Highlights from the Maryland Data Science Conference: Deep Learning on Imagery and Text
Domino2019-03-06 | 11 min read

Niels Kasch, cofounder of Miner & Kasch, an AI and Data Science consulting firm, provides insight from a deep learning session that occurred at the Maryland Data Science Conference.
Introduction
This blog recaps Miner & Kasch’s first Maryland Data Science Conference hosted at UMBC and dives into the Deep Learning on Imagery and Text talk presented by Florian Muellerklein and Bryan Wilkinson.
Data science is an exciting, fast growing and challenging area, so it seemed fitting to host the conference at a top-notch school that is ranked ninth among the nation’s Most Innovative Schools. (You may also remember UMBC from the miracle at the 2018 NCAA Tournament.) And yeah ... Miner & Kasch was founded by UMBC alumni.
For the conference, we brought industry and academia together on the latest developments and cutting-edge science in machine learning, artificial intelligence and data platforms. We focused on practitioners of the trade -- data scientists, business managers, entrepreneurs, ML engineers, as well as students -- to present and discuss real-life problems folks face in industry and cutting-edge research in academia.

The conference was not without hiccups. For starters, a huge snow and ice storm forced us to cancel the original event. But despite the snow cancellation and the following rescheduling nightmares (PM me if you want to hear more about our graceful recovery from the missing lunches), we filled up the concert hall at UMBC’s brand new Performing Arts and Humanities Building.
The conference topics and lineup of speakers ranged from:
- Cutting-edge Deep Learning Techniques, with Dr. Frank Ferraro from UMBC on Neural Semantic Methods for Approachable Fact Prediction and Verification and Google’s Dr. Marc Pickett on Continual Learning.
- Industry talks, such as TRowe’s Erik von Heijne on Textual Data in Quantitative Finance Research and geospatial intelligence startup GeoSpark’s Serena Kelleher-Vergantini and Brendan Slezak on Gauging Geopolitical Risk with Machine Learning and Open Source Data.
- Data Platform Talks, including Databricks’ Jordan Martz on Large-scale Data Analysis with Apache Spark, Miner & Kasch’s Tim Burke on conducting Data Science in the Cloud, Corey Nolet on NVidia’s latest DL framework
- Outlook, with Justin Leto, Big Data & AI: State of the Industry, Labor Trends and Future Outlook
Deep Learning on Imagery and Text
One outstanding talk that captured the audience’s attention and generated lots of follow-up discussions at the social hour was a deep learning-focused talk by Florian Muellerklein and Dr. Bryan Wilkinson. Their talk Deep Learning on Imagery and Text, as the name implies, focused on the latest developments in deep learning for dealing with image and text data.
The talk is particularly of interest because:
- Companies have large amounts of text data ranging from contracts and legal documents to employee surveys and social media. Companies often don’t know how to get started analyzing and getting value from this data.
- Image and video data are one of the fasted growing sources of data for companies and recent advances enable many use cases in security, quality control and retail intelligence, to name a few.
- The talk provides a great overview of the latest techniques and how machine learning practitioners can apply these techniques to their problems.
Deep Learning on Imagery
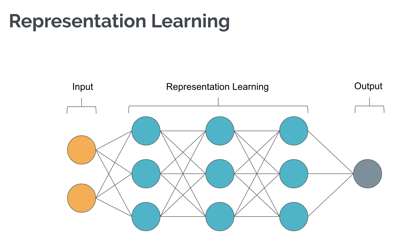
Deep learning is now frequently used for tasks such as image classification, object detection, image segmentation and image generation. Florian states in their talk that these tasks are enabled by deep learning models’ ability to learn multi-stage representations of the training data. These multi-stage representations are at the heart of improving the accuracy of models and they apply to a variety of use cases. So how does representation learning in DL work?
A deep learning model, at the basic level, consists of input layers, hidden layers and output layers. At the input, you feed the model data, aka images. The hidden layers that are responsible for learning representations “use a cascade of multiple layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input.” The output layer typically produces a class label for an image, or some other useful things about or in the image, depending on your problem setup.
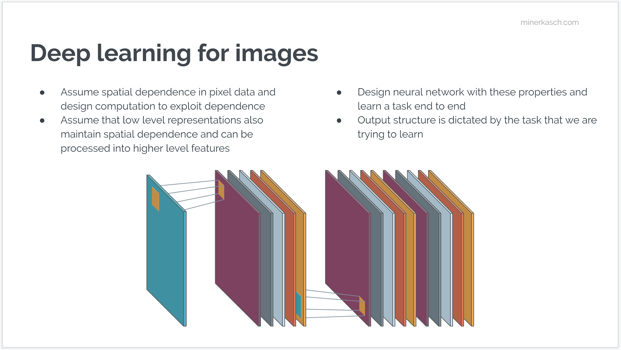
Researchers are better understanding and characterizing how model components such as different convolution operations in the hidden layers contribute to learning representations. For example, it is possible to identify parts of the network that activate for concepts like edges, lines, and curves. However, the deeper you go in the network, the more abstract representations the network learns. This is due to the design of the networks where convolving operations assume a spatial dependence between the pixels of an image -- which is certainly a reasonable assumption. A line is only a line because spatially related pixels form the line. Since the network can maintain the spatial dependence of lower-level concepts, deeper layers are able to learn high-level concepts such as what makes a face a face.
As the following animation shows, you can trace the learned representations through the different layers of the network. In the visualization, each color block represents an image category and you can see how deeper layers are successively better at identifying the essence of these components. This makes it trivial to appropriately label each image with the correct classification.
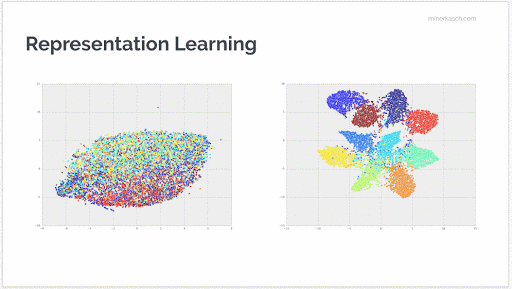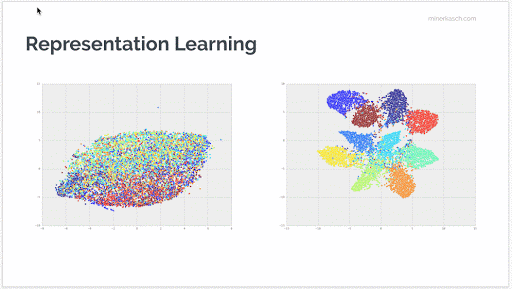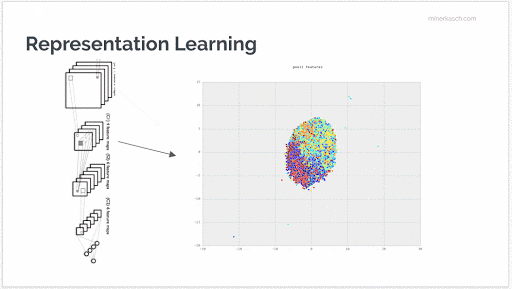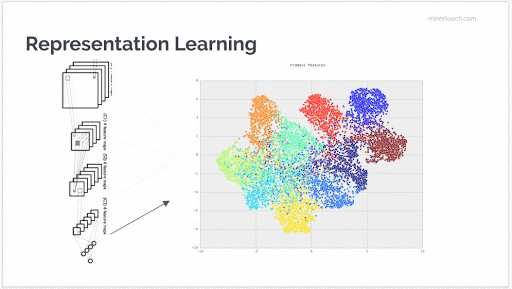
How can we use this in practice?
For one, the existing research and insights about model structure put us in a position to know which model components allow us to learn good representations of spatial/image data. We can treat model components as building blocks for the accelerated creation of new models. For example, simply replacing the output layers and appending different types of layers to the end of the ‘backbone’ layers allows us to train models on different types of tasks. This is a common practice in transfer learning.
Florian showed off a few pre-trained models like ResNet, Inception V3 and how you can exploit the representations learned by those models for your own custom machine-vision tasks without the time and cost of retraining such networks from scratch. He demonstrated those capabilities using an impressive video of real-time detection of cars in drone footage. He basically flew a drone over a neighborhood and found all the cars in the drone’s video stream. Impressive, but look for yourself.
Deep Learning on Text
While images have a native representation in the computer world -- an image is just a matrix of pixel values and GPUs are great at processing matrices -- text does not have such a native representation. The question then becomes,- how to represent text for deep learning.
Bryan went over a variety of encoding schemes to deal with the peculiar things of text with regard to different natural language processing (NLP) tasks. One widely used representation encodes words as vectors -- see below -- where each word is transformed into a vector that includes information about the word itself (e.g., capitalization patterns) and its surrounding context (e.g., the word are is preceded by elephants and followed by drinking)

One of the differentiating factors between images in text is that text in particular sentences has different lengths. Long short-term memory (LSTM) neural networks deal gracefully with this problem as they can be applied to arbitrary sized sequences. Time-series data is sequential as well, and LSTMs can help here too.
In today’s text-rich world, you can find LSTMs in all fields of NLP, including:
- Machine translation
- Question answering
- Sentiment analysis
- Grammar correction
- Information extraction
- Information retrieval
- Document classification
- Content-based recommendation systems
- Many more
The difference between these fields is how the LSTMs are used. For example, in part-of-speech tagging, where you try to identify if a word in a sentence is a verb, noun or another word class, the LSTM nodes produce an output for each word in the sequence.
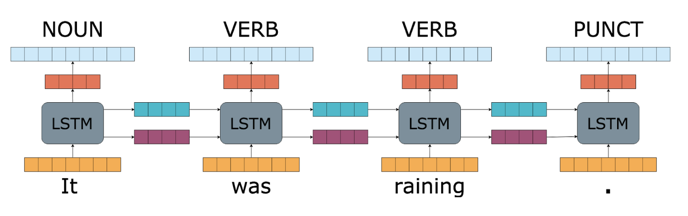
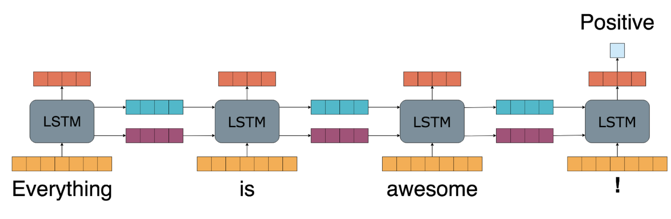
In other applications such as sentiment analysis, where you may be interested in whether a tweet has positive, negative or neutral sentiment, the LSTMs propagate their output throughout the entire sequence of words in the tweet to produce a single output.
Yet in language modeling and text generation, where you try to predict the next word in a sequence, the LSTMs are useful in modeling context around words.
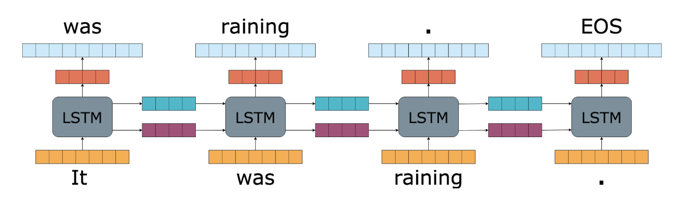
Deep learning on text has its own form of transfer learning -- well not quite transfer learning, but rather pretraining a large network on huge amounts of text, as has been done for BERT. The idea here is to create a general-purpose language model from easily available sources of text such as Wikipedia and then use this model for your specific tasks.
Brian mentioned that a pretrained model “not only improves performance” but “can reduce the number of training instances needed.” This has serious practical benefits for practitioners! As a practical example, “a pretrained ULMFIT model needed only 100 examples of labeled sentiment data to reach equal performance to a model learned from scratch trained on 10,000 labeled instances.”
What’s Next
The Deep Learning community is strong in Maryland. Our conference has been a huge success, from the number of attendees to those attendees’ diverse backgrounds. UMBC students had a field day in talking to companies and industry practitioners. We hope that many students found internships and/or received job offers.

Domino Data Lab empowers the largest AI-driven enterprises to build and operate AI at scale. Domino’s Enterprise AI Platform unifies the flexibility AI teams want with the visibility and control the enterprise requires. Domino enables a repeatable and agile ML lifecycle for faster, responsible AI impact with lower costs. With Domino, global enterprises can develop better medicines, grow more productive crops, develop more competitive products, and more. Founded in 2013, Domino is backed by Sequoia Capital, Coatue Management, NVIDIA, Snowflake, and other leading investors.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.