
In Paco Nathan's latest column, he explores the theme of "learning data science" by diving into education programs, learning materials, educational approaches, as well as perceptions about education. He is also the Co-Chair of the upcoming Data Science Leaders Summit, Rev.
Introduction
Welcome back to our monthly series about data science. This month, let’s explore learning data science.
Lately I’ve been developing curriculum for a client for their new “Intro to Data Science” sequence of courses. This is not a new gig, by any stretch. I’ve been teaching data science since 2008 privately for employers – exec staff, investors, IT teams, and the data teams I’ve led – and since 2013, for industry professionals in general. However, right now is an interesting point in time to consider: “What needs to be taught? What are the foundational parts of our field?”
Let’s explore those questions about learning data science and unpack that a bit. Where are the leading educational programs in data science? What are some good learning materials available to the public?
What works better among the range of online materials, in-person classes, MOOCs, bootcamps, and so on? How do options such as mentoring programs fit into this picture, both for organizations and for the individuals involved?
In business terms, why does this matter? What are the projected risks for companies that fall behind for internal training in data science? What’s a reasonably good persona to target for employees who want training in data science to shift into new roles?
And my favorite topic: what are some of the best books, blogs, podcasts, etc., for beginning study in data science?
Learning Data Science
If you’re looking for good examples of data science curriculum, for example to help train your team, where would you start?
By the numbers, arguably the biggest success in the world has been UC Berkeley Division of Data Sciences. Led by rockstars Cathryn Carson, David Culler, et al., this initiative has fundamentally changed academic programs at Berkeley. Plus, it’s been blazing a trail for other universities to follow. Educational materials are available online for their Data 8 foundations course and their Data 100 intermediate course, as well as their textbook, Inferential and Computational Thinking. These two are the fastest-growing courses in the history of Berkeley, now reaching 40% of the campus population. In addition, there’s an innovative practice of connector courses into other disciplines. The program supports hands-on data science class sizes of more than 1,200 students based on JupyterHub, and this sets a bar for enterprise infrastructure.

UC Berkeley intro data science course (credit: Fernando Pérez)
Of course not everyone is a matriculated student at UC Berkeley or one of its university partners and therefore, won’t have access to these programs. Also, clearly there’s no “one size fits all” educational model for data science. Laura Noren, who runs the Data Science Community Newsletter, presented her NYU postdoc research at JuptyerCon 2018, comparing infrastructure models for data science in research and education. The contrast of Canadian programs versus comparable efforts in the US is particularly interesting. The Berkeley model addresses large university needs in the US. However, there’s a diversity of other needs for learning data science.
Why does this matter?
First off, congrats to Berkeley. My alma mater may be located on the opposite side of the San Francisco Bay (trees vs. bears, or something) nonetheless, I’m thrilled to see their success and honored to give guest lectures in the related BIDS grad program. Permeating toolsets, skill sets, datasets, and mindsets for data science work into the hands and minds of university students – that’s outstanding. Students will have much better foundations for pursuing 21st century research, regardless of which academic fields they choose.
Different formats, different approaches
However, people who are already working in industry have other needs. Different formats for learning materials, different approaches to curriculum (e.g., more depth in the case studies), plus different styles of instruction (“ROI” gets discussed, a lot) are needed. Case in point: circa 2002 I was teaching network security in a continuing education program. People in our classes would work 8–10 hours at their jobs, then spend another three hours in the evening in our programs (if they could stay awake). They were making big sacrifices to invest in upskilling for significant changes in their careers. Delivering those kinds of courses is so very different than teaching undergrads.
The priority for professionals, generally, is to “upskill” from their current jobs into new roles which their organizations demand for a rapidly changing workplace. This is especially the case in data science; most enterprise organizations simply cannot hire enough of the data analytics talent they need therefore, so much of these staffing needs must be filled by current employees.
Based on the business focus of an organization, people need different approaches to training. For example, an exec from a large, well-known consulting firm explained to me how they rarely send staff to in-person courses. They bill clients $3,000/hour so it’d be a significant business loss to do anything other than provide on-demand online learning materials. OTOH, that same week an exec at a large, well-known computer hardware company explained to me how they strongly prefer not to have employees use online learning materials. It’d be too easy for their competitors to “gain access” to web server logs from training vendors and possibly guess new product directions long in advance. Instead, that firm spends $$$ to send employees (in teams) to conferences for training, where they rarely ask questions outside of their teams. I’ve taught courses for the company and this is true. This is also the case for a large segment of enterprise which must take competition and security concerns seriously. Translated: MOOCs are no panacea. We do not and cannot have a “one size fits all” solution for data science training.
Scale and urgency
Also, there are the matters of scale and urgency. If top analysts in the field are even close to accurate in their projections, we must hope that upskilling works well and scales effectively. Recently the World Economic Forum published “The Future of Jobs Report 2018.” The numbers are … “compelling” (some might say “encouraging,” others might say “terrifying,” YMMV):
"A reskilling imperative: By 2022, no less than 54% of all employees will require significant re- and upskilling. Of these, about 35% are expected to require additional training of up to six months, 9% will require reskilling lasting six to 12 months, while 10% will require additional skills training of more than a year. Skills continuing to grow in prominence by 2022 include analytical thinking and innovation as well as active learning and learning strategies. Sharply increasing importance of skills such as technology design and programming highlights the growing demand for various forms of technology competency identified by employers surveyed for this report. Proficiency in new technologies is only one part of the 2022 skills equation, however, as ‘human’ skills such as creativity, originality and initiative, critical thinking, persuasion and negotiation will likewise retain or increase their value, as will attention to detail, resilience, flexibility and complex problem-solving. Emotional intelligence, leadership and social influence as well as service orientation also see an outsized increase in demand relative to their current prominence."
Translated: if you’re good at doing data science work, you’ll have a lot of employment opportunities in the foreseeable future. Meanwhile, employers who are betting that their teams accomplish substantial projects in data science, machine learning, data engineering, artificial intelligence, etc., and hoping to hire new talent somehow magically in the midst of an extremely competitive hiring landscape – please take note. The term upskilling is more likely to become your byword.
Another recent report by McKinsey Global Institute correlates closely with the WEF analysis. In particular, note “Exhibit 6:”
"With talent being one of the biggest challenges to AI, no matter how advanced a company’s digital program, it’s perhaps not surprising that companies are leaving no stone unturned when sourcing people and skills. Most commonly, respondents say their organizations are taking an “all of the above” approach: hiring external talent, building capabilities in-house, and buying or licensing capabilities from large technology firms. Across industries, even the ones leading the way in AI adoption (that is, those in telecom, high tech, and financial services) report a mix of internal and external sourcing—though they are more focused than others on developing their own AI capabilities. Respondents in these sectors are more likely than average to say they’re building in-house AI capabilities, which requires internal talent with the right skills. In high tech and financial services, respondents are also much likelier to report retraining or upskilling. The same is true of the most digitized companies: respondents are more likely than others to report in-house development of AI capabilities and retraining or upskilling of current employees (Exhibit 6)."
The point is, training, retraining, and upskilling matter for data science in enterprise. Let me ask a question: as a manager, do you outsource that training? Do you rely on L&D to secure the appropriate programs? Do you build upskilling internally? Do you coach your staff to seek out their own learning opportunities? In a word, yes. And, as mentioned in the McKinsey report, probably all of the above.
Education != Training != Learning
Speaking mostly to individuals, but to organizations as well, I have two important bits of advice about how to learn data science effectively:
- Education != Training != Learning
- Find good people to mentor and invest your time
The first point you gain through experience. The second point leverages your experience and accelerates the learning involved.
Education has a role to play. Perhaps less so for professional development, where “training” is more of what we need in our upskilling context. Learning is what really needs to happen, in any case. These three terms differ significantly from each other. For data science work, the field evolves rapidly and professionals need to be learning continually.
Which brings us to the second point. Find people who are different than you, who need and want helpful mentoring in data science. Put in the time. Make a difference. Lend a friendly ear when they’re ready to change jobs and need to talk about new opportunities. Provide references. Suggest options, caveats, guidance. Help make connections. Meanwhile build your network.
Guess who benefits most by that? You will. Over the years, people I’ve helped mentor in data science have become team leaders, managers, and executives. They’ve launched interesting new tech companies and pioneered amazing projects in industry. They’ll ask questions which cause you to think differently. They’ll accumulate perspectives which differ from yours, focusing on use cases far beyond your experience. Data science is multidisciplinary and it’s a team sport. Lone wolves become myopic. By mentoring, you’ll learn through this process in much more accelerated ways than if you merely focused on climbing a corporate ladder.
Also, this builds a portfolio for social capital which even billionaire venture capitalists cannot buy. Get started now, become an ally. If you need suggestions about where to start, just ask.
Note for organizations: internal mentoring programs in data science are fantastically successful. Mix in ample portions of inclusion while you’re setting up internal programs. Ibid., urgency for upskilling.
NASA persistently misspells Jupyter
In terms of teaching and learning data science, Project Jupyter is probably the biggest news over the past decade – even though Jupyter’s origins go back to 2001! I’ll amend that point to say that the big news was Jupyter + [some manner of lightweight virtualization, ranging from VMs to Docker to virtualenv to serverless].
At its heart, Jupyter is a suite of network protocols for the semantics of remote code execution. An analogy could be how HTTP is a suite of network protocols for the semantics of remote file sharing. However, in practice (IMO) there are two major bullet points in strong support of Jupyter:
- Reproducible workflows for collaboration (read: accountability)
- Publishing and peer review
Reproducible means that another person can define a problem and describe a solution, plus code, plus data, then commit that “thought bundle” as a repo. You can follow a search to the repo, run the code, and explore the solution. Done and done. Science only took a few hundred years to reach this level of sanity.
Publishing and peer review are vital to learning. Sure, there’s the obvious example of PhD students with journal papers, dissertations, thesis defense. For another perspective: ask anyone who’s ever maintained a popular open source project about the benefits of publishing and peer review w.r.t. accelerated and continuous learning.

GWU session for #Jupyter4Edu (credit: Kyle Mandli)
That latter point is why I’m particularly drawn to Jupyter. As an instructor, there are obvious benefits of using notebooks for hands-on exercises, increased collaboration within the classroom, computational thinking approaches, inverted classroom techniques, etc.
One highly recommended resource released in late December 2018 is the new Teaching and Learning with Jupyter online book. Many thanks to Lorena Barba, et al., for compiling the experiences and advice from many people in the field. The chapter titled “A catalogue of pedagogical patterns” answers most of the difficult questions that people have ever asked me about teaching with Jupyter.
Some Background in Pedagogy
While dropping opinions about teaching, learning, etc., perhaps some personal background as a teacher might help establish context:
CS instructor at Stanford, 1984–86: for my fellowship I created a large peer-teaching program for non-technical majors to learn how to leverage Internet resources, the year after Internet launched. Lots of brilliant folks contributed over the past 34+ years to what became called Residential Computing, aka the “RCC” program, more recently renamed “VPTL.” Many other universities eventually copied our approach (looking at you, Berkeley).
Following the Dot Com boom/bust, I became an adjunct professor at a large community college, introducing curriculum for both web development (“AJAX” was a novel thing then) and network security (as a capstone, we learned how to “retrieve” root passwords for RedHat Linux).
While creating and teaching data science courses during 2013–14, I introduced Just Enough Math aimed at business execs who wanted to upskill into machine learning use cases and the advanced math required. What started as a book evolved into video plus Jupyter notebooks, then a series of conference tutorials for O’Reilly Media.
Later in 2014, Matei Zaharia and I developed an Introduction to Apache Spark course, then I took over the reigns of the popular Spark Camp from Andy Konwinski who’d created it. Along with that came a string of guest lectures at Stanford, UC Berkeley, CMU, MIT, U Maryland, Georgia Tech, Boulder, KTH, etc.
Thousands of students later, I joined O’Reilly Media and built a team called the Learning Group, where most of us had taught in both universities and industry. While avoiding the editorial and acquisition aspects, we oversaw production of learning paths, instructional videos, and conference training. We also launched the Oriole interactive format (Jupyter + Docker + video), founded the business unit for the popular Live Online Training, created an API/microservice for formative self-assessment, and helped organize Ed Foo – a “Foo Camp” about Education produced by O’Reilly and Google, along with help from Macmillan, Sci Am, Sesame Street, etc.
Perceptions about “education,” “teaching,” and “learning”
I bring this up because throughout all of those experiences, my main takeaway is that people have really crazy notions about the words “education,” “teaching,” and “learning.” One of my early caregivers taught me never to discuss religion or politics in polite company (sorry Hazel), but I’ve found that education is a substantially more divisive subject. People bring along their bias and their baggage, then try to force it onto others. Especially for data science, and particularly among executive staff, people have wildly wacked-out ideas about how to learn the practice of collaborative decision-making based on analysis and evidence. Toss in issues about fairness, bias, ethics, compliance, privacy, security, and inclusion and some people basically lose their minds. That’s a big problem in business, ibid., discussion about “upskilling” above.
For example…
MOOCs took the world by storm and are quite popular for data science and related topics. They have uses, and they have limitations. If you are UT Austin and your state legislature mandates that you graduate N new dentists each year, but doesn’t fund curriculum development within the university (historically the case), then you buy lots of courses from other universities via MOOCs. If you live on the furthermost edges of rural Newfoundland (as some of my relatives do), then remote learning via MOOCs is probably a good option. However, MOOCs have limitations. See the 2013 article in Nature, “MOOCs taken by educated few,” and also some extended discussion at an ACM meetup on the topic. One drawback is that the video for MOOCs tends to be costly for instructors to develop, although Open edX has been innovating ways to fix that.
Bootcamps and related intensive programs took the world by storm (for a while) and many of these programs have focused on data science. I’ve worked with some programs which I really like (Insight, TDI, ASI). OTOH, others in essence promised: “Pay us $$$ and you’ll become a certified data scientist within weeks. Trust us.” Translated: As if. Some people need more of a social context for learning, and bootcamps can work well for those.
Beyond Anti-Patterns
But what goes into a data science curriculum?
One request that I’ve been asked repeatedly by clients over the years is to develop a data science curriculum where people start from very few prerequisites, progress through 3–4 courses, then take a certification at the end as “expert” data scientists. Translated: that’s one of the most utterly crazy notions people have about education.
There’s no magic formula for teaching people to become data scientists. IMO, those skills can never be magically bundled into a certification program that takes mere weeks (or days) to complete. Teaching is one thing, but learning is entirely different.
One of the anti-patterns in teaching data science is, that while it’s not so hard to come up with a good “introductory” or “foundational” course, defining the intermediate and advanced courses become problematic. The fan-out for coverage on advanced topics grows too wide. So I regard most three-course “comprehensive” sequences in data science with an ample grain of salt.
The short answer is about experience. To quote a brilliant line from Werner Vogels:
"There is no compression algorithm for experience."
However, the problem at hand isn’t to define the multi-course curriculum for a university major in data science, since UC Berkeley and friends are doing a fine job at that. The problem at hand is to address the realities of upskilling at scale in industry.
Let’s define a persona for someone who needs to learn data science in an upskilling context. They probably have some technical background, at least some programming experience, or are willing to get it. That’s no problem. They’ve probably had at least a few years experience working in industry. Ergo, they’ve been involved with interviewing, some hiring decisions, and some work with data analytics in one way or another. They use data infrastructure at work. They probably already know how to write SQL queries. Perhaps, a person who’s been a team lead as a software developer, probably with an eye toward eventual management.
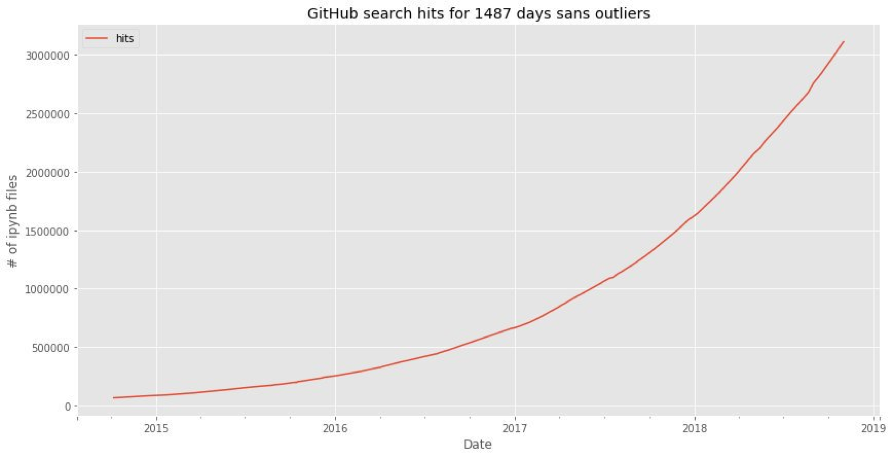
More than 3 million public notebooks (credit: Peter Parente)
In that context, defining a data science curriculum become more tractable. While there are excellent arguments for using R (have you seen the original napkin diagram?) or Julia (winner of 2018 Wilkinson prize), most people are focusing on Python for introduction to data science. For content, the foundational material needs hands-on examples which reinforce statistical thinking, how to build reproducible workflows, understanding how to use confidence intervals, how to visualize data, no free lunch theorem, creating a confusion matrix, and so on. I can plot a line from high school “Algebra II” to the math needed for machine learning. Oh, and there are currently more than three million Jupyter notebooks on GitHub, #justsayin. Toss in some current material about ethics and bias, some interesting datasets, and you’re probably good to go.
In my view, a good sequence needs this course plus a similarly structured course about the foundations of data engineering, which focuses more on leveraging infrastructure, deployment, process, and so on. Plus a similarly structured course about building and leading data science teams, which focuses on business and leadership. For the persona above, these are reachable goals for learning within a matter of weeks. Again the experience required takes years – invoking Werner’s line above – some of which already have this experience.
Recommended Resources
For learning data science, here are some of my top recommendations. If you haven’t seen R2D3’s excellent A visual introduction to machine learning series, part 1 and part 2 … run, do not walk, to your nearest browser and check that out! Distill, Parametric Press, and Observable bring awesomeness to the party as well.
Data visualization for prediction accuracy (credit: R2D3)
There are oh-so-many good blogs about data science, and one of my top picks is the go-to site for data visualization, Flowingdata. Its “evil twin opposite” is Terrible Maps, also recommended for contrast.
As you may have noticed within this column, I’m a huge fan of the O’Reilly Data Show podcast by Ben Lorica. It features leading edge info about our field, directly from the experts making these advances happen.
Now for the really fun part: top books to use in your data science curriculum. I used to do weekly trend analysis of which titles in this category got the most usage online for O’Reilly Media: Here are the best ones roughly in order of most recency + usage:
Python for Data Analysis, 2nd Edition
Wes McKinney (2017)
So much of what you need for data science, gathered into one concise volume
Hands-on Machine Learning with Scikit-Learn and TensorFlow
Aurélien Géron (2017)
Comprehensive intro to ML with the most popular open source packages
Feature Engineering for Machine Learning
Alice Zheng, Amanda Casari (2018)
Fasten your seat belts for an intense exploration of feature engineering
Machine Learning with Python Cookbook
Chris Albon (2018)
Examples of data science done well, from A to Z, in notebooks
Python Data Science Handbook
Jake Vanderplas (2016)
Excellent; full text in Jupyter on GitHub; #walkthetalk
Think Stats
Allen B. Downey (2011)
Newton wrote Principia in 3 volumes, Knuth wrote TAOCP in ~4 volumes (so far), and Downey has written 4 volumes in the Think series, so far; I do not teach without referencing them
Think Bayes
Allen B. Downey (2013)
Ibid., Newton, et al.
Data Science from Scratch
Joel Grus (2015)
We have our differences, though I’m a huge fan of Joel’s work on AllenNLP, and I teach with this book
The Master Algorithm
Pedro Domingos (2015)
When you need to explain ML to someone, even to yourself, this is the best guide yet
That’s a good start. BTW, most of these include excellent examples and exercises (e.g., notebooks). Stay tuned for more.
Upcoming Events
Upcoming events to note here:
- Strata Data Conf, SF March 25–28
- The AI Conf, NYC, April 15–18
- Rev, NYC, May 23–24 – we’ll have Nobel laureate Daniel Kahneman (Thinking Fast and Slow) headlining!
Did I mention that we’ll have Daniel Kahneman speaking at Rev?!?!? See you there.
Meanwhile, I wish you and yours all the best in the New Year!

Summary
- Introduction
- Learning Data Science
- Why does this matter?
- Different formats, different approaches
- Scale and urgency
- Education != Training != Learning
- NASA persistently misspells Jupyter
- Some Background in Pedagogy
- Perceptions about “education,” “teaching,” and “learning”
- Beyond Anti-Patterns
- Recommended Resources
- Upcoming Events
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.