Data Science Platform: What is it? Why is it Important?
Nick Elprin2016-07-28 | 7 min read

As more companies recognize the need for a data science platform, more vendors are claiming they have one. Increasingly, we see companies describing their product as a data science platform without describing the features that make platforms so valuable. So we wanted to share our vision for the core capabilities a platform should have in order for it to be valuable to data science teams.
First let's define data science platform then dive into the details:
Data Science Platform (Definition)
A data science platform is software that unifies people, tools, artifacts, and work products used across the data science lifecycle, from development to deployment. Organizations use data science platforms to create more maturity and discipline around data science as an organizational capability, instead of only a technical skill.
Now let's examine why this is the case and why it's important:
Framework: The Data Science Lifecycle
We see "the data science lifecycle" spanning three phases. Each phase has distinct demands that motivate capabilities for a data science platform:
- Ideation and exploration
- Experimentation & model development
- Operationalization / deployment
To some degree, all data science projects go through these phases.
- Additionally, there is an underlying perspective that spans across this lifecycle: the need to manage, scale, and evolve your analyses and your organization's capabilities.
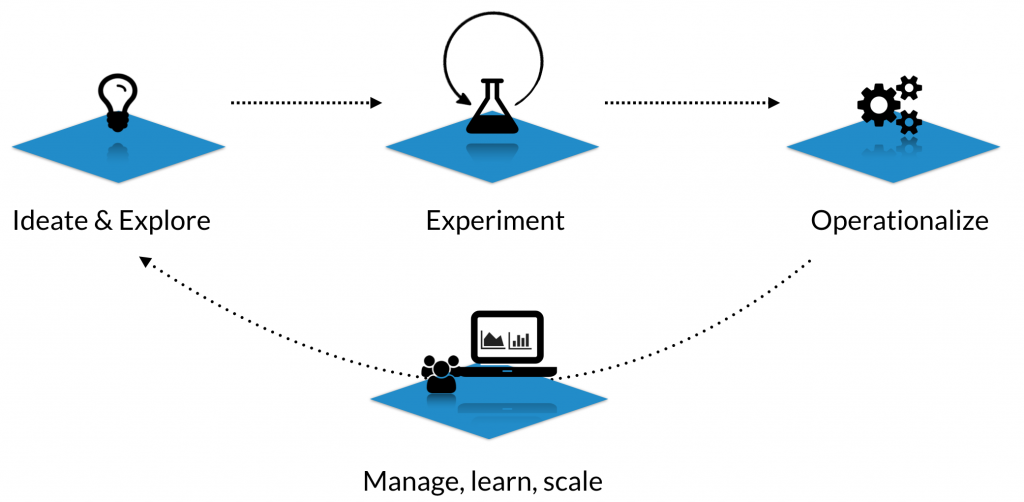
We'll discuss these four lenses, describing the challenges involved in each, and what capabilities a good data science platform should provide.
Ideation and Exploration
Quantitative research starts with exploring the data to understand what you have. This might mean plotting data in different ways, examining different features, looking at the values of different variables, etc.
Ideation and exploration can be time-consuming. The data sets can be large and unwieldy, or you may want to try new packages or tools. If you’re working on a team, unless you have ways of seeing work others have already done, you might be redoing work. Other people may have already developed insights, created clean data sets, or determined which features are useful and which are not.
A Good Data Science Platform Should Make It Easy to...
- Find and understand past work, so that data scientists don't need to start from scratch when asking new questions.
- Explore data on large machines, without dealing with dev ops / infrastructure setup.
- Use new packages and tools, safely, i.e., without breaking past work or disrupting environments for colleagues.
Experimentation & Model Development
Through the process of exploring data, researchers formulate ideas they want to test. At this point, research often shifts from ad hoc work in notebooks to more hardened, batch scripts. People run an experiment, review the results, and make changes based on what they’ve learned.
This phase can be slow when experiments are computationally intensive (e.g., model training tasks). This is also where the "science" part of data science can be especially important: tracking variations in your experiments, ensuring past results are reproducible, getting feedback through a peer review process.
A Good Data Science Platform Should Make It Easy to...
- Scale out compute resources to run many computationally intensive experiments at once.
- Track your work (i.e., your experiments) so they are reproducible.
- Share work with peers and non-technical colleagues (with other areas of expertise), to get feedback on evolving research and results
Operationalization
Data science work is only valuable insofar as it creates some impact on business outcomes. That means the work must be operationalized or productionized somehow, i.e., it must be integrated into business processes or decision-making processes. This may be in the form of a predictive model exposed as an API, a web application for people to interact with, or a daily report that shows up in people's inboxes, for example.
Operationalizing data science work often involves engineer resources, which increase costs and delays time to market. Not only does this affect initial deployment, but if it becomes a constant tax on new iterations, it makes it more likely that models never evolve past "version 1", or it means that by the time new research makes it into production, it's already obsolete.
A Good Data Science Platform Should Make It Easy to...
- Publish models as APIs, so software systems in other languages (Java, PHP, C#, Ruby, etc.) can easily consume them without re-implementation.
- Expose work to non-technical analysts and stakeholders — as self-service tools, dashboards, static reports, etc
Manage, Learn, and Scale
In addition to helping researchers develop better models faster, platforms also bring a critical capability to teams and to managers. As companies invest more in quantitative research, they should build institutional knowledge and best practices to make the team even more effective over time.
A core value of a platform is its ability to centralize knowledge and research assets. That gives managers transparency into how people are working; it reduces key-man risk; it makes it easier to onboard people; it improves shared context, thus increasing creativity; and it accelerates the pace of research by making it possible to build upon past work rather than starting from scratch.
A Good Data Science Platform Should Make It Easy to...
- Browse or search for past work (including metadata, code, data sets, results, discussion)
- Put security boundaries around work, to ensure that it's accessible to the right people
- Build upon past work
Open vs Closed Platforms
We believe a platform should facilitate the process we described above, ultimately making it easier to build models or other data science deliverables. A relevant question that comes up comparing platforms: what tools can be used on top of the platform?
Some platforms are closed: that is, they facilitate the processes described above, but only if you are using the platform vendor's particular programming language, modeling package, or GUI tool.
We built Domino to be an open platform, committed to the goal that you should be able to choose the language(s) and packages you want to use, and that a good platform will give you that flexibility.
In our experience, an open platform is valuable for two reasons: First, it creates agility for your data scientists, making it easier for them to use the right tool for the job in different circumstances, and to experiment with new packages or languages as desired. Second, it reduces friction to adoption, because data scientists are free to keep using the same tools they're accustomed to.


Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.