
Humans and Machines: SciFi or Already Commonplace?
Imagine you have a mostly-automated system where humans and machines collaborate together to perform some work. That may sound a wee bit SciFi … something cyborg, something The Future. Say you’re in the midst of heavy commute traffic a few years from now, where the freeway’s congested with a mix of self-driving cars and people driving cars. AI experts such as Anca Dragan at UC Berkeley are reaching toward exactly that: check out her recent "Cars that coordinate with people".
The scenario of people and machines teaming up together is already commonplace: pretty much any e-commerce website, running at scale, supported by a customer service team – qualify. However, a looming challenge is whether we can advance beyond rote tasks. Instead of simply running code libraries, can the machines make difficult decisions and exercise judgment in complex situations? Can we build systems where people who aren’t AI experts “teach” machines to handle work that requires more smarts? Preferably based on real-world examples, instead of abstracted programming?
On the other hand, we must build systems so people involved play a vital role too. Or, as David Beyer has put it, extremes of cognitive embrace are needed to make AI adoption effective in the workplace. Read: managing the impact of AI to be less abrupt, more useful.
Machine Learning as the Collaborator: Journey to Semi-Supervised Learning
Two variants of machine learning have become common. One is called supervised learning: there’s a dataset and each example in the data has a label. For example, digital images of cats and birds could be the data, while the annotations “cat” or “bird” would be their labels. Typically, a machine learning expert uses one part of the dataset to train ML models – so they predict labels based on input – then adjust parameters so the models predict accurately across the remaining data. The now popular approach of deep learning is a good example. Deep learning requires lots of carefully labeled training data to be useful.
Another common variant is unsupervised learning: run lots of data through an algorithm, out pops “structure”. For example, customer segmentation in online marketing often makes use of clustering algorithms such as K-means which are unsupervised. Leveraging an unsupervised approach to AI is a hot area of research, though it’s an open question.
A less common variant is called semi-supervised, and an important special case of that is known as “active learning”. The idea is simple: say you have an ensemble of ML models. The models “vote” on how to label each case of input data, and when they agree their consensus gets used – as an automated approach, most of the time. When the models disagree or lack confidence, kick the decision back to a human expert. Let people handle the difficult edge cases. Whatever the expert chooses, feed that judgment back to iterate on training the ML models.
Active Learning: Approach and Use Cases
Active Learning approach works well when you have lots of inexpensive, unlabeled data – an abundance of data, where the cost of labeling itself is a major expense. Say you’re an exec at a Detroit auto manufacturer. Google has years of advantage over your team, assembling labeled dataset as scale which are vital for training ML models needed in self-driving cars. Detroit? Not so much. As the industry begins to embrace AI applications, the lack of labeled data at scale poses a major hindrance. In some verticals, such as security, the powers that be have discouraged the collection of labeled, open data. Now, with the promise of AI apps, those priorities pivot. Auto manufacturers are currently scrambling to get important datasets labeled, to be able to compete in the self-driving market.
Expanding on the practice of active learning, human-in-the-loop is a design pattern emerging now for how to manage AI projects. One excellent case study is "Building a business that combines human experts and data science" by Eric Colson at Stitch Fix. Beyond the labeling of dataset, how do we get the best of both words – what people do better, complemented by what machines do better? Here’s a great quote from Eric:
“what machines can’t do are things around cognition, things that have to do with ambient information, or appreciation of aesthetics, or even the ability to relate to another human”
IMO, Stitch Fix is one of most interesting AI-augmented start-ups in San Francisco. As a “partner in personal style”, they blend the human fashion experts along with machine learning recommendations, to select and ship outfits to wear – for women and men. The services adapts to personal preferences, and represents an amazing example for the effective collaboration of humans and machines.
If you want to know even more about humans and machines complementing each other, check out these additional case studies: how to create a two-sided marketplace where machines and people compete on a spectrum of relative expertise and capabilities; Flash Teams for crowdsourcing expertise; and human-assisted AI at B12. Of course, you can also drop by my talk at JupyterCon.
Human-in-the-Loop AI with Jupyter
O’Reilly Media uses AI apps that leverage the human-in-the-loop design pattern. We work with lots of content, media across a spectrum of learning experiences: ebooks, instructional videos, conference talks, live online training, podcast interviews, case studies, etc. One almost ideal use case for active learning in media is the disambiguation of overlapping contexts. Suppose someone publishes a book which uses the term IOS: are they talking about the operating system for an Apple iPhone, or about the operating system for a Cisco router? We handle lots of content about both. Disambiguating those contexts is important for good UX in personalized learning. We also need good labels for our data (the learning content from 200+ publishers) before we can take advantage of deep learning.
Our NLP pipelines for disambiguation leverage Project Jupyter for our human-in-the-loop approach. At a high level, the process is simple:
- human experts provide examples of book chapters, video segments, etc., for a set of overlapping contexts: e.g., examples of
goas in Go programming language, some forgoas in AlphaGo, other instances ofgothat are null case – none of the above - machines build ensemble ML models based on those examples
- machines attempt to annotate millions of pieces of content, e.g., as
AlphaGo,Golang, or a “go” usage that’s not so interesting - the process runs mostly automated, parallel at scale – through integration with Apache Spark
- in cases where ensembles disagree, the NLP pipelines defer to human experts who make judgment calls, providing further examples
- those examples go into training the NLP pipelines to build better models
- rinse, lather, repeat toward natural language understanding in context
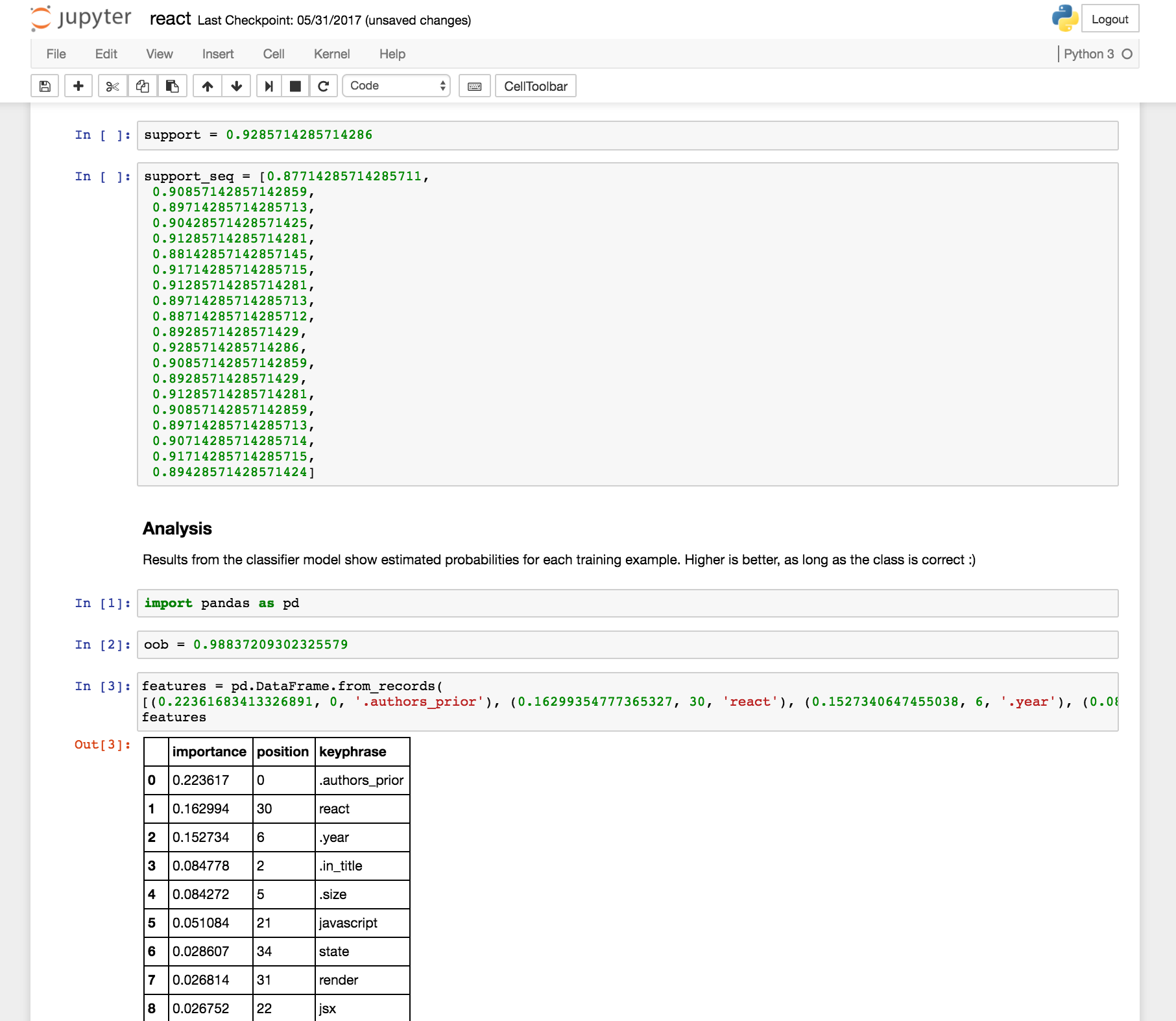
An interesting twist is that NLP pipelines in our disambiguation process are based on Jupyter notebooks. Each ambiguous term (e.g., go, ios, r, etc.) has a different notebook. Experts adjust parameters within the notebooks, along with links to the content examples. Machines create and evaluate ML models, updating results in the notebooks. Notebooks also allow the human experts access when the ML models don’t reach consensus – so people can jump in quickly. Jupyter notebooks as one part configuration file, one part data sample, one part structured log, one part data visualization tool.
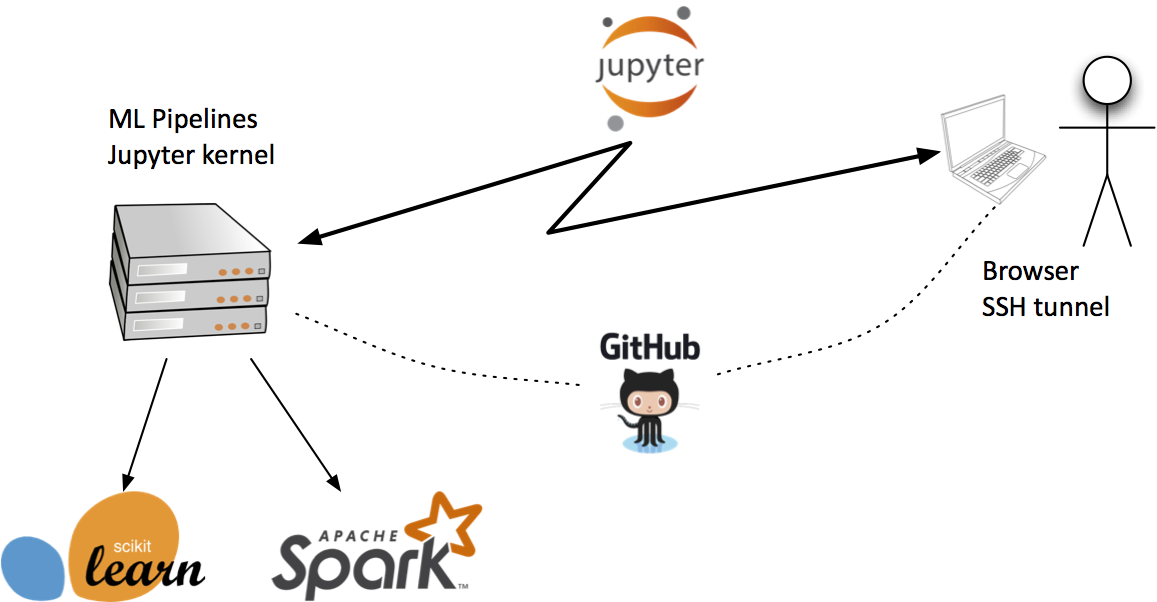
O’Reilly Media started a small open source project for machines and humans collaborating, or human-in-the-loop, using Juypter. It’s called nbtransom – available on GitHub and PyPi. Stated another way, both the machines and the people become collaborators on shared documents. Think “Google Docs”. This work anticipates upcoming collaborative document features in JupyterLab – see "Realtime collaboration for JupyterLab using Google Drive" by Ian Rose at UC Berkeley.
We’ll be presenting more about this in the upcoming talk "Humans in the Loop" at JupyterCon on Aug 24 in NYC.
Hope to see you there!
Domino Note: With one click, launch Jupyter in Domino's Data Science Platform.

Paco Nathan is the Managing Partner at Derwen, Inc. Known as a "player/coach", with core expertise in data science, cloud computing, natural language, graph technologies; Paco has 40+ years in tech industry experience, ranging from Bell Labs to early-stage start-ups. He is an advisor for Amplify Partners, Recognai, KUNGFU.AI. Paco previously was the Director, Community Evangelism at Databricks and Apache Spark.



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.