
Introduction
I created a Python project that grabs Craigslist postings in New York for Macbook Air 13" and automatically shows you the best deals — deals so good they could be sold for a profit on eBay. This is a proof of concept design for a specific product and location, but the model is flexible and could be extended to other locations and/or products.
The algorithm knows how much each Macbook should be priced, based on the model year and other features. Macbooks which are priced abnormally low and undervalued given their specs are shown on a Google map so that one could have a perspective of how much time and effort they'd be willing to put in.
The algorithm exploits the opportunity of the pricing opacity on Craigslist. People often don't have a sharp eye on what price to post for their listing. They don't even know if it's competitive to other listings. This creates a perfect environment to profit from mispricings.
Motivation
I was in the market for a Macbook Air a couple months ago. But I didn't have time, data, or patience to figure out what a good deal was relative to the market. How do I know if this posting I'm looking at is a good deal or not versus everything else that's out there? is it a bargain?
And if it was a bargain, it had likely already been sold - all that time wasted sifting. I needed to develop something that would surface these gems quickly. Hence, I thought of this as a fun and useful Data Science product.
High-level approach
I considered a few approaches on how to model this problem: anomaly detection techniques, classification, or regression modeling. After much exploration, I found fitting a regression model to the data to be the most accurate.
By using the cost function mean absolute error (mae) and sorting by the negative residuals. Then validating vs eBay such that the results are filtered for only profitable items, turned out to be the best way. Thus, resulting in a list of recommendations that are optimal intramarket (Craigslist) or across-markets (eBay). Validation is done by using eBay's auction ending prices over 2-weeks (mean).
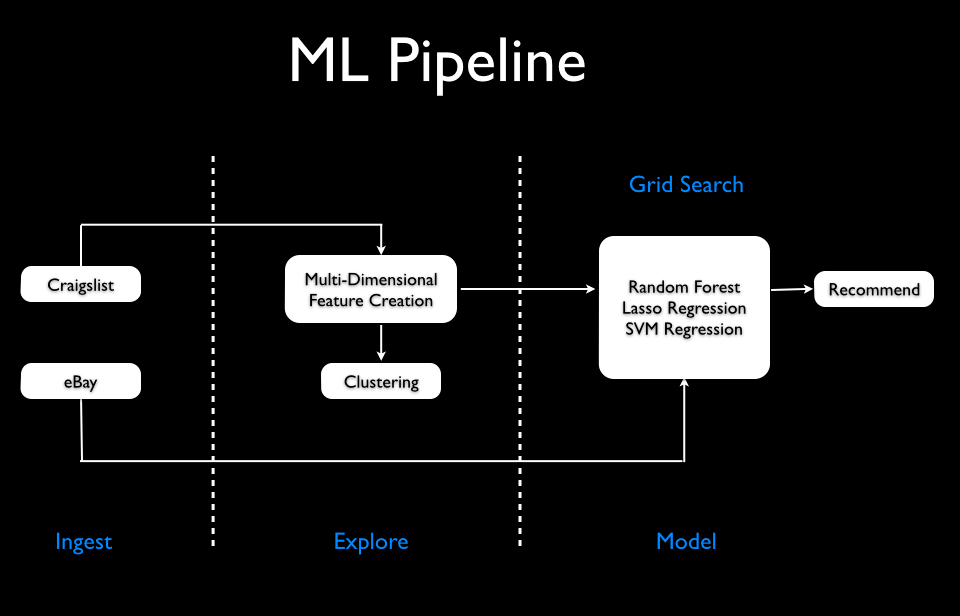
Challenges and Obstacles
Feature engineering
Finding and creating the most important features wasn't a simple task. Creating the proper feature matrix is one of the most important aspects of any machine learning pipeline - obviously, the output of your model is only as good as your inputs (feature matrix). Which features can I use or create with the most signal? what's the right data to scrape? Which city should I target? How many examples will I need?... all of which is in the realm of data 'wrangling' and 'munging'. Once I figured out what I wanted (or so I thought), I visualized the data on a scatter matrix (in sci-kit learn), which showed multiple plots of how features had correlated with each other. It's a great technique for figuring which features would yield the most information gain (signal) early on.
From a modeling perspective, 'price' was clearly explained most by 'model year'. But some Craiglist posts don't provide the model year. In lieu, people would often say 'BNIB' or 'latest model' or 'sealed in box' or some model number. To pick up on this, I basically used the help of a latent topic modeler (LDA) on the corpus of misclassified postings.
After gathering all these phrases, I built a regular expression string that captured almost everything. Some people spoke in terms of specs of their MacBook. How could I solve this issue? I could either make a regex dictionary of all the tech specs of each and every model (which I eventually did) or I could create a cosine-similarity matrix with the first few documents being official technical specs of each model and classifying each posting which had the highest similarity score accordingly.
This would make the model semi-unsupervised (for those keeping track). Though, this was an interesting approach I found the dictionary approach much more useful in implementation and even more so later for classifying it as an upgrade or base configuration. The features I ultimately ended up experimenting with and using were - model year, AppleCare, upgraded or base [cpu | ram | hd].
Learning method
A classification approach would mean manually labeling ['good deal' or 'bad deal'] — not fun. But instead of thinking about this as a "classification" problem, we can simplify it by asking, "how do we identify an underpriced item?", i.e., how do we find a data point that's outside of the norm? Anomaly detection techniques would help here - specifically, DBSCAN. One problem I faced was that the direction (too high or too low would detect regardless) of the price and its accuracy wasn't all that great. Ultimately, I found regression modeling generalized the best and was by far the simplest to implement.
Finding the model
The ideal model along with optimal parameters are grid-searched. The three we consider are: Support Vector Regressor (akin to SVM), Lasso Regression, and Random Forest Regressor.
Fitting the model
This list of recommended "good deals" is produced by first fitting a regression model to the set of feature(s) and sorting by the largest negative residual (largest positive residual gives us all overpriced deals).
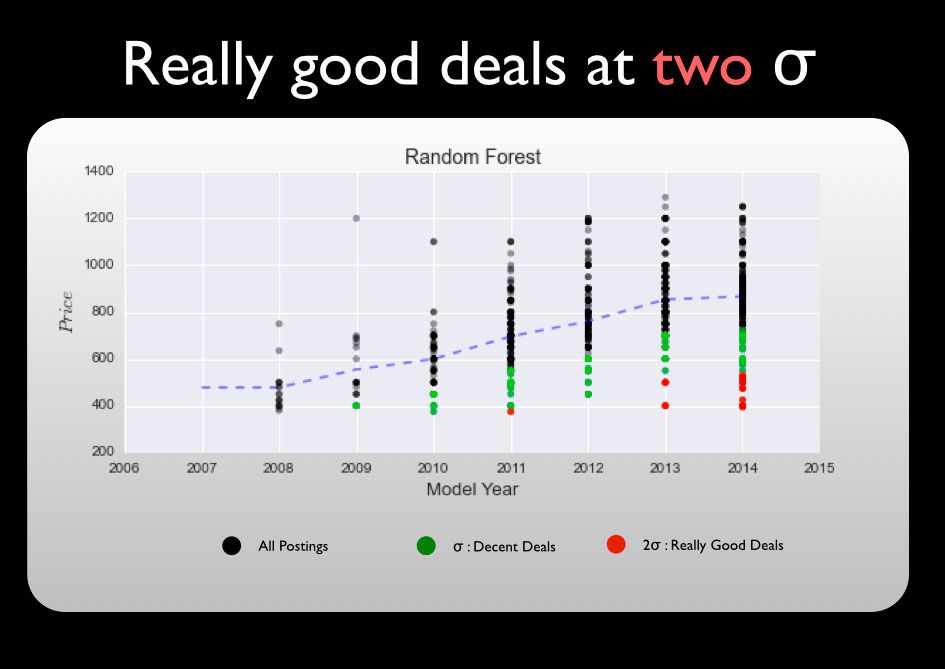
More on NLP and additional EDA
First using a posting's text (title & body) as a document within a corpus and from that constructing a TF-IDF matrix (with bigrams). With the help of a latent topic extraction method, Non-Negative Matrix Fractorization, I've uncovered some hidden gems of insight.
Search for keyword firm and avoid OBO and or best offer. Seems counterintuitive right? Postings on Craigslist are almost never paid "asking price" most of the time there's a negotiation involved. So, why would you search for something that puts a clear bottom line on how negotiable a seller might be? Turns out folks using the keyword 'firm' tend to be giving you the rock bottom price already, taking the hassle of haggling out. "OBO" and "or best offer" were common catchphrases within the overpriced deals.
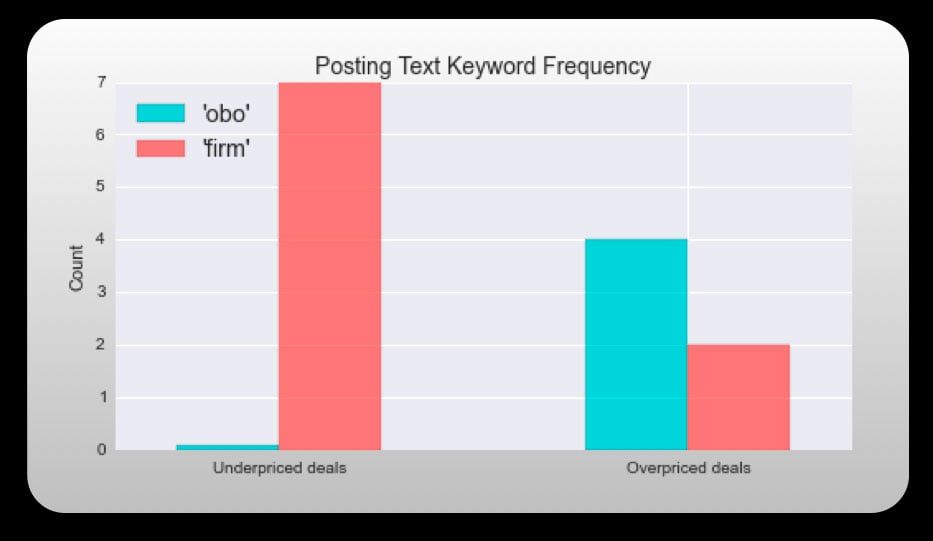
**data based on a random sample of the top/bottom 20 deals out of 470 total postings from various metropolitan cities in the U.S.*
I've also found most people who tend to price low are selling it because it was a gift. So keep this mind when you're doing Christmas shopping this year.
Thanks everyone @ Zipfian

Ajay Sharma is the Managing Member of Data Shop, a full-stack data consultancy. He has over a decade of industry experience in the machine learning and analytics space with a strong track record of success from deployed products to monetizable insights and articles.
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.