
In this article we explain how we’re using Kubernetes to enable data scientists to deploy predictive models as production-grade APIs.
Background
Domino lets users publish R or Python models as REST APIs, so they can easily integrate data science projects into existing applications and business processes without involving engineers or devops resources. We call this Model Deployment.
We’ve had this functionality since 2015. The first version was a more simple feature that created API endpoints for R and Python models hosted in Domino, allowing them to be used by web services.
This was a popular feature among many of our smaller and startup users, such as 8tracks, who used it to integrate their predictive models with user-facing applications without the need to port those models from R or Python.
However, this version was reusing large parts of our infrastructure that we built for running models within Domino. While a run can last a few hours, an API endpoint might be expected to be up and running for weeks if not months. Additionally, that infrastructure was not built to support horizontal scalability, which made it challenging to ensure that each API endpoint remains responsive under load.
As more enterprise users started using Domino, demand quickly grew for more robust model deployment functionality. That’s when we took the opportunity to completely rebuild it using Kubernetes.
Rebuilding Model Deployment with Kubernetes
As part of our Domino 2.0 launch, we set out to completely re-architect the API endpoints functionality to support large-scale use cases at even lower latencies, while also adding more advanced capabilities such as A/B testing model variations.
Kubernetes—an open-source system for automating the deployment, scaling, and management of containerized applications—was a natural fit, as it would allow us to start up each of our models in isolation on shared infrastructure, and to scale them individually on demand.
Architecture
A model consists of all code and data taken from a Domino project, combined with an harness that exposes a web service calling the user’s code. Each model gets built into a Docker image, which ensures that the model gets packaged together and versioned.
Once a model version is built, it is then deployed on Kubernetes, using both a Kubernetes Deployment and Service. The Deployment allows us to ensure that each Kubernetes pod responsible to run the model stays healthy, spins up new pods to replace unhealthy ones, and allows us to scale up and down easily. The Service is what exposes the model.
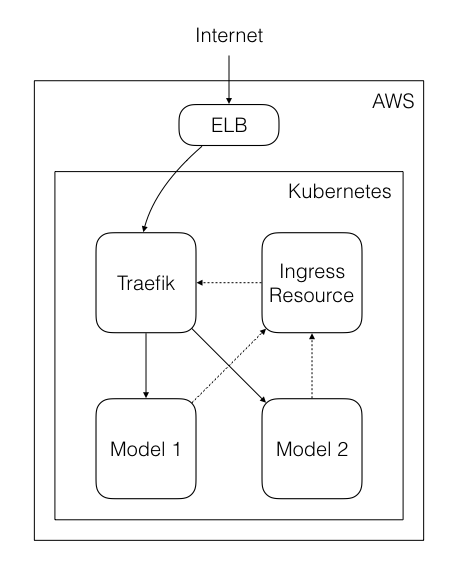
The models are exposed outside of Kubernetes using an Ingress Resource. This allows us to make different versions of the same model accessible using different paths.
However, an Ingress Resource by itself merely acts as a routing table. To ensure that these services do get exposed, we use Traefik as an Ingress Controller. Traefik is a reverse proxy similar to nginx, but provides first-party support for Kubernetes. This ensures that any updates to our Ingress Resources get reflected quickly.
Finally, an Elastic Loan Balancer (ELB) gets created to ensure that the models can be accessed from outside of the internal network.
A prior iteration of this architecture was not using the Ingress inside of Kubernetes or Traefik. Instead, we used Nginx as a service, with a dynamically loaded configuration file, provided by a config map. This worked well as a proof of concept, but had two principal issues:
- We depended on one monolithic config file for all of our routes.
- The delay between an update to the config and Nginx being refreshed was very slow, which made it feel like nothing was happening in the system.
The Ingress resources allowed us to have each model own their own routes, while Traefik, using a Kubernetes Watcher—which notifies you of the different changes happening to the cluster—is able to refresh itself when a relevant event happens on the Kubernetes Cluster.
Another challenge we ran into was finding a way to keep the information about models in sync and deduplicated between Kubernetes and our database.
Initially, we had metadata about our deployments stored in a database. We were using Kubernetes Watchers ourselves to keep that information up-to-date, but the logic to keep this info in sync was complex.
We started using Kubernetes annotations and labels more liberally to move most of that metadata onto Kubernetes itself, which allowed us to ultimately ensure that all information about a particular model deployment is persisted in one place.
To avoid calling Kubernetes too often to retrieve this metadata, we save this data in our cache, which gets updated via a Kubernetes watcher process. This process is running on Kubernetes itself, to ensure that we do not lose messages from Kubernetes during maintenance of the Domino application.
To keep the user informed on the current status of a model, we built a system to asynchronously monitor the status of our deployments. This is fed by a set of Kubernetes Watchers, which gives us a raw event stream of state transitions of a Kubernetes deployment.
Finally, to make this stream more durable (a missed message would be lost forever) we redirected it to a message bus using RabbitMQ. We also use RabbitMQ internally to feed our system managing the diverse long-running user actions in our Model Deployment features.
Results
Compared to the original API endpoints, the new Model Deployment architecture allows us to execute models by an order of magnitude faster, making it ideal for production use. We benchmarked popular machine learning models in R and Python and found a latency of <50ms handling 6,000 requests per minute.
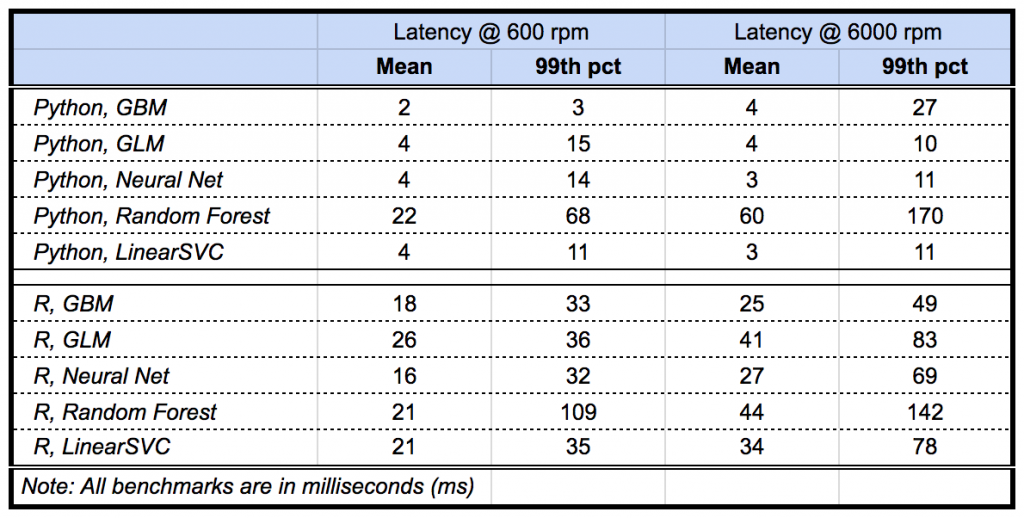
(Please note that the performance is based on internal testing and does not represent a performance guarantee. Model latency depends on a number of factors such as external service dependencies, network topology, and hardware configuration.)
Using Kubernetes has also allowed us to provide A/B testing and versioning functionality for deployed models. For example, a data scientist can control which model version is used in production, meaning they can test different versions of the same model and only promote a version to production when it’s ready.
Last but not least, another benefit of this architecture is increased reliability; since this feature is decoupled from the run execution, a deployed model is more resilient to issues happening in the Domino platform itself.

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.