
This Domino Data Science Field Note covers a proposed definition of machine learning interpretability, why interpretability matters, and the arguments for considering a rigorous evaluation of interpretability. Insights are drawn from Finale Doshi-Velez’s talk, “A Roadmap for the Rigorous Science of Interpretability” as well as the paper, “Towards a Rigorous Science of Interpretable Machine Learning”. The paper was co-authored by Finale Doshi-Velez and Been Kim. Finale Doshi-Velez is an assistant professor of computer science at Harvard Paulson School of Engineering and Been Kim is a research scientist at Google Brain.
Introduction
Data scientists make models. Models, particularly algorithms that make recommendations or prescribe action based on a probabilistic assessment, have the ability to change, and be “retrained” (sometimes with unintended consequences). This leads data scientists to consider ways to evaluate models beyond expected task performance. Data scientists are able to use interpretability (and the growing research on it) to satisfy auxiliary criteria that include being trusted (human users’ confidence), avoiding unquantified bias, privacy, providing the right to explanation, and more. Yet, is there a consensus on the definition of "interpretability"? or "evaluating interpretability"? This blog post covers a proposed definition of machine learning interpretability as well as rigorous evaluations of interpretability. The insights covered in this blog post are from Finale Doshi-Velez’s talk, “A Roadmap for the Rigorous Science of Interpretability” as well as the paper, “Towards a Rigorous Science of Interpretable Machine Learning”. The paper was co-authored by Finale Doshi-Velez and Been Kim.
Definition: Interpretability in the Context of Machine Learning
Kim and Doshi-Velez argue that there is “little consensus on what interpretability in machine learning is and how to evaluate it for benchmarking” and propose that “in the context of ML systems, we define interpretability as the ability to explain or to present in understandable terms to a human.” Doshi-Velez, in the talk, points to “interpret” as being the root word for interpretability and the dictionary definition of "interpret" is to explain or provide meaning. Doshi-Velez also indicates that the word, “explanation”, is a “more human tangible word than interpretability” and allows people to consider “what is a good explanation? have I explained something to you?” and asks the audience to think about “what’s the quality of this explanation” as a means to introduce the concept of rigor for evaluating interpretability.
Why Interpretability
Not all ML systems require interpretability. Interpretability is not required when “there is no significant consequences for unacceptable results” or when the ML is “well-studied and validated in real applications that we trust the system’s decision, even if the system is not perfect”. Interpretability is needed when auxiliary criteria are not met and questions about bias, trust, safety, ethics, and mismatched objectives arise. Kim and Doshi-Velez “argue that the need for interpretability stems from incompleteness in the problem formalizing, creating a fundamental barrier to optimization and evaluation” for example, “incompleteness that produces some kind of unquantified bias”.
Current Evaluation of Interpretability: Two Categories
Kim and Doshi-Velez indicate that current evaluations of interpretability usually fall into two categories that are anchored in a “you’ll know it when you see it” perspective. The first category “evaluates interpretability in the context of an application: if the system is useful in either a practical application or a simplified version of it” then it is interpretable. The second category
“evaluates interpretability via a quantifiable proxy: a researcher might first claim that some model or class—e.g., sparse linear models, rule lists, gradient boosted trees — are interpretable and then present algorithms to optimize within that class.”
While both Doshi-Velez and Kim indicate that these categories are reasonable, they question whether “all models in all defined-to-be-interpretable model classes [are] equally interpretable?” and while “quantifiable proxies such as sparsity allow for comparison”, does this also apply when “comparing a model sparse in features to a model sparse in prototypes?” Not all applications have the same interpretability needs. Both argue for additional rigor in evaluations for interpretability. They cite GDPR and the growing body of research on interpretability as reasons for proposing additional rigor. They also recommend that “the claim of research should match the type of evaluation”.
Proposed Evaluations of Interpretability
Doshi-Velez and Kim propose a taxonomy of interpretable evaluation approaches: application-grounded evaluation, human-grounded metrics, and functional-grounded evaluation.
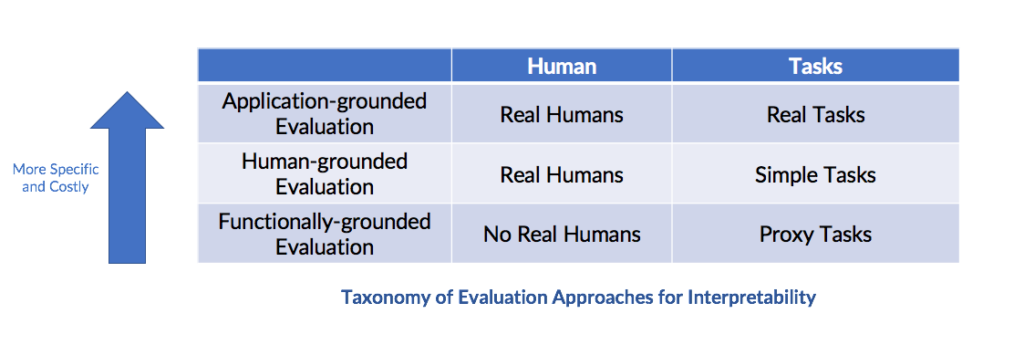
Application-grounded evaluation
Doshi-Velez, in the talk, indicates that this metric occurs when the researcher has a clear goal in mind, interpretability is evaluated within a real application, interpretability provides hard evidence, and enables the researcher to perform higher level tasks. Yet, “it may be costly to perform those evaluations because you have to do it in the context of a real application, and you might be curious about whether or not it generalizes.” In the paper, Kim and Doshi-Velez cite an example of application-grounded evaluation as “working with doctors on diagnosing patients with a particular disease---the best way to show the model works is to evaluate it with respect to the task: doctors performing diagnosis” ….and determine “whether it results in better identification of errors, new facts, or less discrimination”.
Human-grounded metrics
Kim and Doshi-Velez details this metric as “conducting simpler human-subject experiments that maintain the essence of the target application”. This is potentially useful when experiments with domain experts is prohibitly expensive or access to the target community is challenging. An example of a simpler human-subject experiment includes binary forced choice, or when “humans are presented with pairs of explanations, and must choose the one that they find of higher quality (basic face-validity test made quantitative).”
Functional-grounded evaluation
Doshi-Velez and Kim indicate that this metric does not include human experiments and instead, uses “formal definition of interpretability as a proxy for explanation quality”. This evaluation is “most appropriate once we have a class of models or regularizers that have already been validated e.g., human-grounded experiments” …. “or when human subject experiments are unethical”.
Conclusion
While this blog post covers distilled highlights regarding Kim and Doshi-Velez’s proposed definition of machine learning interpretability and a taxonomy for more rigorous evaluation of interpretability, additional insights and depth are available in the paper. The full video of Doshi-Velez’s talk is available for viewing as well.
Domino Data Science Field Notes provide highlights of data science research, trends, techniques, and more, that support data scientists and data science leaders accelerate their work or careers. If you are interested in your data science work being covered in this blog series, please send us an email at writeforus(at)dominodatalab(dot)com.

Ann Spencer is the former Head of Content for Domino where she provided a high degree of value, density, and analytical rigor that sparks respectful candid public discourse from multiple perspectives, discourse that’s anchored in the intention of helping accelerate data science work. Previously, she was the data editor at O’Reilly, focusing on data science and data engineering.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.