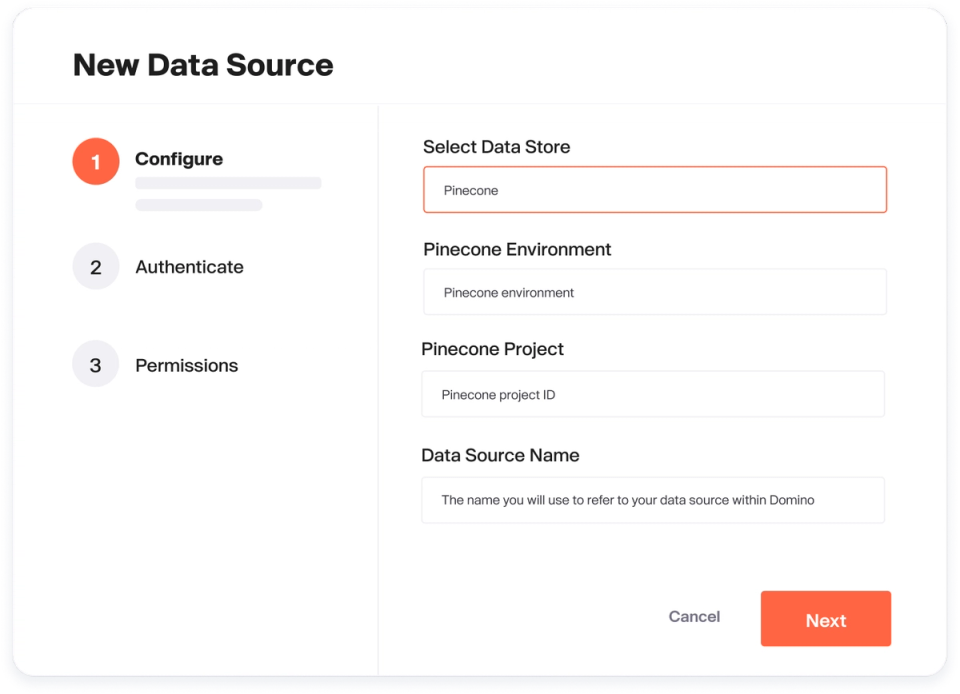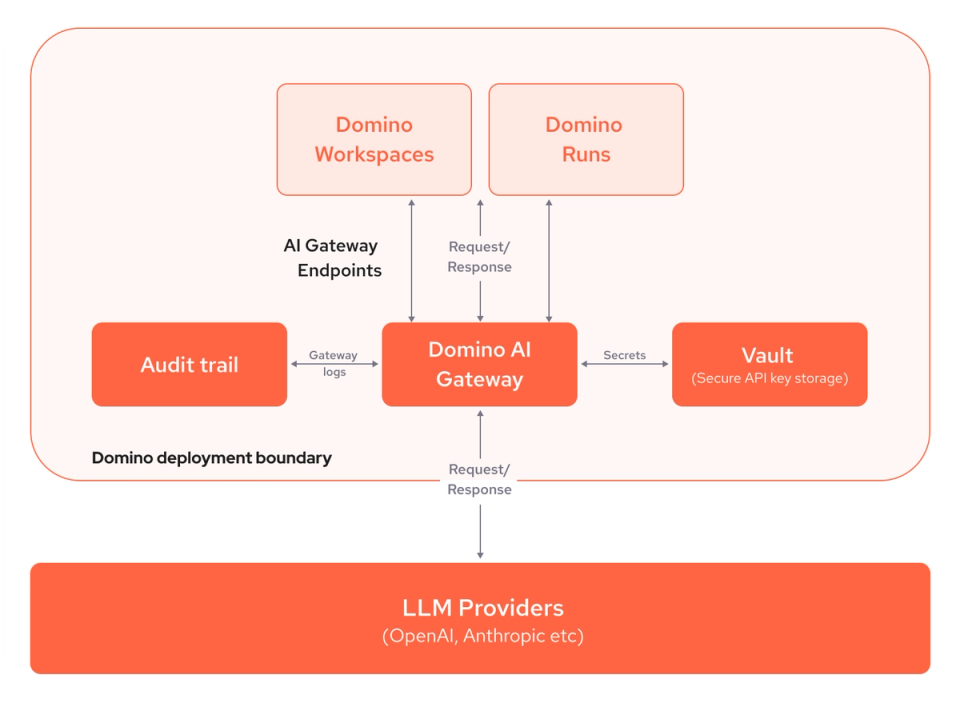
Domino AI Gateway
Streamline LLM access with controls and governance
Simplify access to any large language model (LLM) provider, such as OpenAI and Anthropic, via a secure, standard interface. Govern and manage LLM user access. Easily compare LLMs to find the best-performing LLMs and future-proof your generative AI strategy.