Blog archive, page 3

New brand look, same focus on AI value
At Domino, we offer both the platform and the perspective to drive Enterprise AI success. We needed a distinct approach to assert our viewpoint and effectively navigate the overwhelming information. That’s why I’m excited to introduce Domino’s new brand look. Designed to encapsulate the essence of Domino today, our brand aesthetic now integrates all aspects of artificial intelligence, serving as the optimal backdrop for our customers' AI achievements.
By Thomas Been5 min read

Fine-Tuning for mortals: Ray and Deepspeed Zero on Domino
Webinar and Repo
By Yuval Zukerman5 min read

Crush Pandas Speed Barriers with NVIDIA GPUs on Domino
See how NVIDIA's RAPIDS v23.10 revolutionizes AI workloads with GPU-accelerated Pandas on Domino, offering massive speed boosts and data handling efficiency.
By Yuval Zukerman4 min read

OpenAI’s Wake-up Call to the World: Future-Proof Your Generative AI Strategy Now
OpenAI’s board appears to have fatally stabbed the organization. Whether or not Sam Altman did or did not deserve to be let go, the organization will never be the same in the eyes of its customers, employees, investors and society at large. The unfolding debacle reveals the dangers of heavily relying on individual AI partners and the limits of outsourcing AI capabilities generally.
By Kjell Carlsson3 min read

Announcing Domino Fall ’23 Release
Discover powerful new capabilities for building AI, including Generative AI (GenAI), rapidly and safely at scale.
By Tim Law4 min read
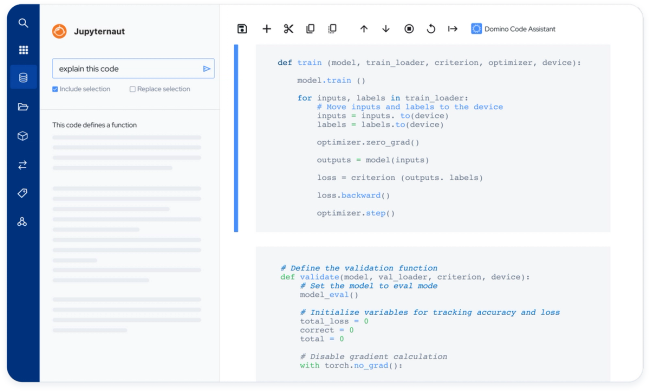
Boost Productivity with Generative Code Assistants
With our Fall 2023 release, a significant productivity boost is added to Domino by integrating Jupyter AI into Domino Workspaces.
By Yuval Zukerman6 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.