Announcing Enhanced Apache Spark Support
Eduardo Ariño de la Rubia2016-06-30 | 4 min read
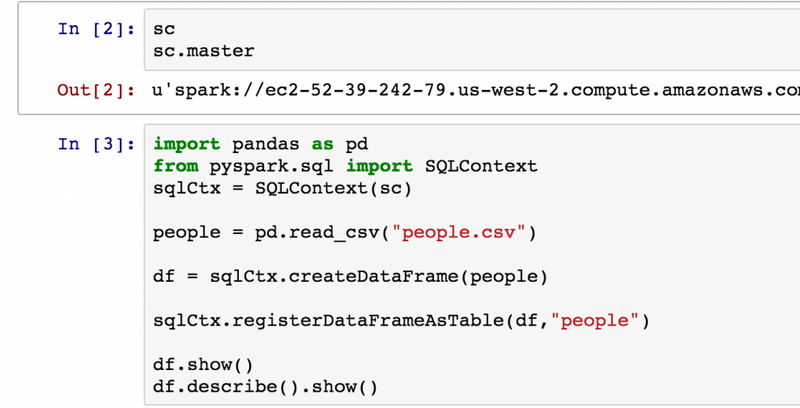
Domino now offers data scientists a simple, yet incredibly powerful way to conduct quantitative work using Apache Spark.
Apache Spark has captured the hearts and minds of data professionals. A technology originally developed at Berkeley’s AMP lab, Spark provides a series of tools which span the vast challenges of the entire data ecosystem. Spark offers support for ingestion of real-time data via streaming, for large-scale distributed ETL, and even for analysis and modeling with MLLib and the newly added data frames API.
At Domino, we feel that modern data science teams are fundamentally polyglot ecosystems, where many different tools with different philosophical and architectural approaches play an important role. While Domino has long had the ability to run code which triggered Spark jobs and connected to SparkSQL data sources, we're proud to announce significantly enhanced Spark support:
- Broad deployment and configuration support, with local mode and stand-alone cluster mode available today, and YARN support available in the next few weeks.
- Project-level Spark configurations, allowing individual projects access to different Spark clusters, and even different Spark versions, all from a drop-down menu. All dependencies are automatically installed, and no further configuration is required.
- Jupyter notebooks for Python kernels are automatically preconfigured and the SparkContext object is available to your code.
This technology preview will be further enhanced over the next few months, with SparkR support and enterprise authentication available soon.
Simple Configuration
As mentioned above, individual projects may have their own Spark integration enabled. This allows organizations considerable flexibility in deciding how data scientists should interact with data. Many of our customers are evaluating approaches to using Spark, and often have multiple different configurations that they are experimenting with. By making it possible to connect each project to a different Spark cluster, organizations can use Domino to rapidly iterate the investigation.
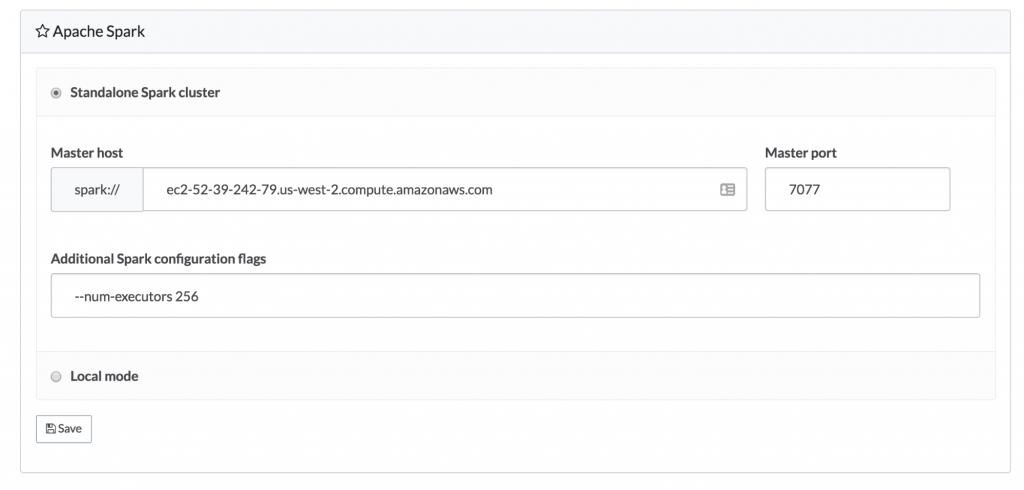
Easy Environment Management
Many organizations utilize a number of different Spark versions. Domino helps manage this complexity via our Domino Environments functionality. Domino Environments allow customers to re-use provided or custom docker images without managing any infrastructure, it’s available via a simple dropdown. Users can just configure a project’s target Spark version by selecting the correct environment.
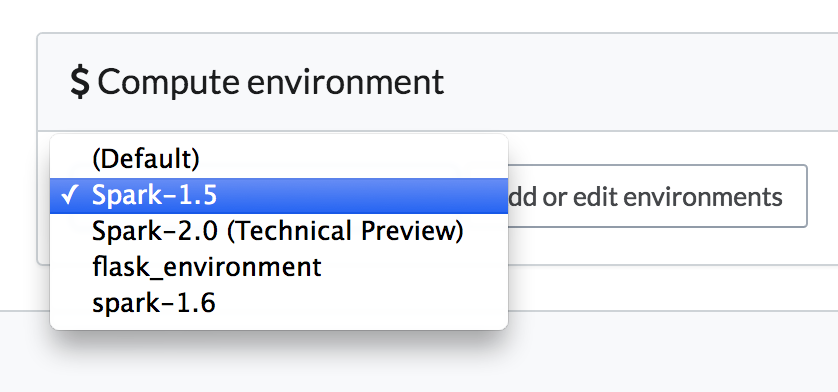
In organizations where Spark is already an established technology, the default Domino environment may be preloaded with all necessary libraries.
No-configuration Notebooks
Data scientists can now launch Jupyter notebooks and immediately interact with Spark clusters via PySpark or SparkSQL. Further configuration and authentication are not required, and the SparkContext object is immediately available for use.
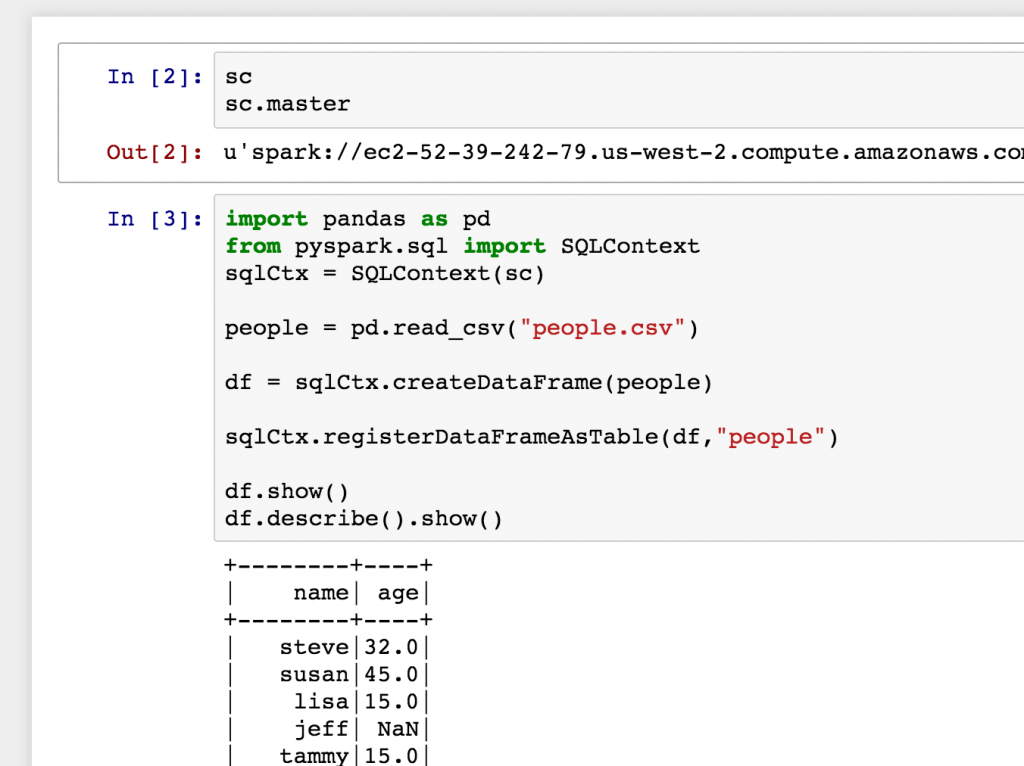
As mentioned above, we will soon be releasing support for SparkR, as well as for more complex Spark configurations using enterprise authentication.
We'd Love to Hear From You!
Apache Spark has a large, complex and rapidly evolving ecosystem. We are excited to work with our customers and discover together what it takes to integrate Spark into a modern data science practice. We'd love to hear from you how you believe we should evolve Domino's Spark support to meet this objective.

Eduardo Ariño de la Rubia is a lifelong technologist with a passion for data science who thrives on effectively communicating data-driven insights throughout an organization. A student of negotiation, conflict resolution, and peace building, Ed is focused on building tools that help humans work with humans to create insights for humans.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.