
This Domino Field Note provides highlights and excerpted slides from Amanda Casari’s “Feature Engineering for Machine Learning” talk at QCon Sao Paulo. Casari is the Principal Product Manager + Data Scientist at Concur Labs. Casari is also the co-author of the book, Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists. The full video of the talk is available here and special thanks to Amanda for providing permission to Domino to excerpt the talk’s slides in this Domino Field Note.
Introduction
In the talk, “Feature Engineering for Machine Learning”, Casari’s provides a definition of feature engineering; a framework for thinking about machine learning; as well as techniques including converting raw data into vectors, visualizing data in a feature space, binarization, and binning (quantization). This Domino Field Note provides distilled highlights from the talk on these topics. For additional depth including coverage on feature scaling as well as techniques for text data including bag of words, frequency-based filtering, and chunking parts of speech, the deck and full session video are publicly available.
Why Consider Feature Engineering
Casari defines a “feature” as a numeric representation and “feature engineering” as “the act of extracting those features from raw data and then transforming them into something that we can use for a machine learning model“. She indicates that “the right features can only be defined in the context of both the model and the data”.

This is important because data scientists, with feature engineering, “can make more educated choices and understanding [their] process and then hopefully that will save [them] time “as well as obtaining “more transparency into what that outcome will be and being able to have that interpretability aspect”. Casari also indicates that feature engineering enables data scientists to be “more thoughtful in thinking about the data and the features that we build…. from that, how can we maximize those features as opposed to just trying to collect more data ….to go from raw data to features in order to think about the models and the problem [we're] trying to solve”.
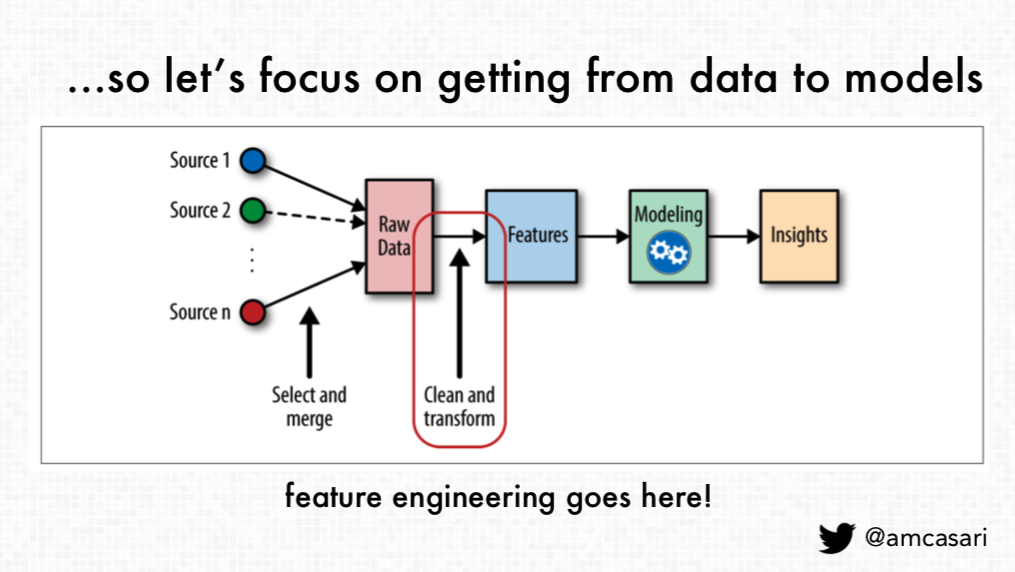
Framework for Feature Engineering
Casari also provided a feature engineering framework in her talk. The intention is to provide a way for data scientists to think about the process and techniques. The four aspects of the framework include:
- Frame your problem. Casari proposes to frame the problem in a way where machine learning has the potential to be useful. Then, data scientists will be able to mathematically model based on the framing the problem through a machine learning lens. This potentially enables people to determine the problem and whether “we can use the software we have now or that we create to solve that so in order to do that“.
- Understand your data (or the data you could potentially have). This enables data scientists to assess what would be the most useful, whether the data available is enough to address the problem they are trying to answer, and what is needed to move towards addressing the problem in the future. Also, something to consider is how the system will “will adapt and adjust over time.”
- Frame your feature goals. Casari indicates that “we need to think about what we're optimizing for …. the greatest gift that feature engineering has given me over the years is really cutting down this iteration speed“. While it is easy to utilize libraries that work with many data types, Casari advocates how it is ”more efficient to use some of those more sparse numerical representations than it is to use those richer data frames that exist and have a lot of metadata around them” and “iteration speed is critical because this is really what's going to help you move forward. The other part is going to be thinking about is model performance. The model that you're choosing, the kind of features that you're building, in order to optimize for certain kinds of models.” This helps avoid stress on the model and a potentially useless result.
- Test, Iterate, Test Again. In the final aspect of the proposed framework, Casari indicates that data scientists will test the choices for robustness, validate the choices, and realize that, results will change because the reality around the system or model changes. Casari advocates having both the processes and mindset in place that you can continue to adjust for this.”

Context On A Few Techniques
The bulk of Casari’s session focused on providing mathematical context (i.e., principles, how it will impact work, use cases, etc.) regarding a few different techniques as applied versions of the techniques covered are available in the GitHub repo. This Field Note covers vector space to feature space, binarization, and a high-level overview of binning. Additional in-depth coverage on techniques including more counts, feature scaling, bag of words, frequency-based filtering, and chunking are covered in the video and the book.
Vectors and Spaces
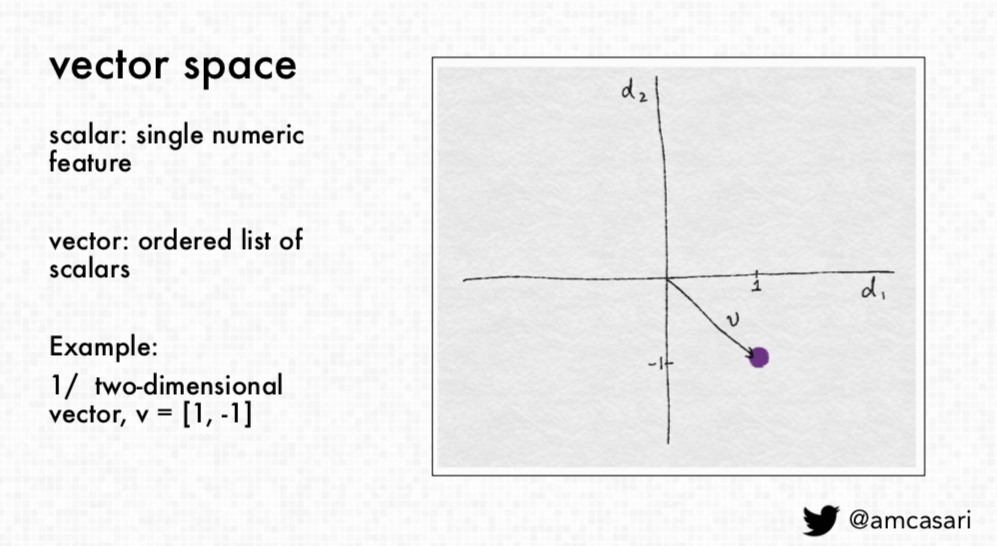
Casari indicates that in computer science, a scaler is
“is a single numeric feature and then when we have an ordered list of scalars, this is known as a vector. So now we're going to be talking about vector space so we can represent these vectors, like a two-dimensional vector V, can be represented in now what we call vector space.”
This is important as
“a majority of machine learning applications the input to the model is usually represented as a numeric vector. So, if you're struggling or getting errors or tried to work on something really understand that that model is expecting this representation…. if you don't have that present then you're going to start running into some problems from the beginning.”
Casari also indicates that “when we move from vector space, or from data space, to feature space …then we're talking more about the representation of what that's supposed to mean as opposed to just a numeric vector.” The vector is able to take on information and meaning.
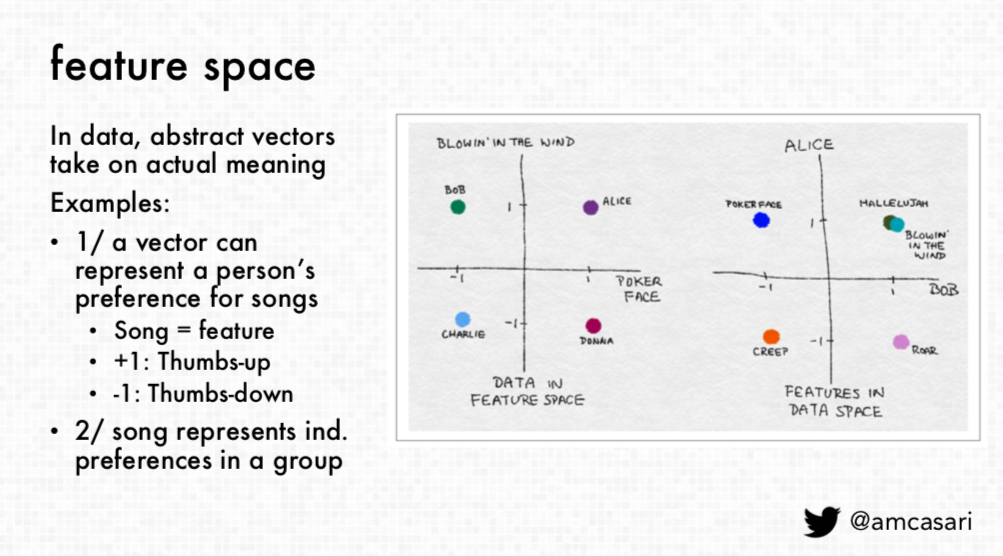
This provides an understanding of
“how we can take information and have that be represented as a person's preference and songs… here was the idea that if the song is the feature that we're trying to get, then we can represent that as either a plus one somebody likes it, or as a negative one someone doesn't like that song…. then we can start moving from data and feature space ….and then features back to data space.“
She also notes that “the difference here is going to be the point representation as well as the axis that it represents”.
Counts: Binarization and Binning
Casari indicates that there is more to count data than raw counts. While Casari covers many aspects, this blog post will provide highlights on how binarization and binning are techniques useful for addressing count data. Binarization is the process of converting raw data into binary values to “efficiently represent raw data as a presence”. For example, this is potentially useful when making song recommendations. Instead of focusing on one the raw counts or the number of times someone listened to a song, it is potentially useful to consider “the effectiveness of scale” and how “ it's probably more efficient just to understand someone likes or does not like a song and then you can represent that as a 0 or 1”. This technique provides “more efficient representation of the raw count as well as a more robust measure of the raw count”.
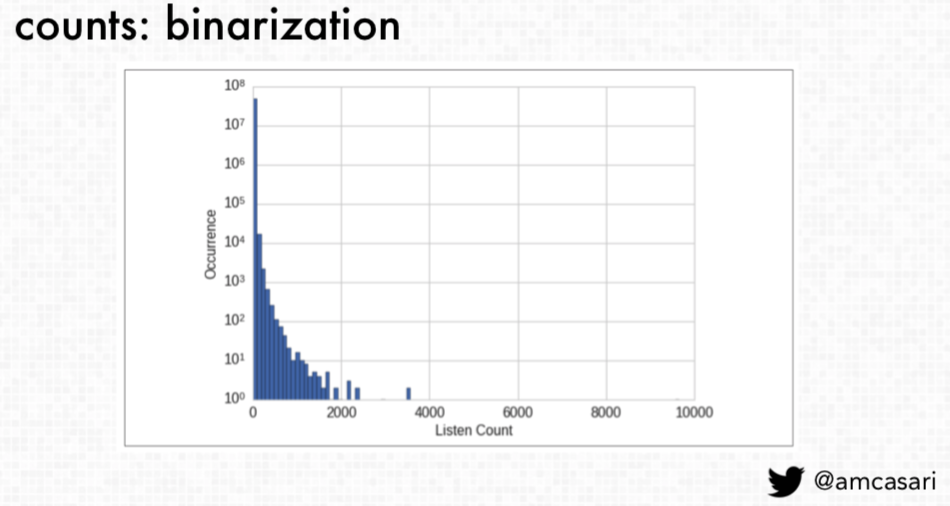
Binning, or quantizing, is a technique that groups counts into a number of “bins” that remove count values. This technique is useful to contain the scale as “a lot of machine learning models have a real challenge dealing with these long-tail distributions so when you have raw counts that span several orders of magnitude that exist within the variable you're trying to work with, and it's better to start looking at how you can transform this feature and how you can contain the scale by quantizing the count”.
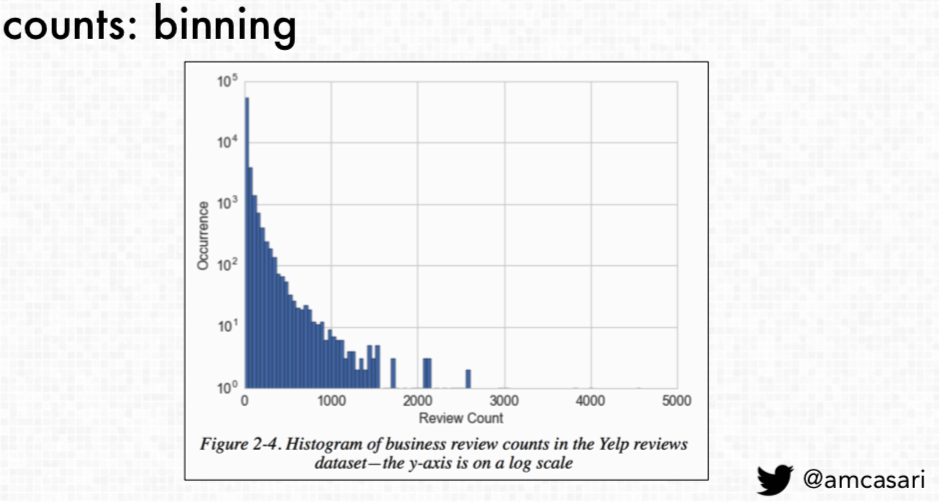
To determine the width of each bin, there are two categories: fixed-width binning and adaptive binning. Fixed-width binning is “each bin is now going to have the data that contains within a specific range…so really just taking data and putting it into buckets with other data like that and reducing the amount of complexity that exists in the space”. Casari notes that how fixed-width binning is useful in
“evaluations of health or trying to understand like disease modeling. It might make more sense to look at things like across a lifespan the different stages of life and development in which case you may have bends that are as small as months years or decades…. understand that when you're looking at the binning you should really try to look more at the context of the variable underneath it”.

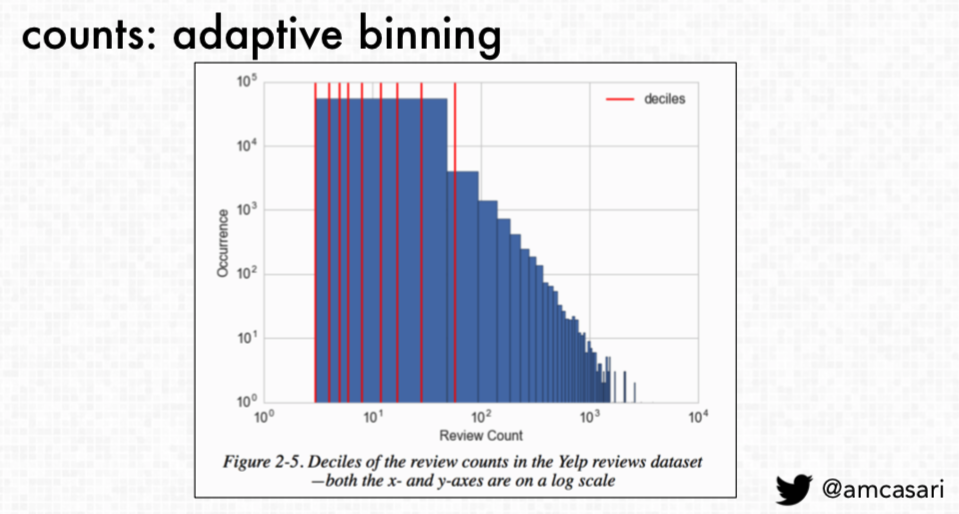
Yet, what happens when there are empty bins with no data? Casari indicates that “adaptive binning is looking at things more like quantiles or deciles. So, taking 10% 20% 30% actually looking at the distribution and grouping it that way” as it allows for easier understanding and captures, at a high level, a clearer picture of the skew.
Conclusion
This Domino Data Science Field Note provides distilled highlights of Casari’s talk, “Feature Engineering for Machine Learning”. Highlights in this blog post include a feature engineering framework as well as an overview of binarization and binning. For additional coverage and depth on techniques that include feature scaling, bag of words, frequency-based filtering, and chunking parts of speech, visit the deck and video.
Domino Data Science Field Notes provide highlights of data science research, trends, techniques, and more, that support data scientists and data science leaders accelerate their work or careers. If you are interested in your data science work being covered in this blog series, please send us an email at writeforus(at)dominodatalab(dot)com.

Ann Spencer is the former Head of Content for Domino where she provided a high degree of value, density, and analytical rigor that sparks respectful candid public discourse from multiple perspectives, discourse that’s anchored in the intention of helping accelerate data science work. Previously, she was the data editor at O’Reilly, focusing on data science and data engineering.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.