Subject archive for "data-science-featured"
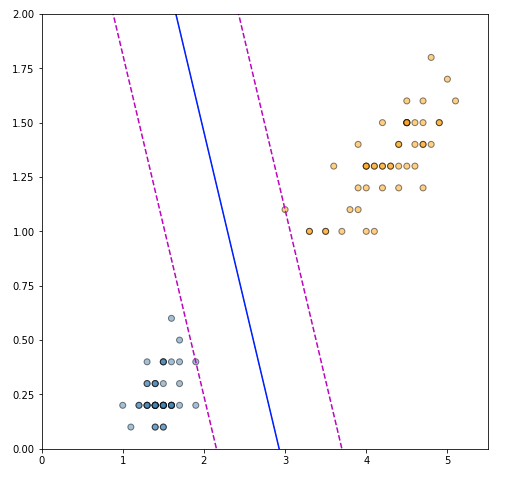
Fitting Support Vector Machines via Quadratic Programming
In this blog post we take a deep dive into the internals of Support Vector Machines. We derive a Linear SVM classifier, explain its advantages, and show what the fitting process looks like when solved via CVXOPT - a convex optimisation package for Python.
By Nikolay Manchev18 min read

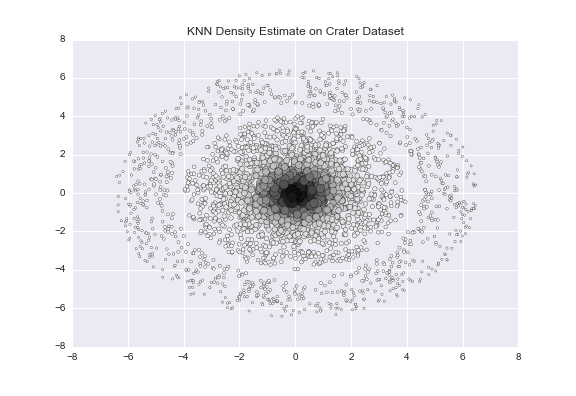
Density-Based Clustering
Original content by Manojit Nandi - Updated by Josh Poduska.
By Manojit Nandi28 min read

Data Drift Detection for Image Classifiers
This article covers how to detect data drift for models that ingest image data as their input in order to prevent their silent degradation in production.
By Subir Mansukhani7 min read

Model Interpretability: The Conversation Continues
This Domino Data Science Field Note covers a proposed definition of interpretability and distilled overview of the PDR framework. Insights are drawn from Bin Yu, W. James Murdoch, Chandan Singh, Karl Kumber, and Reza Abbasi-Asi's recent paper, "Definitions, methods, and applications in interpretable machine learning".
By Ann Spencer9 min read

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.