Natural Language Processing in Python using spaCy: An Introduction
Paco Nathan2019-09-10 | 15 min read

This article provides a brief introduction to natural language using spaCy and related libraries in Python.
Introduction
Data science teams in the industry must work with lots of text, one of the top four categories of data used in machine learning. Usually, it's human-generated text, but not always.
Think about it: how does the "operating system" for business work? Typically, there are contracts (sales contracts, work agreements, partnerships), there are invoices, there are insurance policies, there are regulations and other laws, and so on. All of those are represented as text.
You may run across a few acronyms: natural language processing (NLP), natural language understanding (NLU), natural language generation (NLG)—which are roughly speaking "read text", "understand meaning", "write text" respectively. Increasingly these tasks overlap and it becomes difficult to categorize any given feature.
What is Spacy?
How do data science teams go about processing unstructured text data? Oftentimes teams turn to various libraries in Python to manage complex NLP tasks. sPacy is an open-source Python library that provides capabilities to conduct advanced natural language processing analysis and build models that can underpin document analysis, chatbot capabilities, and all other forms of text analysis.
The spaCy framework—along with a wide and growing range of plug-ins and other integrations—provides features for a wide range of natural language tasks. It's become one of the most widely used natural language libraries in Python for industry use cases, and has quite a large community—and with that, much support for commercialization of research advances as this area continues to evolve rapidly.
This article provides a brief introduction to working with natural language (sometimes called "text analytics") in Python using spaCy and related libraries.
Getting Started
If you're interested in how Domino's Compute Environments work, check out the Support Page.
Now let's load spaCy and run some code:
import spacy
nlp = spacy.load("en_core_web_sm")That nlp variable is now your gateway to all things spaCy and loaded with the en_core_web_sm small model for English. Next, let's run a small "document" through the natural language parser:
text = "The rain in Spain falls mainly on the plain."
doc = nlp(text)
for token in doc:
print(token.text, token.lemma_, token.pos_, token.is_stop)The DET Truerain rain NOUN Falsein in ADP TrueSpain Spain PROPN Falsefalls fall VERB Falsemainly mainly ADV Falseon on ADP Truethe DET Trueplain plain NOUN False. . PUNCT FalseFirst we created a doc from the text, which is a container for a document and all of its annotations. Then we iterated through the document to see what spaCy had parsed.
Good, but it's a lot of info and a bit difficult to read. Let's reformat the spaCy parse of that sentence as a pandas dataframe:
import pandas as pd
cols = ("text", "lemma", "POS", "explain", "stopword")
rows = []
for t in doc:
row = [t.text, t.lemma_, t.pos_, spacy.explain(t.pos_), t.is_stop]
rows.append(row)
df = pd.DataFrame(rows, columns=cols)
print(df)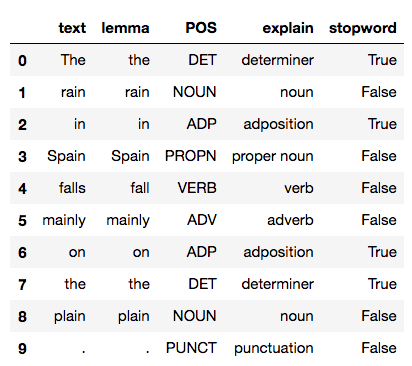
Much more readable! In this simple case, the entire document is merely one short sentence. For each word in that sentence spaCy has created a token, and we accessed fields in each token to show:
- raw text
- lemma – a root form of the word
- part of speech
- a flag for whether the word is a stopword—i.e., a common word that may be filtered out
Next, let's use the displaCy library to visualize the parse tree for that sentence:
from spacy import displacy
displacy.render(doc, style="dep")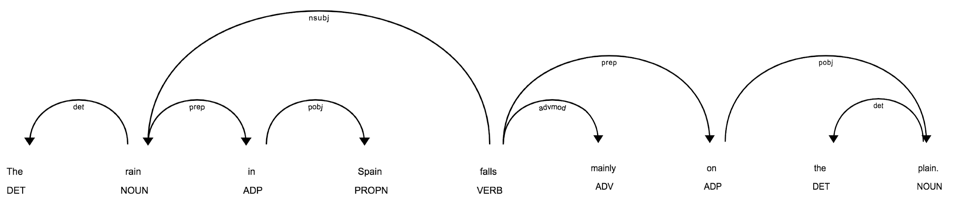
Does that bring back memories of grade school? Frankly, for those of us coming from more of a computational linguistics background, that diagram sparks joy.
But let's backup for a moment. How do you handle multiple sentences?
There are features for sentence boundary detection (SBD)—also known as sentence segmentation—based on the builtin/default sentencizer:
text = "We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit. I fell in.Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket. The gorillas just went wild."
doc = nlp(text)
for sent in doc.sents:
print(">", sent)> We were all out at the zoo one day, I was doing some acting, walking on the railing of the gorilla exhibit.> I fell in.> Everyone screamed and Tommy jumped in after me, forgetting that he had blueberries in his front pocket.> The gorillas just went wild.When spaCy creates a document, it uses a principle of non-destructive tokenization, meaning that the tokens, sentences, etc., are simply indexes into a long array. In other words, they don't carve the text stream into little pieces. So each sentence is a span with a start and an end index into the document array:
for sent in doc.sents:
print(">", sent.start, sent.end)> 0 25> 25 29> 29 48> 48 54We can index into the document array to pull out the tokens for one sentence:
doc[48:54]The gorillas just went wild.Or simply index into a specific token, such as the verb went in the last sentence:
token = doc[51]
print(token.text, token.lemma_, token.pos_)went go VERBAt this point, we can parse a document, segment that document into sentences, then look at annotations about the tokens in each sentence. That's a good start.
Acquiring Text
Now that we can parse texts, where do we get texts? One quick source is to leverage the interwebs. Of course, when we download web pages we'll get HTML, and then need to extract text from them. Beautiful Soup is a popular package for that.
First, a little housekeeping:
import sys
import warnings
warnings.filterwarnings("ignore")In the following function get_text() we'll parse the HTML to find all of the <p/>tags, then extract the text for those:
from bs4 import BeautifulSoup
import requests
import traceback
def get_text (url):
buf = []
try:
soup = BeautifulSoup(requests.get(url).text, "html.parser")
for p in soup.find_all("p"):
buf.append(p.get_text())
return "".join(buf)
except:
print(traceback.format_exc())
sys.exit(-1)Now let's grab some text from online sources. We can compare open-source licenses hosted on the Open Source Initiative site:
lic = {}lic["mit"] = nlp(get_text("https://opensource.org/licenses/MIT"))
lic["asl"] = nlp(get_text("https://opensource.org/licenses/Apache-20"))
lic["bsd"] = nlp(get_text("https://opensource.org/licenses/BSD-3-Clause"))
for sent in lic["bsd"].sents:
print(">", sent)> SPDX short identifier: BSD-3-Clause> Note: This license has also been called the "New BSD License" or "Modified BSD License"> See also the 2-clause BSD License.…One common use case for natural language work is to compare texts. For example, with those open-source licenses we can download their text, parse, then compare similarity metrics among them:
pairs = [
["mit", "asl"],
["asl", "bsd"],
["bsd", "mit"]]
for a, b in pairs:
print(a, b, lic[a].similarity(lic[b]))mit asl 0.9482039305669306asl bsd 0.9391555350757145bsd mit 0.9895838089575453This is interesting since the BSD and MIT licenses appear to be the most similar documents. In fact, they are closely related.
Admittedly, there was some extra text included in each document due to the OSI disclaimer in the footer—but this provides a reasonable approximation for comparing the licenses.
Natural Language Understanding
Now let's dive into some of the spaCy features for NLU. Given that we have a parse of a document, from a purely grammatical standpoint we can pull the noun chunks, i.e., each of the noun phrases:
text = "Steve Jobs and Steve Wozniak incorporated Apple Computer on January 3, 1977, in Cupertino, California."
doc = nlp(text)
for chunk in doc.noun_chunks:
print(chunk.text)Steve JobsSteve WozniakApple ComputerJanuaryCupertinoCaliforniaNot bad. The noun phrases in a sentence generally provide more information content—as a simple filter used to reduce a long document into a more "distilled" representation.
We can take this approach further and identify named entities within the text, i.e., the proper nouns:
for ent in doc.ents:
print(ent.text, ent.label_)Steve Jobs PERSONSteve Wozniak PERSONApple Computer ORGJanuary 3, 1977 DATECupertino GPECalifornia GPEThe displaCy library provides an excellent way to visualize named entities:
displacy.render(doc, style="ent")
If you're working with knowledge graph applications and other linked data, your challenge is to construct links between the named entities in a document and other related information for the entities, which is called entity linking. Identifying the named entities in a document is the first step in this particular kind of AI work. For example, given the text above, one might link the Steve Wozniaknamed entity to a lookup in DBpedia.
In more general terms, one can also link lemmas to resources that describe their meanings. For example, in an early section, we parsed the sentence The gorillas just went wild and were able to show that the lemma for the word went is the verb go. At this point we can use a venerable project called WordNet which provides a lexical database for English—in other words, it's a computable thesaurus.
There's a spaCy integration for WordNet called spacy-wordnet by Daniel Vila Suero, an expert in natural language and knowledge graph work.
Then we'll load the WordNet data via NLTK (these things happen):
import nltk
nltk.download("wordnet")[nltk_data] Downloading package wordnet to /home/ceteri/nltk_data...[nltk_data] Package wordnet is already up-to-date!TrueNote that spaCy runs as a "pipeline" and allows means for customizing parts of the pipeline in use. That's excellent for supporting really interesting workflow integrations in data science work. Here we'll add the WordnetAnnotator from the spacy-wordnet project:
from spacy_wordnet.wordnet_annotator import WordnetAnnotator
print("before", nlp.pipe_names)
if "WordnetAnnotator" not in nlp.pipe_names:
nlp.add_pipe(WordnetAnnotator(nlp.lang), after="tagger")print("after", nlp.pipe_names)before ['tagger', 'parser', 'ner']after ['tagger', 'WordnetAnnotator', 'parser', 'ner']Within the English language, some words are infamous for having many possible meanings. For example, click through the results online in a WordNet search to find the meanings related to the word withdraw.
Now let's use spaCy to perform that lookup automatically:
token = nlp("withdraw")[0]
token._.wordnet.synsets()[Synset('withdraw.v.01'),Synset('retire.v.02'),Synset('disengage.v.01'),Synset('recall.v.07'),Synset('swallow.v.05'),Synset('seclude.v.01'),Synset('adjourn.v.02')Synset('bow_out.v.02'),Synset('withdraw.v.09'),Synset('retire.v.08'),Synset('retreat.v.04'),Synset('remove.v.01')]token._.wordnet.lemmas()[Lemma('withdraw.v.01.withdraw'),Lemma('withdraw.v.01.retreat'),Lemma('withdraw.v.01.pull_away'),Lemma('withdraw.v.01.draw_back'),Lemma('withdraw.v.01.recede'),Lemma('withdraw.v.01.pull_back'),Lemma('withdraw.v.01.retire'),…token._.wordnet.wordnet_domains()["astronomy","school","telegraphy","industry","psychology","ethnology","ethnology","administration","school","finance","economy","exchange","banking","commerce","medicine","ethnology","university",
…
Again, if you are working with knowledge graphs, those "word sense" links from WordNet could be used along with graph algorithms to help identify the meanings for a particular word. This can also be used to develop summaries for larger sections of text through a technique called summarization. It's beyond the scope of this tutorial, but an interesting application currently for natural language in the industry.
Going in the other direction, if you know a priori that a document was about a particular domain or set of topics, then you can constrain the meanings returned from WordNet. In the following example, we want to consider NLU results that are within Finance and Banking:
domains = ["finance", "banking"]
sentence = nlp("I want to withdraw 5,000 euros.")
enriched_sent = []
for token in sentence:
# get synsets within the desired domains
synsets = token._.wordnet.wordnet_synsets_for_domain(domains)
if synsets:
lemmas_for_synset = []
for s in synsets:
# get synset variants and add to the enriched sentence
lemmas_for_synset.extend(s.lemma_names())
enriched_sent.append("({})".format("|".join(set(lemmas_for_synset))))
else:
enriched_sent.append(token.text)
print(" ".join(enriched_sent))I (require|want|need) to (draw_off|withdraw|draw|take_out) 5,000 euros .That example may look simple but, if you play with the domains list, you'll find that the results have a kind of combinatorial explosion when run without reasonable constraints. Imagine having a knowledge graph with millions of elements: you'd want to constrain searches where possible to avoid having every query take days/weeks/months/years to compute.
Text Comparison with spaCy and Scattertext
Sometimes the problems encountered when trying to understand a text—or better yet when trying to understand a corpus (a dataset with many related texts)—become so complex that you need to visualize it first. Here's an interactive visualization for understanding texts: scattertext, a product of the genius of Jason Kessler.
Let's analyze text data from the party conventions during the 2012 US Presidential elections. Note: this cell may take a few minutes to run but the results from all that number-crunching is worth the wait.
import scattertext as st
if "merge_entities" not in nlp.pipe_names:
nlp.add_pipe(nlp.create_pipe("merge_entities"))
if "merge_noun_chunks" not in nlp.pipe_names:
nlp.add_pipe(nlp.create_pipe("merge_noun_chunks"))
convention_df = st.SampleCorpora.ConventionData2012.get_data()
corpus = st.CorpusFromPandas(convention_df, category_col="party", text_col="text", nlp=nlp).build()Once you have the corpus ready, generate an interactive visualization in HTML:
html = st.produce_scattertext_explorer(corpus, category="democrat",
category_name="Democratic",
not_category_name="Republican",
width_in_pixels=1000,
metadata=convention_df["speaker"])Now we'll render the HTML—give it a minute or two to load, it's worth the wait:
from IPython.display import IFrame
file_name = "foo.html"
with open(file_name, "wb") as f:
f.write(html.encode("utf-8"))
IFrame(src=file_name, width = 1200, height=700)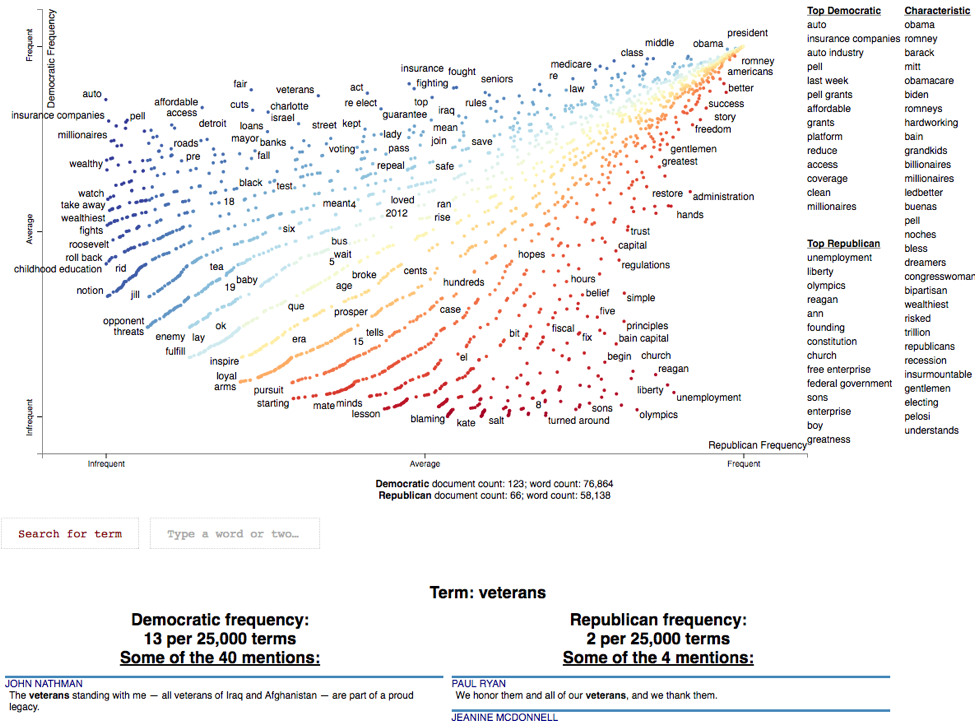
Imagine if you had text from the past three years of customer support for a particular product in your organization. Suppose your team needed to understand how customers have been talking about the product? This scattertext library might come in quite handy! You could cluster (k=2) on NPS scores (a customer evaluation metric) then replace the Democrat/Republican dimension with the top two components from the clustering.
Summary
Five years ago, if you’d asked about open source in Python for natural language, a default answer from many people working in data science would've been NLTK. That project includes just about everything but the kitchen sink and has components that are relatively academic. Another popular natural language project is CoreNLP from Stanford. Also quite academic, albeit powerful, though CoreNLP can be challenging to integrate with other software for production use.
Then a few years ago everything in this natural language corner of the world began to change. The two principal authors for spaCy, Matthew Honnibal and Ines Montani, launched the project in 2015 and industry adoption was rapid. They focused on an opinionated approach (do what's needed, do it well, no more, no less) which provided simple, rapid integration into data science workflows in Python, as well as faster execution and better accuracy than the alternatives. Based on these priorities, spaCy became sort of the opposite of NLTK. Since 2015, spaCy has consistently focused on being an open-source project (i.e., depending on its community for directions, integrations, etc.) and being commercial-grade software (not academic research). That said, spaCy has been quick to incorporate the SOTA advances in machine learning, effectively becoming a conduit for moving research into industry.
It's important to note that machine learning for natural language got a big boost during the mid-2000's as Google began to win international language translation competitions. Another big change occurred during 2017-2018 when, following the many successes of deep learning, those approaches began to out-perform previous machine learning models. For example, see the ELMo work on language embedding by Allen AI, followed by BERT from Google, and more recently ERNIE by Baidu—in other words, the search engine giants of the world have gifted the rest of us with a Sesame Street repertoire of open-source embedded language models based on deep learning, which is now state of the art (SOTA). Speaking of which, to keep track of SOTA for natural language keep an eye on NLP-Progress and Papers with Code.
The use cases for natural language have shifted dramatically over the past two years, after deep learning techniques arose to the fore. Circa 2014, a natural language tutorial in Python might have shown word count or keyword search or sentiment detection and the target use cases were relatively underwhelming. Circa 2019, we're talking about analyzing thousands of documents for vendor contracts in an industrial supply chain optimization...or hundreds of millions of documents for policyholders of an insurance company or gazillions of documents regarding financial disclosures. More contemporary natural language work tends to be in NLU, often to support the construction of knowledge graphs, and increasingly in NLG where large numbers of similar documents can be summarized at human scale.
The spaCy Universe is a great place to check for deep-dives into particular use cases and to see how this field is evolving. Some selections from this "universe" include:
- Blackstone – parsing unstructured legal texts
- Kindred – extracting entities from biomedical texts (e.g., Pharma)
- mordecai – parsing geographic information
- Prodigy – human-in-the-loop annotation for labeling datasets
- Rasa NLU – Rasa integration for chat apps
Also, a couple super new items to mention:
- spacy-pytorch-transformers to fine-tune (i.e., use transfer learning with) the Sesame Street characters and friends: BERT, GPT-2, XLNet, etc.
- spaCy IRL 2019 conference – check out videos from the talks!
There's so much more we can do with spaCy— hopefully, this tutorial provides an introduction. We wish you all the best in your natural language work.

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.