
This Domino Data Science Field Note provides highlights and excerpted slides from Chloe Mawer’s "The Ingredients of a Reproducible Machine Learning Model" talk at a recent WiMLDS meetup. Mawer is a Principal Data Scientist at Lineage Logistics as well as an Adjunct Lecturer at Northwestern University. Special thanks to Mawer for the permission to excerpt the slides in this Domino Data Science Field Note. The full deck is available here.
Introduction
Chloe Mawer presented "The Ingredients of a Reproducible Machine Learning Model" talk at a recent WiMLDS meetup. Mawer's talk provided pragmatic insights and best practices for easing the development and deployment of reproducible models. This post covers distilled highlights from the talk including "why is reproducibility so hard?", why versioning code is not enough, as well as Mawer's reproducible model template. For more insights from the talk including model testing, environment management, and code alignment, review Mawer's full interactive deck and additional context on the reproducibility template. I attended the machine learning meetup and reached out to Mawer for the permissions to excerpt Mawer's work for this blog post. Many thanks to Mawer for the appropriate permissions and for feedback on this post prior to publication.
Why is Reproducibility so Hard?
While Mawer is currently a Principal Data Scientist at Lineage Logistics as well as an Adjunct Lecturer at Northwestern University, Mawer also drew from prior consulting experience to relay implications of irreproducibility and examples of "why reproducibility is so hard". In a prior consulting role, Mawer worked on a project where the original person, who built the system of algorithms that her team was meant to iterate on and add to, no longer worked at the company. There was little to no documentation, comments, context, etc. Making reproducing the algorithms impossible. This inability to understand how the current algorithms worked significantly slowed down the ability to improve upon them and made deploying any improvements almost impossible without breaking the system.
While not an ideal situation, it is a common one that many researchers and data scientists face when seeking to move data science work forward. Audience meetup responses to these pain point slides included snickers of recognition, sighs, and taking pictures of said slides with their phones. Mawer also reiterated how these pain points are not new or local but are globally known with a nod to "How to write unmaintainable code" by Rodey Green.

One of the big problems seen when trying to deploy machine learning models is the inability to reproduce the same predictions as in development. Slide Credit and Image Credit.

Slide Credit and Image Credit.
Then Mawer touched upon how reproducibility is hard because there are many, seemingly random, points where reproducibility can potentially break as well as the path of developing and deploying a model is long.

"The Path is Long"
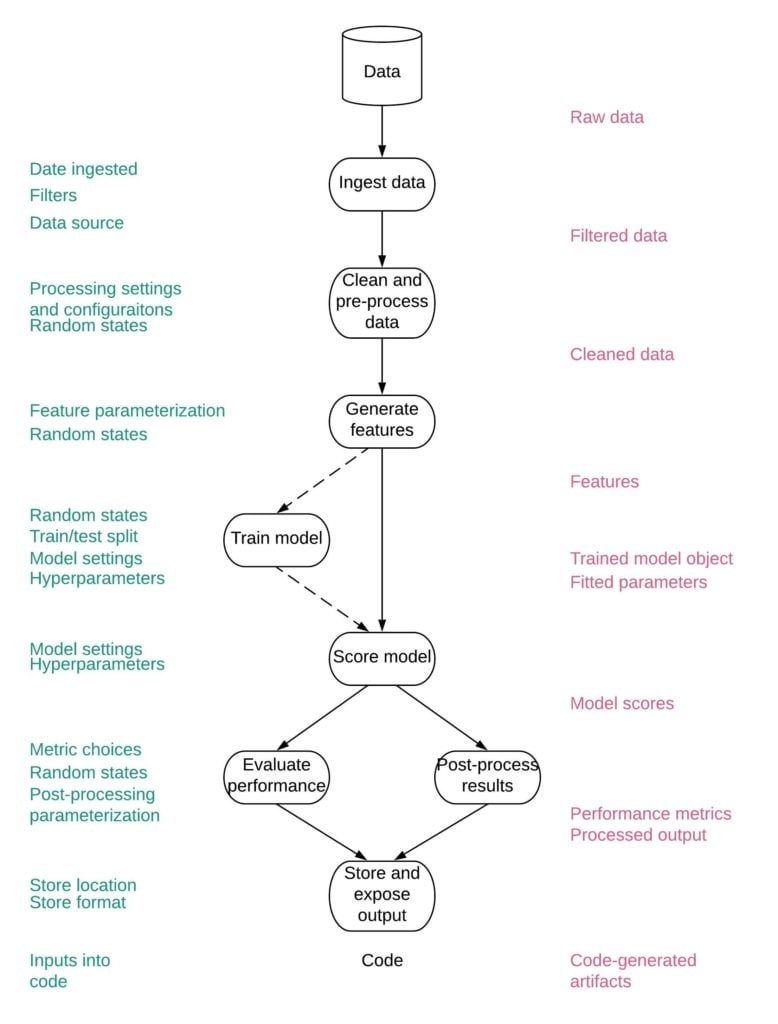
"The Path is Long" Slide Credit and Image Credit.
The longer the path, the more components and opportunities are provided to ease or break reproducibility.
Addressing Irreproducibility in the Wild
After Mawer covered the pain points related to irreproducibility, Mawer provided pragmatic advice on how to address irreproducibility including "find[ing] every random state and parameterize it" and just "versioning code is not enough".
Mawer's interactive "Parameters and Settings" slide has been extracted and reformatted below to ease readability.
model:name: example-modelauthor: Chloe Mawerversion: AA1description: Predicts a random result given some arbitrary data inputs as an example of this config filetags:- classifier- housingdependencies: requirements.txtload_data:how: csvcsv:path: data/sample/boston_house_prices.csvusecols: [CRIM, ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO, B, LSTAT]generate_features:make_categorical:columns: RADRAD:categories: [1, 2, 3, 5, 4, 8, 6, 7, 24]one_hot_encode: Truebin_values:columns: CRIMquartiles: 2save_dataset: test/test/boston_house_prices_processed.csvtrain_model:method: xgboostchoose_features:features_to_use: [ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO]get_target:target: CRIMsplit_data:train_size: 0.5test_size: 0.25validate_size: 0.25random_state: 24save_split_prefix: test/test/example-bostonparams:max_depth: 100learning_rate: 50random_state: 1019fit:eval_metric: aucverbose: Truesave_tmo: models/example-boston-crime-prediction.pklscore_model:path_to_tmo: models/example-boston-crime-prediction.pklpredict:ntree_limit: 0save_scores: test/true/example-boston-test-scores.csvevaluate_model:metrics: [auc, accuracy, logloss]Mawer also referenced how YAML configuration files are useful for model training and scoring. Pulling out all possible configurations into one file enables them to be versioned along with the code at the time of model training, which is a major step to being able to reproduce the model training and scoring pipelines. Like JSON, YAML files can easily be read into Python as a dictionary but unlike JSON, a YAML file is human-readable, allowing easy changing of configurations all in one place. Additionally, pulling out all configurations from the code puts the decisions that were made in the building of the model pipeline all in one place. Such decisions can be forgotten over time if strewn through various scripts. Their centralized declaration ensures parameterizations and configurations are kept in line with the code’s future applications. Lastly, Mawer notes that once you make your entire model training and scoring pipelines entirely configurable, it is extremely easy to iterate during model development with just a quick change of the YAML file to try out different models, features, hyperparameters, and more.
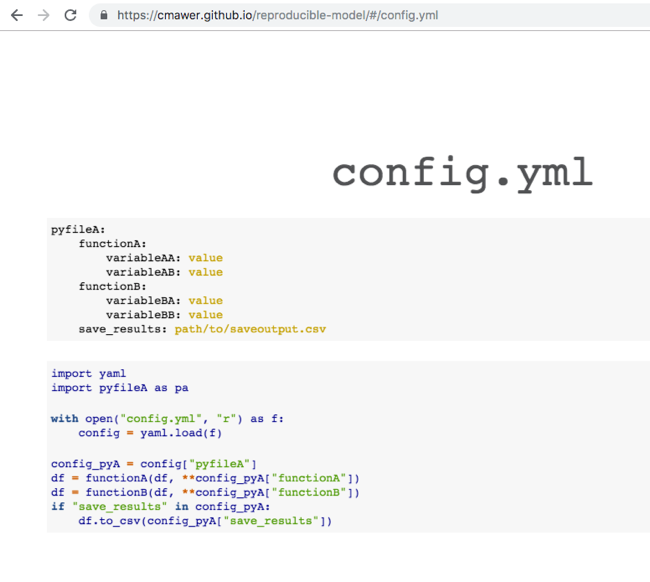
"Mawer suggests structuring yaml configuration files with the Python script names and function names that the parameters are passed into as the keys. This structure makes it clear how to use them once imported into a Python script." Slide Credit.
Mawer also referenced some insights about data and features including
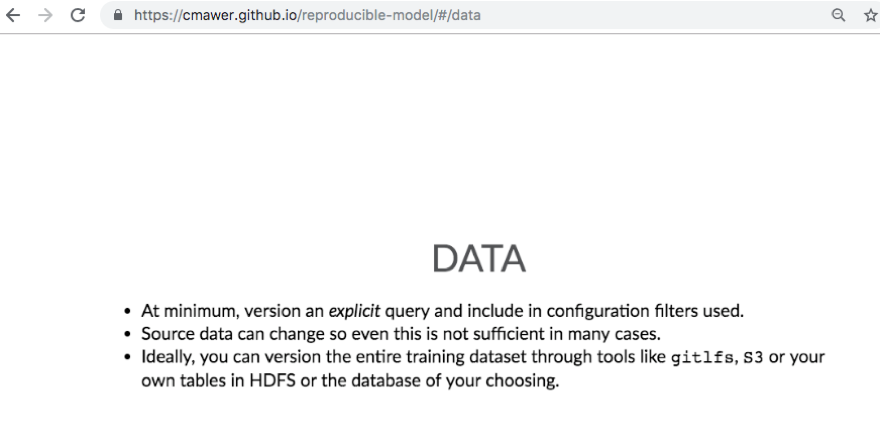

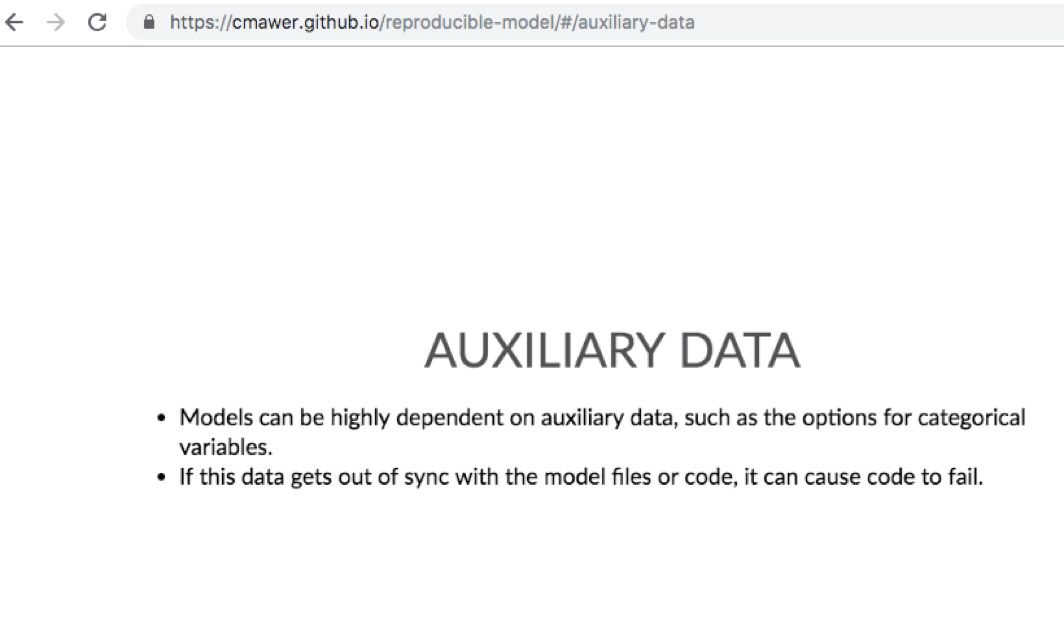
Additional pragmatic insights on model testing, environment management, and code alignment are available in the full interactive deck.
Reproducible Template
Mawer also referenced the availability of a reproducible model template in the talk. The reproducible model template is excerpted and reformatted below to ease readability.
├── README.md <- You are here
│
├── config <- Directory for yaml configuration files for model training, scoring, etc
│ ├── logging/ <- Configuration of python loggers
│
├── data <- Folder that contains data used or generated. Only the external/ and sample/ subdirectories are tracked by git.
│ ├── archive/ <- Place to put archive data is no longer usabled. Not synced with git.
│ ├── external/ <- External data sources, will be synced with git
│ ├── sample/ <- Sample data used for code development and testing, will be synced with git
│
├── docs <- A default Sphinx project; see sphinx-doc.org for details.
│
├── figures <- Generated graphics and figures to be used in reporting.
│
├── models <- Trained model objects (TMOs), model predictions, and/or model summaries
│ ├── archive <- No longer current models. This directory is included in the .gitignore and is not tracked by git
│
├── notebooks
│ ├── develop <- Current notebooks being used in development.
│ ├── deliver <- Notebooks shared with others.
│ ├── archive <- Develop notebooks no longer being used.
│ ├── template.ipynb <- Template notebook for analysis with useful imports and helper functions.
│
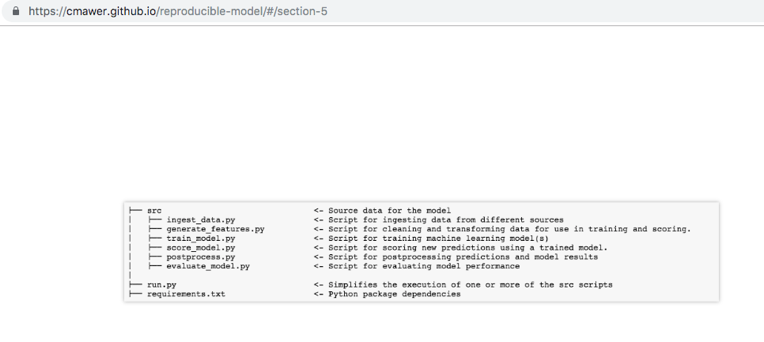
├── src <- Source data for the sybil project
│ ├── archive/ <- No longer current scripts.
│ ├── helpers/ <- Helper scripts used in main src files
│ ├── sql/ <- SQL source code
│ ├── ingest_data.py <- Script for ingesting data from different sources
│ ├── generate_features.py <- Script for cleaning and transforming data and generating features used for use in training and scoring.
│ ├── train_model.py <- Script for training machine learning model(s)
│ ├── score_model.py <- Script for scoring new predictions using a trained model.
│ ├── postprocess.py <- Script for postprocessing predictions and model results
│ ├── evaluate_model.py <- Script for evaluating model performance
│
├── test <- Files necessary for running model tests (see documentation below)
│ ├── true <- Directory containing sources of truth for what results produced in each test should look like
│ ├── test <- Directory where artifacts and results of tests are saved to be compared to the sources of truth. Only .gitkeep in this directory should be synced to Github
│ ├── test.py <- Runs the tests defined in test_config.yml and then compares the produced artifacts/results with those defined as expected in the true/ directory
│ ├── test_config.yml <- Configures the set of tests for comparing artifacts and results. Currently does not include unit testing or other traditional software testing
│
├── run.py <- Simplifies the execution of one or more of the src scripts
├── requirements.txt <- Python package dependencies Conclusion
Seek Truth, Speak Truth is one of Domino's core values. Dominoes, including myself, live this value by actively seeking out and listening to people within data science including the speakers and attendees at the WiMLDS meetup. The questions and insights we gather and ingest from actively listening to industry helps inform our platform, products, and services. Yet, we also hope to contribute to the public discourse about reproducibility by amplifying and sharing research either through this blog post or our industry events. Many thanks again to Chloe Mawer for the permissions to excerpt "The Ingredients of a Reproducible Machine Learning Model". As this post provided distilled highlights on why reproducibility is hard and some pragmatic advice for addressing irreproducibility, additional insights regarding model testing, environment management, and code alignment are available in the full deck.
Domino Data Science Field Notes provide highlights of data science research, trends, techniques, and more, that support data scientists and data science leaders accelerate their work or careers. If you are interested in your data science work being covered in this blog series, please send us an email at content(at)dominodatalab(dot)com.

Ann Spencer is the former Head of Content for Domino where she provided a high degree of value, density, and analytical rigor that sparks respectful candid public discourse from multiple perspectives, discourse that’s anchored in the intention of helping accelerate data science work. Previously, she was the data editor at O’Reilly, focusing on data science and data engineering.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.