Subject archive for "homepage-featured-main"

Explaining black-box models using attribute importance, PDPs, and LIME
By Nikolay Manchev17 min read
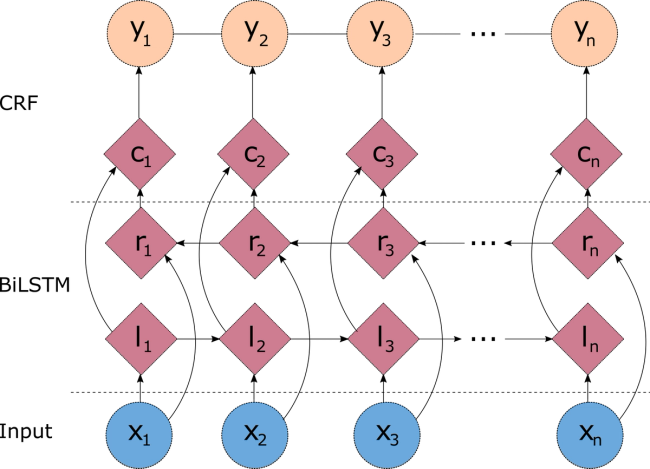
Building a Named Entity Recognition model using a BiLSTM-CRF network
By Nikolay Manchev14 min read
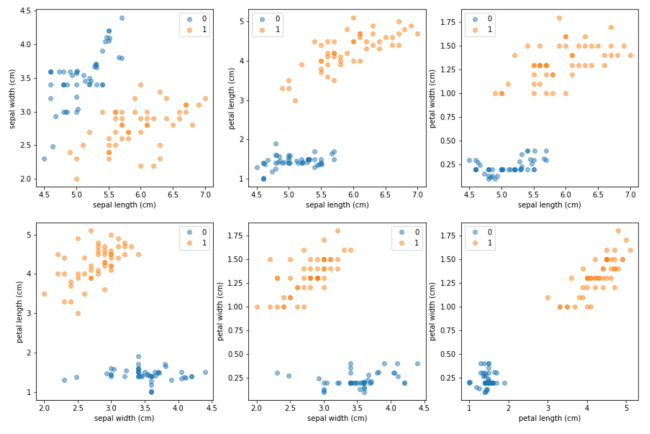
ML internals: Synthetic Minority Oversampling (SMOTE) Technique
By Nikolay Manchev22 min read
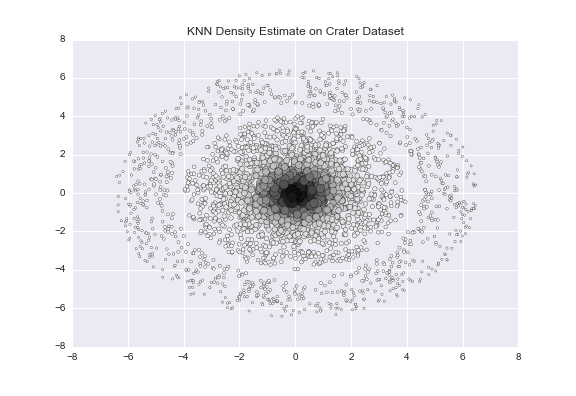
Density-Based Clustering
Original content by Manojit Nandi - Updated by Josh Poduska.
By Manojit Nandi28 min read

Providing fine-grained, trusted access to enterprise datasets with Okera and Domino
Domino and Okera - Provide data scientists access to trusted datasets within reproducible and instantly provisioned computational environments.
By David Bloch8 min read

Domino Paves the Way for the Future of Enterprise Data Science with Latest Release
Today, we announced the latest release of Domino’s data science platform which represents a big step forward for enterprise data science teams. We’re introducing groundbreaking new features – including On-demand Spark clusters, enhanced project management, and the ability to export models – that give enterprises unprecedented power to scale their data science capabilities by addressing common struggles.
By Nick Elprin11 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.