Model Management and the Era of the Model-Driven Business
Nick Elprin2018-07-11 | 10 min read

Over the past few years, we’ve seen a new community of data science leaders emerge.
Regardless of their industry, we have heard three themes emerge over and over: 1) Companies are recognizing that data science is a competitive differentiator. 2) People are worried their companies are falling behind — that other companies are doing a better job with data science. 3) Data scientists and data science leaders are struggling to explain to executives why data science is different from other types of work, and the implications of these differences on how to equip and organize data science teams.
We recently gathered this community of data science leaders at Rev. There, we shared our vision for “Model Management”, a set of processes and technologies that allows companies to drive competitive advantage from data science at scale. This post is a summary of that talk, which you can watch here.
Introduction
Since we started Domino five years ago, we have talked to hundreds of companies that are investing in data science, and heard all about their successes and their challenges.
At various points during that time, we focused on different aspects of the challenges that face data scientists and data science teams.
- When we first launched Domino in 2014, we focused on automating much of the “dev ops” work that data scientists must do, in order to accelerate their work.
- In 2015, we broadened our aperture to address data scientists’ need to track and organize their research.
- In 2016, we added capabilities to deploy models, creating a unified platform to support the data science lifecycle from development to deployment.
- And in 2017, we emphasized how collaboration, reproducibility, and reusability are the foundation that allows data science teams to scale effectively.
At every point along the way, we felt like there was something larger we wanted to say, but we didn’t quite know how. Like the parable of the blind men describing different parts of an elephant, we knew we were describing pieces but not the whole.
So about a year ago we took a step back. We had long discussions with our customers to distill and synthesize what makes data science different and what differentiates companies who apply it most effectively.
What do Data Scientists Make?
Our major insight came when we asked ourselves: “what do data scientists make?”
Beyond the hype about AI and machine learning, at the heart of data science, is something called a model. By “model,” I mean an algorithm that makes a prediction or recommendation or prescribes some action based on a probabilistic assessment.

Models can make decisions and take action autonomously and with speed and sophistication that humans can’t usually match. That makes models a new type of digital life.
Data scientists make models.
And if you look at the most successful companies in the world, you’ll find models at the heart of their business driving that success.
An example that everyone is familiar with is the Netflix recommendation model. It has driven subscriber engagement, retention, and operational efficiency at Netflix. In 2016, Netflix indicated that their recommendation model is worth more than $1B per year.
Coca-Cola uses a model to optimize orange juice production. Stitch Fix uses models to recommend clothing to its customers. Insurance companies are beginning to use models to make automated damage estimates from accident photos, reducing dependence on claims adjusters.
The Model Myth
Though obvious in one sense, the realization that data scientists make models is powerful because it explains most of the challenges that companies have making effective use of data science.
Fundamentally, the reasons companies struggle with data science all stem from misunderstandings about how models are different from other types of assets they’ve built in the past.
Many companies try to develop and deploy models like they develop and deploy software. And many companies try to equip data scientists with technology like they were equipping business analysts to do queries and build business intelligence dashboards.
It’s easy to see why companies fall into this trap: models involve code and data, so it’s easy to mistake them for software or data assets.
We call this theModel Myth: it’s the misconception that because models involve code and data, companies can treat them like they have traditionally treated software or data assets.
Models are fundamentally different, in three ways:
- The materials used to develop them are different. They involve code, but they use different techniques and different tools than software engineering. They use more computationally intensive algorithms, so they benefit from scalable compute and specialized hardware like GPUs. They use far more data than software projects. And they leverage packages from a vibrant open source ecosystem that’s innovating every day. So data scientists need extremely agile technology infrastructure, to accelerate research.
- The process to build them is different. Data science is research — it’s experimental and iterative and exploratory. You might try dozens or hundreds of ideas before getting something that works. So data scientists need tools that allow for quick exploration and iteration to make them productive and facilitate breakthroughs.
- Models’ behavior is different. Models are probabilistic. They have no “correct” answer — they can just have better or worse answers once they’re live in the real world. And while nobody needs to “retrain” software, models can change as the world changes around them. So organizations need different ways to review, quality control, and monitor them.
Model Management
The companies who make the most effective use of data science — ones who consistently drive competitive advantage through data science — are the ones who recognize that models are different and treat them differently.
We’ve studied the various ways these companies treat models differently, and organized that into a framework we call Model Management.
Historically, “model management” has referred narrowly to practices for monitoring models once they are running in production. We mean it as something much broader.
Model Management encompasses a set of processes and technologies that allow companies to consistently and safely drive competitive advantage from data science at scale.
Model Management has five parts to it:
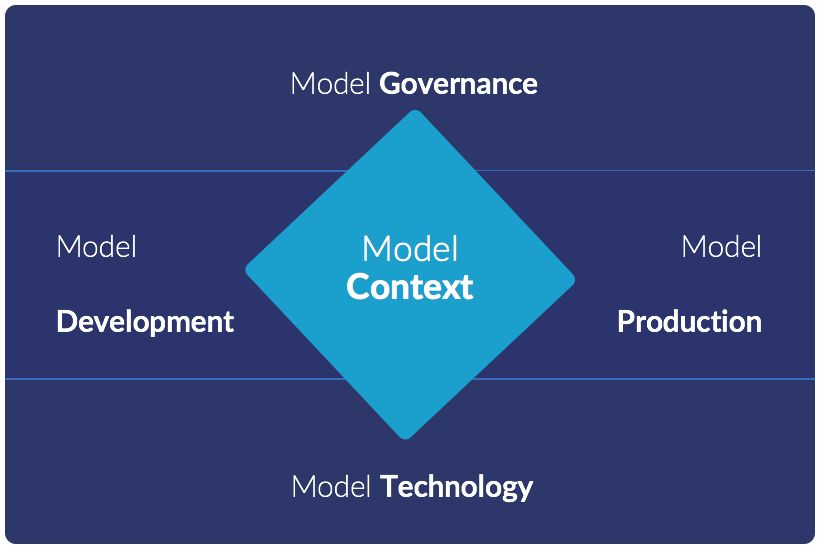
- Model Development allows data scientists to rapidly develop models, experiment, and drive breakthrough research.
- Model Production is how data scientists’ work get operationalized. How it goes from a cool project to a live product integrated into business processes, affecting real decisions.
- Model Technology encompasses the compute infrastructure and software tooling that gives data scientists the agility they need to develop and deploy innovative models.
- Model Governance is how a company can keep a finger on the pulse of the activity and impact of data science work across its organization, to know what’s going on with projects, production models, and the underlying infrastructure supporting them.
- Model Context is at the heart of these capabilities. It is all the knowledge, insights, and all the artifacts that are generated while building or using models. This is often a company’s most valuable IP, and the ability to find, reuse, and build upon it is critical to driving rapid innovation.
Each of these facets of managing models requires unique processes and products. When integrated together, they unlock the full potential of data science for organizations.
Computing revolutions separate winners from losers
Data science is a new era of computing. The first era was hardware, where engineers made chips and boards. The second era was software, where engineers made applications. In the third era, data scientists make models.
And like past revolutions in computing, two things are true about the data science era:
- Companies’ ability to adopt and effectively apply the new approach will determine their competitiveness over the coming years. Just as “software ate the world” and “every company needed to be a software company”, every company will need to become a data science company if they want to stay competitive.
- The methodologies and tooling and processes that worked for the previous era will not work for this new era. The rise of software engineering led to new methodologies, new job titles, and new tools — what worked for developing, delivering and managing hardware didn’t work for software. The same is true for data science: what worked for software will not work for models.
Model Management is the set of processes and technologies a company needs to put models at the heart of their business. It’s required because models are different from software, so they need new ways to develop, deliver and manage them. And by adopting Model Management, organizations can unlock the full potential of data science, becoming model-driven businesses.
To learn more, read our guide on model management or watch the keynote.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.