This a guest post by Arnu Pretorius
For the sake of brevity, not all the relevant data and code are displayed in this post but can rather be found here.
Introduction
The Rugby World Cup (RWC) is here! With many fans around the world excited to see the action unfold over the next month and a half.
Before I go through the specifics, I would just like to mention that the initial idea was to simply get some relevant rugby data from the web, train a model using the data collected and then make predictions. Pretty simple, so let's get started!
Getting the Data
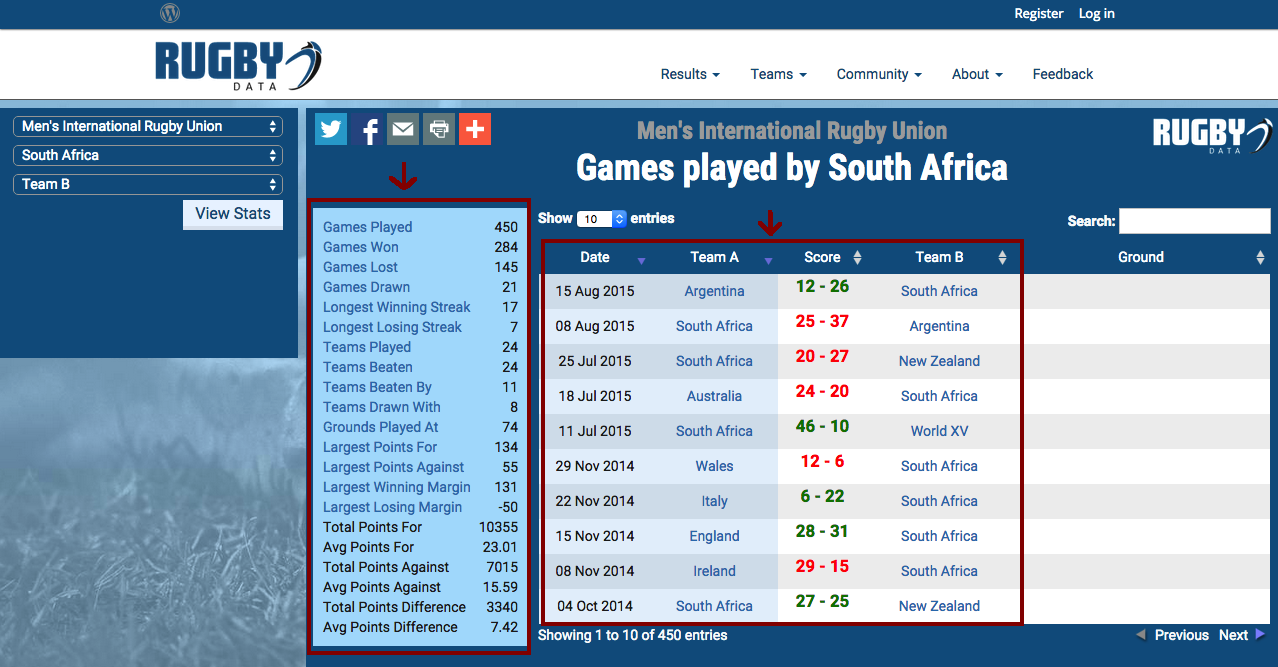
As with many machine learning undertakings, the first step was to collect the data. I found a good source of rugby data at rugbydata.com. For each of the 20 teams in the RWC I collected some general historical team statistics and past matches stretching back to the beginning of 2013 (shown below for South Africa).
Only the matches between teams that are actually going to compete in the tournament were kept. In addition, tied matches were discarded. The first reason for this is due to the fact that in rugby a tied match is a fairly rare occurrence. The second is that I was more concerned with predicting a win or a loss, the outcomes most fans care about, rather than also being able to predict match ties.
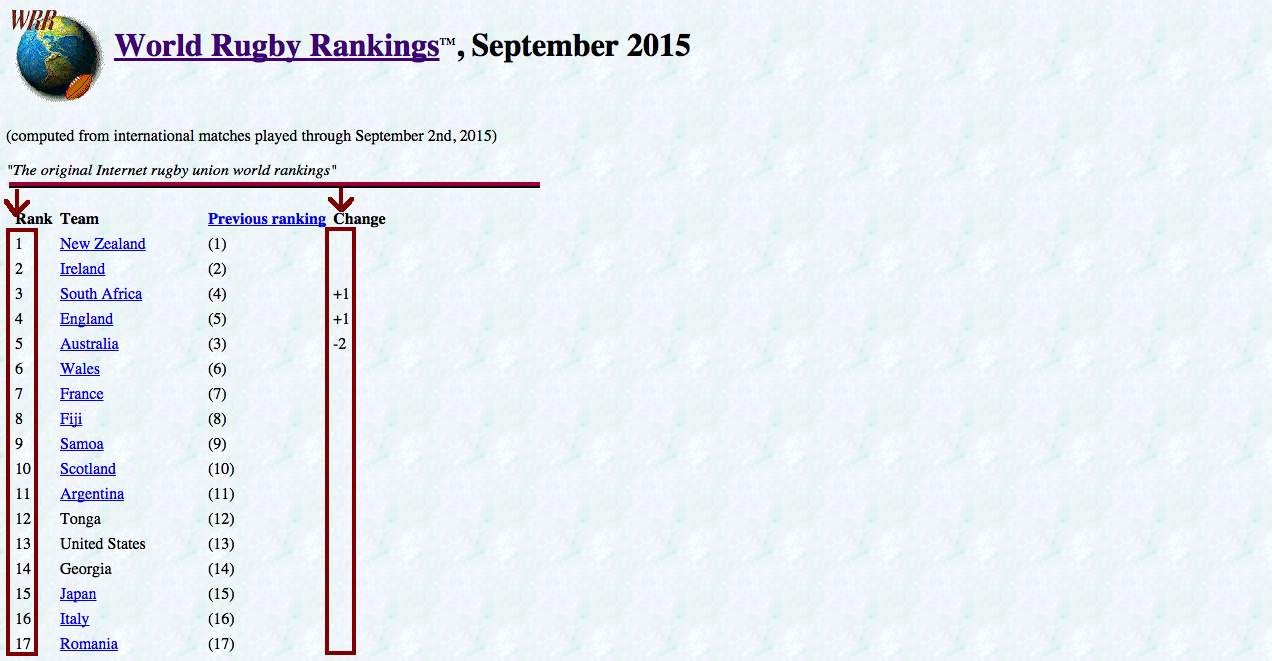
As another data source, I collected the rankings of each team as well as their recent change in rank from this site (shown below).
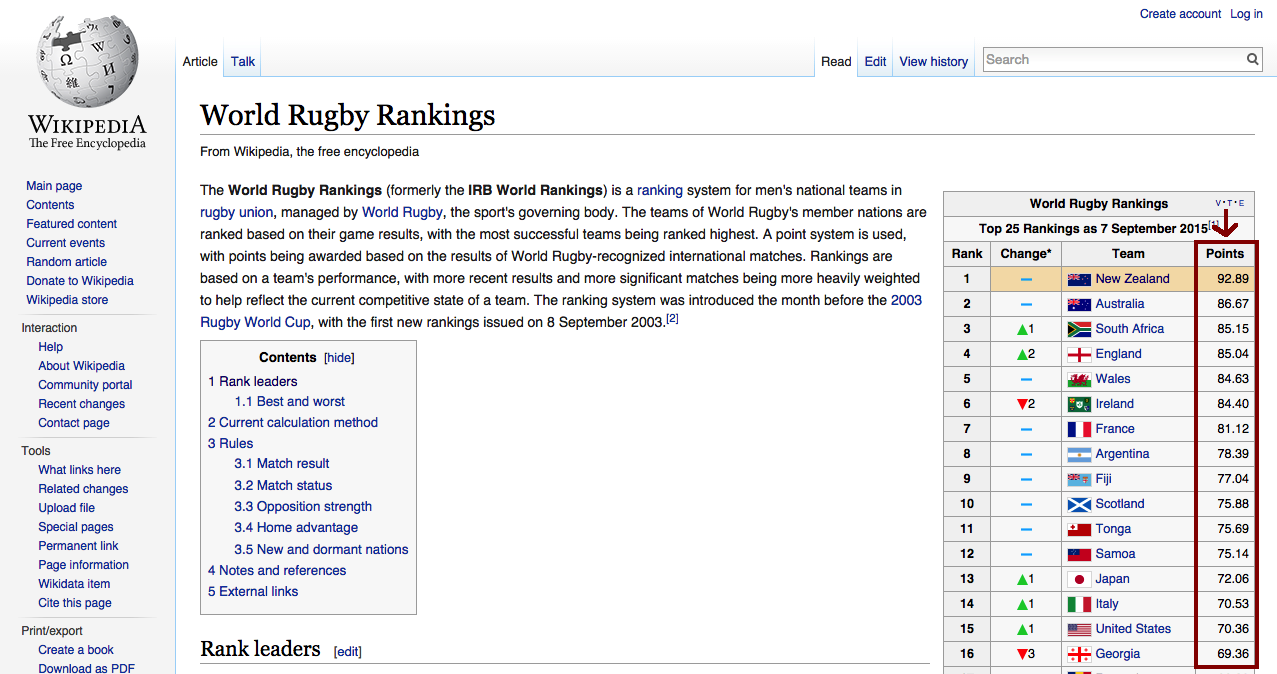
Finally, connected to team rankings are ranking points that I managed to find on a world rugby rankings Wikipedia page.
Since most of the data only reflect the current state of each team's historical performance and rank, weights were computed based on the date of each match (matches are treated as observations) in an attempt to adjust the data to exhibit a more accurate reflection of the past. The entire data collection, cleaning, and structuring were done with written in R.
Exploring the data
Now that the data was in the bag, it was time to go explore! As a quick overview of the data I looked at a heat map of the correlation between all the variables.
# load datadata <- readRDS("RWCData.rda")# Correlation heat map of the training datlibrary(ggplot2)library(reshape2)dataCor <- datadataCor <- cbind(as.numeric(data[,1]), as.numeric(data[,2]), as.numeric(data[,3]),as.numeric(data[,4]), as.numeric(data[,5]), data[,-c(1,2,3,4,5)])colnames(dataCor) <- colnames(data)title <- "Rugby training data correlation heat map"corp <- qplot(x=Var1, y=Var2, data=melt(cor(dataCor, use="p")), fill=value, geom="tile") +scale_fill_gradient2(limits=c(-1, 1))corp <- corp + theme(axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks=element_blank())corp <- corp + ggtitle(title)corp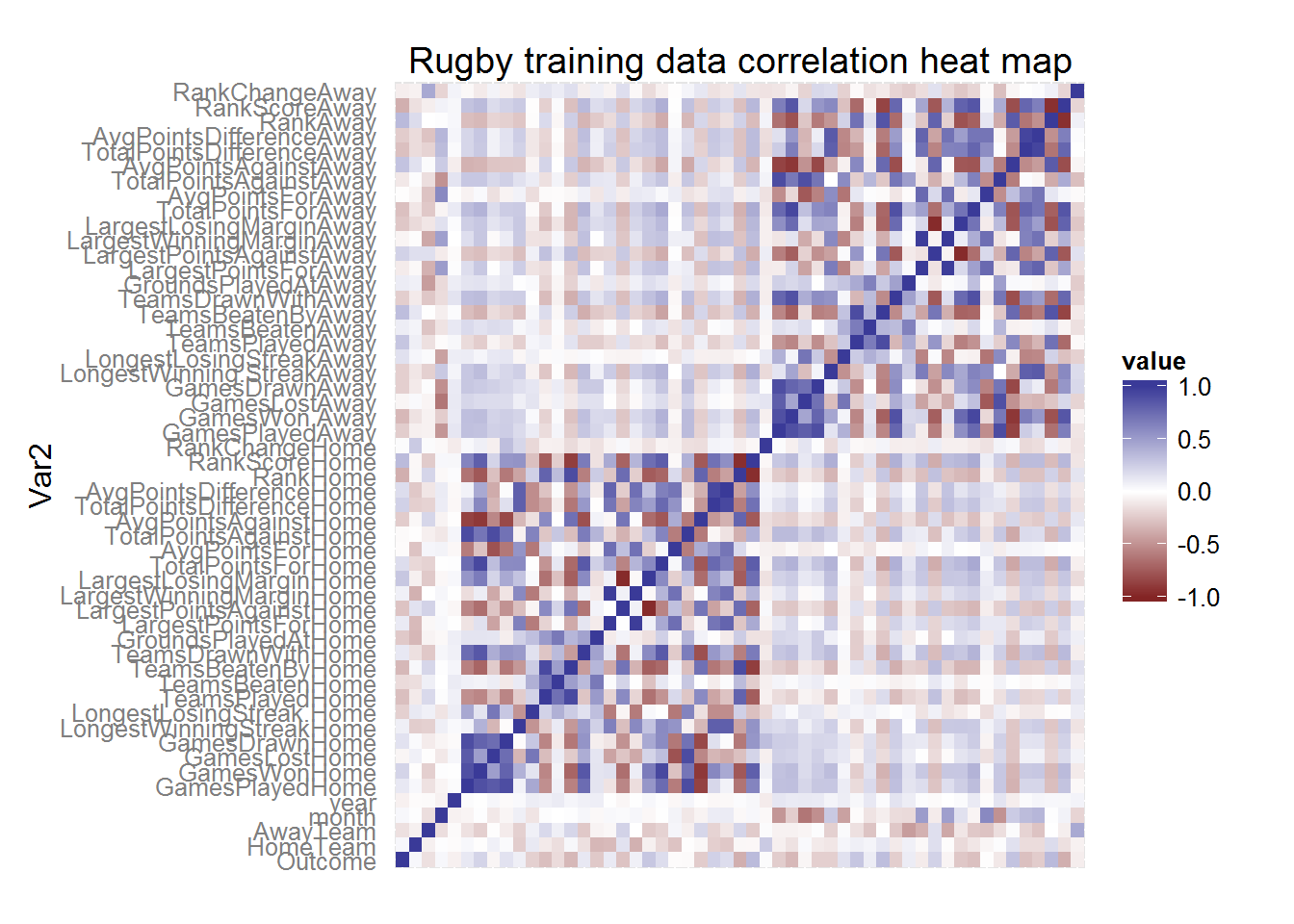
A dark blue square indicates a strong positive correlation between two variables and a dark red square a strong negative correlation. As I sort of expected many of the variables seemed to be correlated with each other (such as the average points scored against a team at home and the number of games the team lost at home). Nevertheless, in the first column of the heat map, I was able to find the degree of correlation between all the variables (indexed by the rows) with the outcome of the match. The rank of the home and away team seemed to be fairly correlated with the match outcome when compared to the other variables. So I took a closer look.
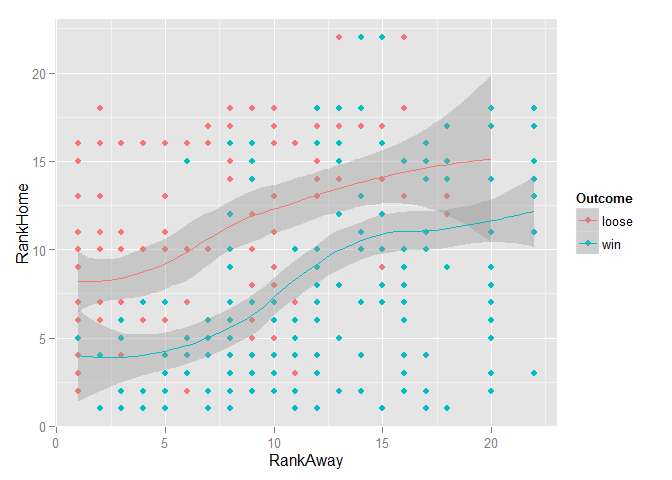
ggplot(data, aes(RankAway, RankHome, color=Outcome)) + geom_point() + geom_smooth()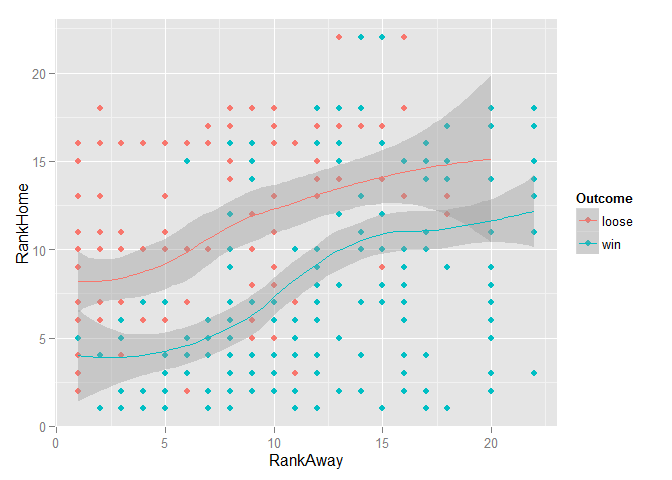
Since the Outcome variable was coded to indicate whether the home team won or lost, I could clearly see that more winning matches were associated with higher-ranked teams playing at home. After a little further exploration (not shown here), I had hope that at least some of the variables might have some discriminatory power when used in a model.
Model Selection
I started off by splitting the data into a training and test set. Since the aim is to predict matches happening in the world cup, which is taking place in the second half of 2015, I selected as my test set every second match from the start of 2015 until the most recent match. All the remaining matches were used for training.
# create training and test settestIndex <- seq(360,400,2)train <- data[-testIndex,]test <- data[testIndex,]Due to its general good performance, ease of training, and amenability for parallel processing, like many others I chose the Random Forest (RF) classifier as a good place to start. A Random Forest for classification is an ensemble of classification trees each built using a bootstrap sample of the observations and only allowing a random subset of variables for selection at each node split. The final classification takes the form of a majority vote. For a great introduction to classification trees and Random Forests take a look at these slides by Thomas Fuchs. In addition, I also investigated the performance of Oblique Random Forests (ORF).
Normally the classification trees used in Random Forests split the variable space using orthogonal (perpendicular to the variable axis) splits, whereas Oblique Random Forests use some linear combination of the variables for splitting. Oblique trees are better suited for splitting a space consisting of many correlated variables, therefore I thought the Oblique Random Forest might perform better on the rugby data. Furthermore, many different linear classifiers can be used to produce the linear combinations used for splitting. I ended up using Partial Least Squares (PLS).
The tuning parameter associated with the Random Forest and Oblique Random Forest is the size of the subset of randomly selected variables used at each node split. The following code sets up a tuning grid consisting of several different sizes of this subset and specifies the method used to train the model, in this case 5-fold cross-validation (CV).
# Train classifierslibrary(doParallel)cl <- makeCluster(8)registerDoParallel(cl)# Load librarieslibrary(caret)library(randomForest)# Model tuning gridsrfGrid <- expand.grid(mtry = c(1, 7, 14, 27, 40, 53))# Tune using 5-fold cross-validationfitControl <- trainControl(method = "cv", number = 5, repeats = 1)To train the models I used the train function from the classification and regression training (caret) package in R. This is an extremely powerful and handy package capable of performing many machine learning tasks from data pre-processing and splitting to model training, tuning and variable selection. To train a Random Forest set the method argument to "rf" and for an Oblique Random Forest with PLS node splits set it to "ORFpls". Below is the code for an RF using 1000 trees (with extra code bits to store the time it took to train the model).
# Random Forestsstart.time <- Sys.time()set.seed(2)rf <- train(x=train[,-1], y=train[,1], method="rf", ntree=200, trControl=fitControl, tuneGrid=rfGrid, importance=TRUE)end.time <- Sys.time()time.taken.rf <- end.time - start.timeModel | Training time--------------------- | -------------Random Forest | 14.32 secsOblique RF pls | 6.93 minsThe training time was 14.32 seconds for the RF and 6.93 minutes for the ORF, meaning that the ORF took roughly 29 times longer to train. This is because at each split for ORF a PLS model is fitted instead of a less computationally intense orthogonal split used in RF. The plot below shows the CV accuracy of each model for a different subset size of randomly selected variables as well as standard deviation bounds.
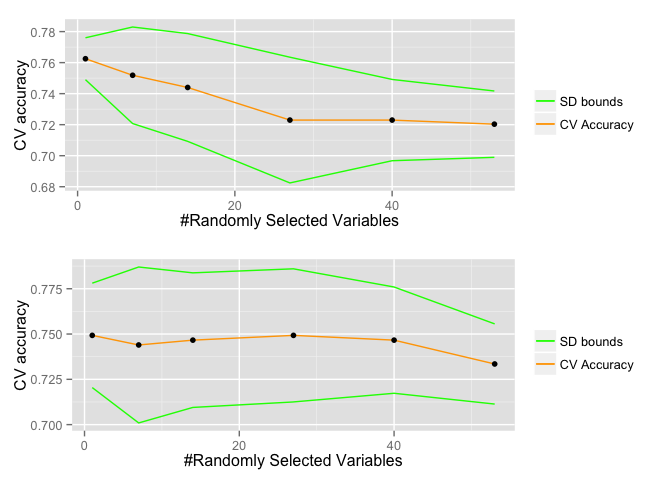
The optimal subset size for the RF was 1 and the ORF 1 with the RF outperforming the ORF when the subset sizes were optimal for each model. However, the accuracy computed in this way (only using the training data) is not a true reflection of the model's ability to generalize to unseen data. So to get a better idea of the performance of the models I plotted an ROC curve.
RF and ORF both produce posterior (after the data has been taken into account) probabilities for observations to belong to a certain class. In a binary case, such as whether a team is going to loose or win a match, a threshold can be set (say 0.5) and if the posterior probability is above this threshold we classify to the "win"" class, otherwise if it is below the threshold we classify to the "loose" class. The ROC curve shows the false positive rate (fraction of matches a team wins incorrectly classified as a loss) and true positive rate (fraction of matches a team won correctly classified as a win) for a sequence of thresholds from 0 to 1. Simply put, the classifier with a corresponding ROC curve that most closely hugs the top left corner of the plot as it arcs from the bottom left to the top right is considered to have the highest predictive power. So the two models seemed to be fairly similar. Lastly, the hold out test set was used to obtain the test accuracy of each model, given below.
Model | Test set accuracy----------------- | -----------------Random Forest | 80.95%Oblique RF pls | 76.19%The RF outperformed the ORF by roughly 4.76%.
So there it was, I had my model! Ready with my trained Random Forest at my side I was going to predict the future of the Rugby World Cup. But then I thought, wouldn't it be really cool if I could find some way to do what I just did, but between each match incorporate the latest result from the tournament? In other words, collect the outcome of a match just after it took place, add it to my data, retrain the model and make a prediction for the next match with the new up to date model. On top of this, would it be possible to do it in some automated fashion? Then along came Domino!
Automating the process using Domino scheduling
I first heard of Domino from this great blog post by Jo-Fai Chow which shows you how to use R, H2O and Domino for a Kaggle competition. In a nutshell, Domino is an enterprise-grade platform that enables you to run, scale, share, and deploy analytical models. The post also includes a tutorial on how to get started with Domino, from getting up and running to running your first R program in the cloud! I would recommend this as a good place to start for anyone new to Domino.
So the first thing I needed to do to automate the process of data collection and model retraining was to upload my R scripts. First, the script (GetRWCData.R) responsible for getting and cleaning the data which outputs a .csv file containing the new data. Second, I had to upload the script (RWCPrediction.R) used to train the model on the outputted data, saving the model as a .rda file.
Since I decided to use the RF instead of the ORF, the model training script RWCPrediction.R contains the following code.
### International Rugby world cup match prediction model #### load librarieslibrary(caret)library(randomForest)# load datadata <- readRDS("RWCData.rda")# tune GridrfGrid <- expand.grid(mtry = c(1, 7, 10, 15, 20, 25, 30, 35, 40, 45, 50))# Tune using 5-fold cross-validationfitControl <- trainControl(method = "cv",number = 5,repeats = 1)# train classifiermodel <- train(x=data[,-1], y=data[,1], method="rf", ntree=1000,trControl=fitControl, tuneGrid=rfGrid)# save modelsaveRDS(model, file = "RWC_Prediction_Model.rda")Now to automate using Domino's scheduling functionality! To do this I simply went to the schedule tab, inserted my script for getting the data as the command to run, set a recurring time and clicked schedule. (The following example is slightly simplified since I had to fine-tune the schedule to run between each game and not just every day at a fixed time.)
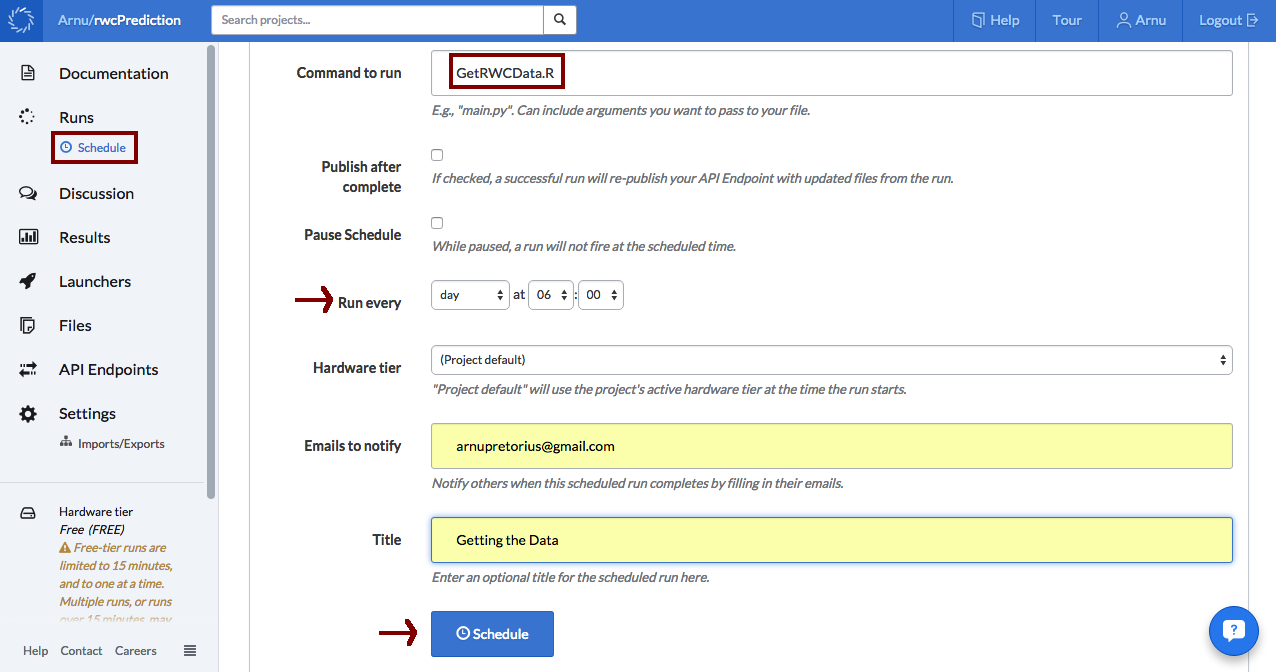
After the data script had run successfully, the model script can use the new data to retrain the model. So similarly, I inserted my script for training the model as the command to run, set the recurring time (an hour after the data had been collected), and clicked schedule. Note in this case I also ticked the publish after complete box which takes care of republishing the API (more about this later).
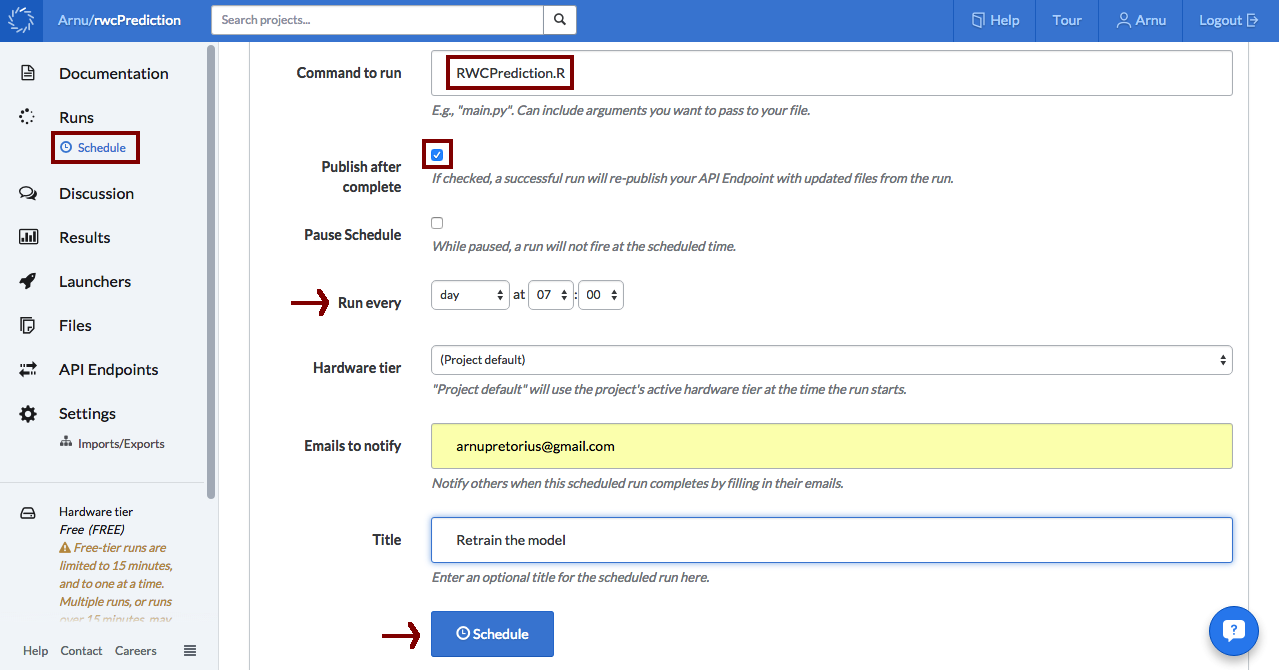
As easy as that I had an automated pipeline for data collection, cleaning, and model training! However, from the very beginning of this project I wasn't working alone, so while I was getting data and building models a good friend of mine Doug was building a web app to display the predictions. Once the app was up and running, all we needed to do was to figure out how it could get the model predictions. Enter Domino API Endpoints.
Using API Endpoints for on-demand prediction
Domino's API Endpoints let you deploy your R (or Python) predictive models as APIs, so other software systems can use them. The first step was to write a predict_match function inside an R script (given below) which takes as arguments the two teams and returns a prediction as a character string.
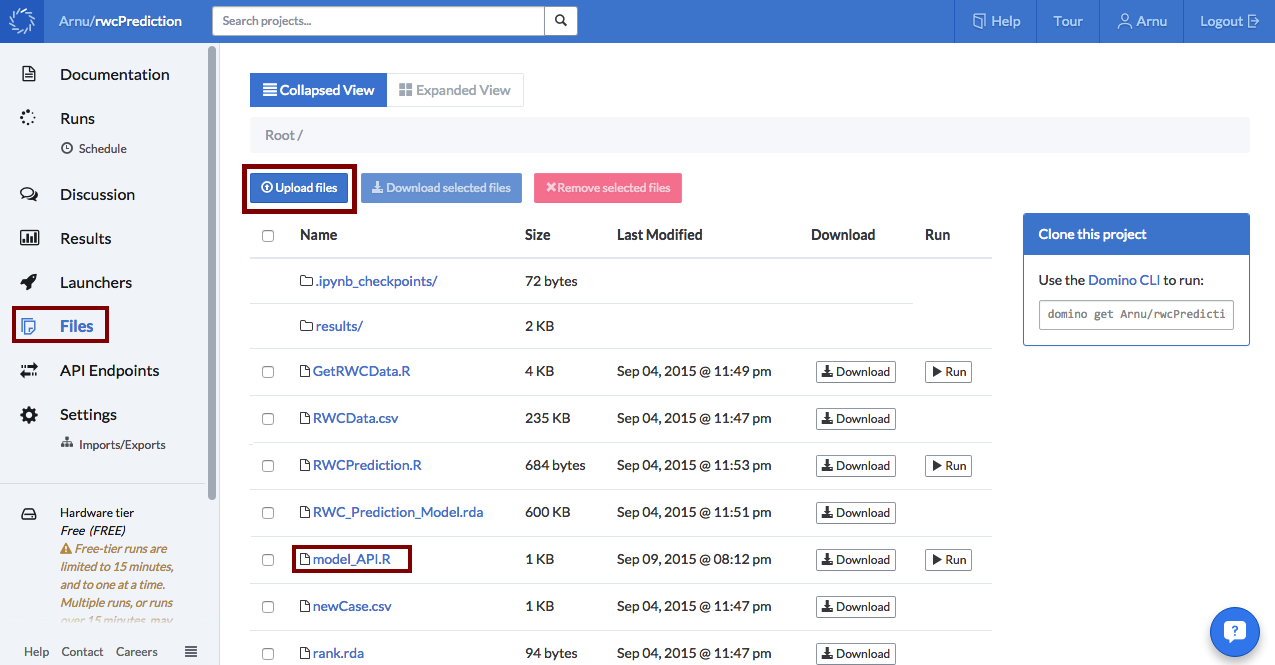
## Load Librarylibrary(caret)library(randomForest)library(lubridate)## Load Pre-trained modelmodel<- readRDS(file = "RWC_Prediction_Model.rda")## Load predictorsteamStats <- readRDS(file="teamStats.rda")rank <- readRDS("rank.rda")rankScore <- readRDS("rankScore.rda")rankChange <- readRDS("rankChange.rda")teams <- readRDS("teamNames.rda")## Create a function to take team name inputs## and then return a prediction for the matchpredict_match <- function(homeTeam, awayTeam) {homeIndex <- which(teams == homeTeam)awayIndex <- which(teams == awayTeam)swap <- awayTeam == "England"if(swap){temp<- homeTeamhomeTeam <- awayTeamawayTeam <- temptemp <- homeIndexhomeIndex <- awayIndexawayIndex <- temp}homeTeamStats <- c(teamStats[[homeIndex]], rank[homeIndex], rankScore[homeIndex], rankChange[homeIndex])awayTeamStats <- c(teamStats[[awayIndex]], rank[awayIndex], rankScore[awayIndex], rankChange[awayIndex])date<- Sys.Date()levelsx <- levels(factor(teams))levelsy <- levels(factor(c("loose","win")))newCase <- readRDS("newCase.rda")newCase[1,2] <- homeTeamnewCase[1,3] <- awayTeamnewCase[1,4] <- factor(month(date))newCase[1,5] <- factor(year(date))newCase[1,6:29] <- homeTeamStatsnewCase[1,30:53] <- awayTeamStats## Return the predicted class probabilitiesif(swap){y_probs <- predict(model, newCase, type="prob")return(as.character(rev(y_probs)))} else if(homeTeam == "England") {y_probs <- predict(model, newCase, type="prob")return(as.character(y_probs))} else {y_probs1 <- predict(model, newCase, type="prob")temp <- homeIndexhomeIndex <- awayIndexawayIndex <- temphomeTeamStats <- c(teamStats[[homeIndex]], rank[homeIndex], rankScore[homeIndex], rankChange[homeIndex])awayTeamStats <- c(teamStats[[awayIndex]], rank[awayIndex], rankScore[awayIndex], rankChange[awayIndex])date<- Sys.Date()levelsx <- levels(factor(teams))levelsy <- levels(factor(c("loose","win")))newCase <- readRDS("newCase.rda")newCase[1,2]<- homeTeamnewCase[1,3]<- awayTeamnewCase[1,4]<- factor(month(date))newCase[1,5]<- factor(year(date))newCase[1,6:29]<- homeTeamStatsnewCase[1,30:53]<- awayTeamStatsy_probs2<- predict(model, newCase, type="prob")looseProb<- round((y_probs1[1] + y_probs2[2])/2,4)winProb<- round((y_probs1[2] + y_probs2[1])/2,4)return(as.character(c(looseProb, winProb)))}}Now, one I had to remember was that within the data there was an implicit home team advantage and therefore the order of teams in the input string to the function was important. Since England is hosting the tournament, I set their predictions to always exhibit this home team advantage. For all the other teams I made two predictions with both teams getting a turn at being the home team. The final probabilities are then the average over the two predictions. The next step was to upload this script (in my case called model_API.R) to my Domino project.
The final step was to publish the API (which is really easy with Domino). I simply had to navigate to the API Endpoints tab, enter the name of the R script containing the prediction function, enter the prediction functions name and hit the publish button!
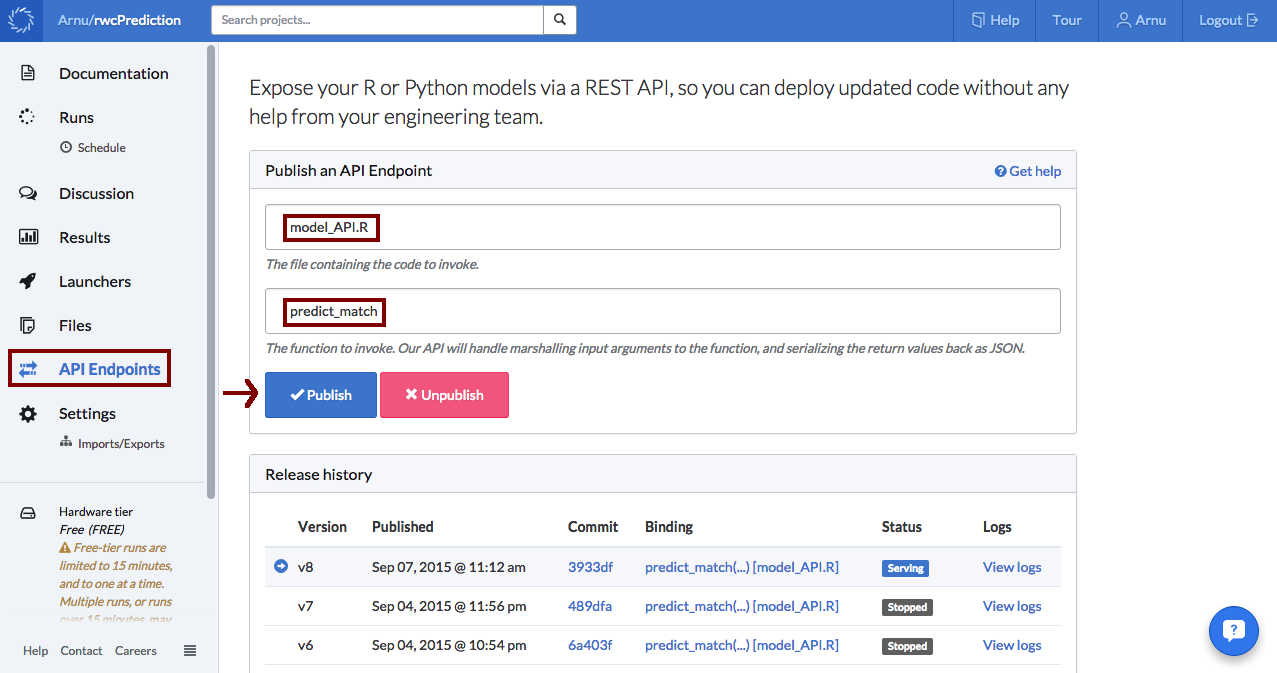
It's alive!! (Frankenstein voice)
So this is currently where the project is at. Now that all the necessary pieces of the puzzle are in place, on a daily basis the data is collected, the model retrain and prediction requests sent using some Python code very similar to the code given below.
import unirest
import json
import yaml
homeTeam = 'South Africa'
awayTeam = 'New Zealand'
response = unirest.post("https://app.dominodatalab.com/u/v1/Arnu/rwcPrediction/endpoint",
headers={"X-Domino-Api-Key": "MY_API_KEY",
"Content-Type": "application/json"},
params=json.dumps({
"parameters": [homeTeam, awayTeam]}))
## Extract information from response
response_data = yaml.load(response.raw_body)
## Print Result only
print("Predicted:")
print(response_data['result'])Conclusion
So there you have it.
In summary, using Domino and R I was able to:
- Write scripts to collect relevant Rugby data, perform exploratory analysis and select an appropriate model.
- Automate the data collection to happen on a daily basis as new match results become available.
- Automate the model training to happen after the data collection on a daily basis.
- Use the API Endpoints to turn the trained models into APIs capable of receiving prediction requests.
- Automate the republishing of the API by ticking the publish after complete box when scheduling the training of the prediction model.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.