
Apache Spark, Dask, and Ray are three of the most popular frameworks for distributed computing. In this blog post we look at their history, intended use-cases, strengths and weaknesses, in an attempt to understand how to select the most appropriate one for specific data science use-cases.
Spark, Dask, and Ray: A History
Apache Spark
Spark was started in 2009 by Matei Zaharia at UC Berkeley's AMPLab. The main purpose of the project was to speed up the execution of distributed big data tasks, which at that point in time were handled by Hadoop MapReduce. MapReduce was designed with scalability and reliability in mind, but performance or ease of use has never been its strong side. The constant need of MapReduce to store intermediate results to disk is the key obstacle Spark aims to overcome. By introducing the Resilient Distributed Dataset (RDD) paradigm, and by taking advantage of in-memory caching and lazy evaluation, Spark was able to reduce latency by several orders of magnitude compared to MapReduce. This enabled Spark to establish its dominance as the de facto standard for large-scale, fault-tolerant, parallelised data processing. The project was further enhanced by additions like GraphX (for distributed graph processing), MLlib (for machine learning), SparkSQL (for structured and semi-structured data), and others.
It is worth noting that Spark is written in Scala, with Python and R support added later on, therefore interacting with it doesn't generally feel Pythonic. Understanding the RDD paradigm and how things are done in Spark needs a bit of time to get used to, but this typically is not a problem for anyone comfortable with the Hadoop ecosystem.
Dask
Dask is an open-source library for parallel computing, which was released in 2015, so it is relatively new compared to Spark. The framework was originally developed at Continuum Analytics (now Anaconda Inc.), who are the creators of many other open-source Python packages, including the popular Anaconda Python distribution. The original purpose of Dask was simply to parallelise NumPy, so that it can take advantage of workstation computers with multiple CPUs and cores. Unlike Spark, one of the original design principles adopted in the Dask development was "invent nothing". The idea behind this decision is that working with Dask should feel familiar to developers using Python for data analysis, and the ramp-up time should be minimal. According to its creators, the design principles of Dask have evolved over the years, and it is now being developed as a general-purpose library for parallel computing.
The initial idea around parallel NumPy further grew to include a fully-fledged, but also lightweight, task scheduler that can track dependencies and underpin the parallelisation of large, multi-dimensional arrays and matrices. Further support was later added for parallelised Pandas DataFrames and scikit-learn. This enabled the framework to relieve some major pain points in Scikit like computationally heavy grid-searches and workflows that are too big to completely fit in memory. The initial goal of a single machine parallelisation was later surpassed by the introduction of a distributed scheduler, which now enables Dask to comfortably operate in multi-machine multi-TB problem space.
Ray
Ray is another project from UC Berkeley with a mission to "simplify distributed computing". Ray consists of two major components - Ray Core, which is a distributed computing framework, and Ray Ecosystem, which broadly speaking is a number of task-specific libraries that come packaged with Ray (e.g. Ray Tune - a hyperparameter optimization framework, RaySGD for distributed deep learning, RayRLib for reinforcement learning, etc.)
Ray is similar to Dask in that it enables the user to run Python code in a parallel fashion and across multiple machines. Unlike Dask, however, Ray doesn't try to mimic the NumPy and Pandas APIs - its primary design goal was not to make a drop-in replacement for Data Science workloads but to provide a general low-level framework for parallelizing Python code. This makes it more of a general-purpose clustering and parallelisation framework that can be used to build and run any type of distributed applications. Because of how Ray Core is architected, it is often thought of as a framework for building frameworks. There is also a growing number of projects that integrate with Ray in order to leverage accelerated GPU and parallelised computing. spaCy, Hugging Face, and XGBoost are all examples of third-party libraries that have introduced Ray interoperability.
Selecting the right framework
Unfortunately, there is no simple and straightforward method for selecting "the best" framework. As it is the case with every complex question, the answer depends greatly on the context and many other factors that are at play in our specific workflow. Let's look at each of the three frameworks and consider their strengths and weaknesses, factoring in various common use-cases.
Spark
Pros:
- Established and mature technology (original release in May 2014).
- Plenty of companies providing commercial support / services.
- Ideal for data engineering / ETL type of tasks against large datasets.
- Provides higher-level SQL abstractions (Spark SQL).
Cons:
- A steep learning curve involving a new execution model and API.
- Debugging can be challenging.
- Complex architecture, which is difficult to maintain by IT alone as proper maintenance requires understanding of the computation paradigms and inner workings of Spark (e.g. memory allocation).
- Lack of a rich data visualisation ecosystem.
- No built-in GPU acceleration. Needs RAPIDS Accelerator for accessing GPU resources.
Dask
Pros:
- Pure Python framework - very easy to ramp up.
- Out-of-the-box support for Pandas DataFrames and NumPy arrays.
- Easy exploratory data analysis against billions of rows via Datashader.
- Provides Dask Bags - a Pythonic version of the PySpark RDD, with functions like map, filter, groupby, etc.
- Dask can lead to impressive performance improvements. In June 2020, Nvidia reported some astounding results on the TPCx-BB tests using RAPIDS, Dask, and UCX on 16 DGX A100 systems (128 A100 GPUs). However, take this with a pinch of salt. In January 2021 TPC forced Nvidia to take the results down as they violate TPC's fair use policy.
Cons:
- Not much commercial support is available (but several companies are starting to work in this space, for example, Coiled and QuanSight).
- No built-in GPU support. Relies on RAPIDS for GPU acceleration.
Ray
Pros:
- Minimal cluster configuration
- Best suited for computation-heavy workloads. It has already been shown that Ray outperforms both Spark and Dask on certain machine learning tasks like NLP, text normalisation, and others. To top it off, it appears that Ray works around 10% faster than Python standard multiprocessing, even on a single node.
- Because Ray is being used more and more to scale different ML libraries, you can use all of them together in a scalable, parallelised fashion. Spark, on the other hand, confines you to a substantially smaller number of frameworks available in its ecosystem.
- Unique actor-based abstractions, where multiple tasks can work on the same cluster asynchronously leading to better utilisation (in contrast, Spark's compute model is less flexible, based on synchronous execution of parallel tasks).
Cons:
- Relatively new (initial release in May 2017)
- Not really tailored to distributed data processing. Ray has no built-in primitives for partitioned data. The project just introduced Ray Datasets, but this is a brand new addition and is still quite new and bare bones.
- GPU support is restricted to scheduling and reservations. It is up to the remote function to actually make use of the GPU (typically via external libraries like TensorFlow and PyTorch)
Looking at the pros and cons for the three frameworks, we can distill the following selection criterion:
- If the workloads are data-centric and more around ETL/pre-processing, our best bet would be Spark. Especially if the organization has institutional knowledge of the Spark API.
- The Dask/Ray selection is not that clear cut, but the general rule is that Ray is designed to speed up any type of Python code, where Dask is geared towards Data Science-specific workflows.
To make things even more convoluted, there is also the Dask-on-Ray project, which allows you to run Dask workflows without using the Dask Distributed Scheduler. To better understand the niche that Dask-on-Ray tries to fill, we need to look at the core components of the Dask framework. These are the Collection abstractions (DataFrames, arrays etc.), the Task Graph (a DAG, which represents a collection of operations similar to the Apache Spark DAG), and the Scheduler (responsible for executing the Dask graph). The Distributed scheduler, which is one of the available schedulers in Dask, is the one responsible for coordinating the actions of a number of worker processes spread across multiple machines. This scheduler is great, because it is simple to set up, maintains minimal latency, allows peer-to-peer data sharing, and supports workflows that are much more complex than simple map-reduce chains. On the other hand, the distributed scheduler is not without flaws. Some of its drawbacks include:
- It is a single point of failure - there is no high-availability mechanism for the distributed scheduler, therefore if it fails, the entire cluster needs to be reset and all in-progress tasks are lost.
- It is written in Python, which makes it easy to install and debug, but it also brings into the picture the standard performance considerations that typically go hand-to-hand with Python.
- The Client API is designed with Data Scientists in mind and is not tailored to calls from a highly-available production infrastructure (e.g. it is assumed clients are long-lived, probably working with the cluster from a Jupyter session).
- It provides minimal support for stateful execution, so it is difficult to implement fault-tolerant pipelines.
- It can become a bottleneck, and it can't be natively scaled
In contrast, fault-tolerance and performance are principles deeply embedded in the design of the Ray scheduler. It is fully decentralised (no bottle-neck), provides faster data sharing (via Apache Plasma), the individual schedulers are stateless (fault-tolerant), support for stateful actors, and more. This makes the appeal of running Dask tasks on a Ray cluster quite understandable, and is the raison d'être for the Dask-on-Ray scheduler. Going deeper into the Dask-on-Ray project is out of the scope of this blog post, but if you are interested in a more in-depth comparison of the performance of the two, please feel free to look at the memory management and performance benchmark that was done by Anyscale.
How to Make Your Choice (hint: do you really need to?)
Now that we've looked at the pros and cons of Spark, Dask, and Ray —and after briefly discussing the Dask-on-Ray hybrid— it is clear that this won't be the case of "one size fits all." The three frameworks have had different design goals from the get-go, and trying to shoehorn fundamentally different workflows into a single one of them is probably not the wisest choice. A much better approach would be to design your data science process and accompanying infrastructure with flexibility in mind, ideally enabling you to spin up and use the right tool for the job. A typical pipeline could involve some ETL-like data processing conducted in Spark, followed by a machine learning workflow executed in Ray. A platform that provides the freedom to run both in a controlled, fault-tolerant, and on-demand manner enables the data science team to leverage the benefits of both frameworks.
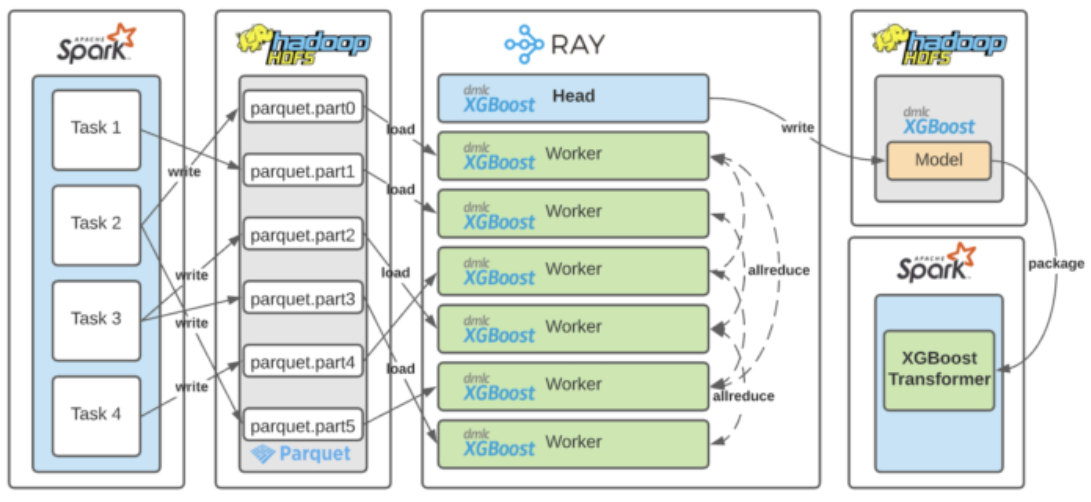
High-level overview of the flow from Spark (DataFrames) to Ray (distributed training) and back to Spark (Transformer). Ray Estimator encapsulates this complexity within the Spark Estimator interface. Source: https://eng.uber.com/elastic-xgboost-ray/
The importance of mixing frameworks is already evident by the emergence of integration libraries that make this inter-framework communication more streamlined. For example, Spark on Ray does exactly this - it "combines your Spark and Ray clusters, making it easy to do large-scale data processing using the PySpark API and seamlessly use that data to train your models using TensorFlow and PyTorch." There is also the Ray on Spark project, which allows us to run Ray programs on Apache Hadoop/YARN. This approach has also been successfully tested in real production workloads. For example, Uber's machine learning platform Michelangelo defines a Ray Estimator API, which abstracts the process of moving between Spark and Ray for end users. This is covered in detail in the recent publication from Uber Engineering, which covers an architecture for distributed training involving Spark and XGBoost on Ray.
Summary
In this article we looked at three of the most popular frameworks for parallel computing. We discussed their strengths and weaknesses, and gave some general guidance on how to choose the right framework for the task at hand. The recommended approach is not to look for the ultimate framework that fits every possible need or use-case, but to understand how they fit into various workflows and to have a data science infrastructure, which is flexible enough to allow for a mix and match approach.


Nikolay Manchev is the Principal Data Scientist for EMEA at Domino Data Lab. In this role, Nikolay helps clients from a wide range of industries tackle challenging machine learning use-cases and successfully integrate predictive analytics in their domain specific workflows. He holds an MSc in Software Technologies, an MSc in Data Science, and is currently undertaking postgraduate research at King's College London. His area of expertise is Machine Learning and Data Science, and his research interests are in neural networks and computational neurobiology.

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.