money. And so, right now, we ad hocly decide what the trade-off looks like. I would love to run a really structured interview process to try to elicit a utility function from our executives about how they think about the trade-offs of these things. I don't know that there's going to be any value in that, so we haven't done it yet. But it's still in my mind of things to do. Even though it was literally one of the first things that occurred to us when we had this conversation, unfortunately, it ended up at the bottom of the stack of our priorities. Because we know that we can deliver a lot value with the other stuff first.
I'm going to just close by saying there is a-- can't remember who wrote this, it might have been Cal Newport…he said something like, the passion you get from a job comes from being good at it, and comes from being in an environment that is supportive, and in an environment that you like. More so than what you might think coming in, that your passion will come from whatever you thought your passion was. I have found that becoming passionate about delivering data science products back to stakeholders can be just as satisfying as getting the correct math for doing coverage on an interval. I think that a lot of people can have the same thing. And I think that if we do that, as a whole, we're going to wind up in a place where data science is a really respected, mature discipline that gets the attention and budget it deserves. So, thank you.
Domino Editorial Note: This transcript has been edited for readability.

Domino Data Lab empowers the largest AI-driven enterprises to build and operate AI at scale. Domino’s Enterprise AI Platform unifies the flexibility AI teams want with the visibility and control the enterprise requires. Domino enables a repeatable and agile ML lifecycle for faster, responsible AI impact with lower costs. With Domino, global enterprises can develop better medicines, grow more productive crops, develop more competitive products, and more. Founded in 2013, Domino is backed by Sequoia Capital, Coatue Management, NVIDIA, Snowflake, and other leading investors.



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.