Domino Data Science Blog

Nikolay Manchev
Nikolay Manchev is the Principal Data Scientist for EMEA at Domino Data Lab. In this role, Nikolay helps clients from a wide range of industries tackle challenging machine learning use-cases and successfully integrate predictive analytics in their domain specific workflows. He holds an MSc in Software Technologies, an MSc in Data Science, and is currently undertaking postgraduate research at King's College London. His area of expertise is Machine Learning and Data Science, and his research interests are in neural networks and computational neurobiology.
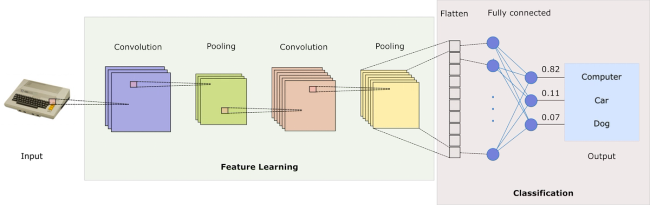
GPU-accelerated Convolutional Neural Networks with PyTorch
Convolutional Neural Networks (CNNs and also ConvNets) is a class of Neural Networks typically used for image classification (mapping image data to class values). At a high level, CNNs can be viewed simply as a variant of feedforward networks, but they have a number of advantages in comparison to more traditional algorithms for analysing visual imagery.
By Nikolay Manchev13 min read

Eight Considerations When Choosing a Data Store for Data Science
Selecting the right technology that enables data scientists to focus on data science and not IT infrastructure will help enterprises reap the benefits of their investments in data science and machine learning.
By Nikolay Manchev18 min read

How data science can fail faster to leap ahead
One of the biggest challenges in data science today is finding the right tool to get the job done. The rapid change in best-in-class options makes this especially challenging - just look at how quickly R has fallen out of favor while new languages pop up. If data science is to advance as rapidly as possible in the enterprise, scientists need the tools to run multiple experiments quickly, discard approaches that aren’t working, and iterate on the best remaining options. Data scientists need a workspace where they can easily experiment, fail quickly, and determine the best data solution before they run a model through certification and deployment.
By Nikolay Manchev8 min read
Speeding up Machine Learning with parallel C/C++ code execution via Spark
The C programming language was introduced over 50 years ago and it has consistently occupied the most used programming languages list ever since. With the introduction of the C++ extension in 1985 and the addition of classes and objects, the C/C++ pair keep a central role in the development of all major operating systems, databases, and performance critical applications in general. Because of its efficiency, C/C++ underpin a large number of machine learning libraries (e.g. TensorFlow, Caffe, CNTK) and widely used tools (e.g. MATLAB, SAS). C++ may not be the first thing that springs to mind when thinking about Machine Learning and Big Data, but it is omnipresent everywhere in the field where lightning fast computations are needed - from Google's Bigtable and GFS to pretty much everything GPU related (CUDA, OCCA, openCL etc.)
By Nikolay Manchev12 min read

Semi-uniform strategies for solving K-armed bandits
In a previous blog post we introduced the K-armed bandit problem - a simple example of allocation of a limited set of resources over time and under uncertainty. We saw how a stochastic bandit behaves and demonstrated that pulling arms at random yields rewards close to the expectation of the reward distribution.
By Nikolay Manchev6 min read

Polars - A lightning fast DataFrames library
We have previously talked about the challenges that the latest SOTA models present in terms of computational complexity. We've also talked about frameworks like Spark, Dask, and Ray, and how they help address this challenge using parallelization and GPU acceleration.
By Nikolay Manchev7 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.