
This Domino Data Science Field Note covers Pete Skomoroch’s recent Strata London talk. It focuses on his ML product management insights and lessons learned. If you are interested in hearing more practical insights on ML or AI product management, then consider attending Pete’s upcoming session at Rev.
Machine Learning Projects are Hard: Shifting from a Deterministic Process to a Probabilistic One
Over the years, I have listened to data scientists and machine learning (ML) researchers relay various pain points and challenges that impede their work. Unfortunately, a common challenge that many industry people face includes battling “the model myth,” or the perception that because their work includes code and data, their work “should” be treated like software engineering. I was fortunate to see an early iteration of Pete Skomoroch’s ML product management presentation in November 2018 at the O’Reilly Radar Conference. Pete indicated that one of the reasons why ML projects are hard is because “machine learning shifts engineering from a deterministic process to a probabilistic one.” This talk, unsurprisingly, was filled with practical insights that addressed many pain points.

Pete Skomoroch, O’Reilly Radar Conference, San Francisco, November 2018
When Pete released the current iteration of his ML product management talk, “Why managing machines is harder than you think,” from Strata London, I reached out to him for permission to cover and excerpt his work. While the talk provides both organizational foundations for machine learning as well as product management insights to consider when shipping ML projects, I will be focusing on the latter in this blog post. Yet, if you would like to review the former, then the full deck is available here. Many thanks to Pete for the permissions and for collaborating with me on this post. If you are interested in seeing the next iteration of Pete’s talk live, then consider attending his session at Rev.
Product Management for Machine Learning
Pete indicates, in both his November 2018 and Strata London talks, that ML requires a more experimental approach than traditional software engineering. It is more experimental because it is “an approach that involves learning from data instead of programmatically following a set of human rules.” Because the nature and approach of ML projects is more experimental, industry people and their companies won’t know what will happen until they try it (i.e., more probabilistic rather than deterministic). This may present challenges for product management as many product managers (PM) have been trained on shipping projects with a deterministic approach.
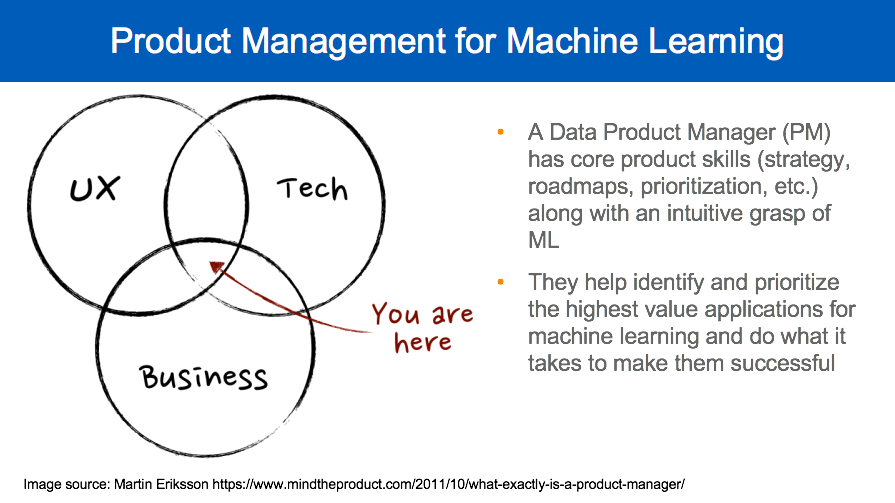
To help address these challenges, Pete recommends some additional skills for PMs to acquire including developing intuition about how ML works, understanding what is feasible from a ML perspective, and “know[ing] the difference between easy, hard, and impossible machine learning problems.”

PMs can leverage that intuition to calibrate the tradeoffs of various approaches given their company’s data “and how it can be used to solve customer problems.” Pete recommends bringing in ML experts and data scientists early in the process as well as “creating a chart of impact and ease, then ranking projects by ROI” when iterating on which features or projects to prioritize. The combination of a deep understanding of your company’s data, how the data can solve customer problems, ML intuition, and domain expertise, helps PMs ensure that they are working on the right problems that matter to the business. Pete outlines 5 steps for shipping most ML projects and notes that steps 2-4 take up the majority of the time. These steps also reflect the experimental nature of ML product management.

Pete relays that one of the most significant value adds to improve model accuracy is feature engineering, which is discovering the creative signals you find in the raw data, extracting them from the raw data, and then transforming them into suitable formats (or better inputs) for your machine learning model. He recommends getting the first version of the algorithm out quickly to users so that iterative improvements can be made to support business impact. Pete advises PMs to keep in mind that approximately 80% of the work happens after the first version ships. This work includes model improvements as well as adding new signals and features into the model. He also recommends that PMs refrain from “endless UI changes” on ML projects before the product is put before users because “seemingly small UI changes may result in significant back end ML engineering work” that may put the overall project at risk. The last step for a PM is to “use derived data from the system to build new products” as this provides another way to ensure ROI across the business.
Addressing the Uncertainty that ML Adds to Product Roadmaps
As ML projects are more experimental and probabilistic in nature, they have the potential to “add uncertainty to product roadmaps.” Here, Pete outlines common challenges and key questions for PMs to consider.

Then, he recommends that PMs collect data using appropriate user input forms that will collect the right data they need to “model the underlying phenomena you want to predict and that PMs will need to balance the desire for exhaustive data collection with user experience carefully.”

Pete also recommends that PMs reconsider their approach to testing given that ML systems run on underlying input data that often changes over time in unpredictable ways. He advocates use by real users as “sunlight is the best disinfectant”. This also reinforces his earlier recommendation of shipping version 1.0 quickly.

Pete also reinforces what he mentioned earlier about how “seemingly small” changes can have “unintended consequences.” While earlier, he cautions PMs that seemingly small UI changes can lead to significant back end engineering, seemingly small product changes like “changing the phrasing of a question” can lead to the data a user gives to change and may add a time dependency within the historical data. This leads to potential complications for using the historical data in training ML models.
Conclusion
Pete Skomoroch’s pragmatic advice and insights throughout his Strata London talk focuses on how it is possible to build and ship successful ML products. Many thanks again to Pete for the permission to excerpt his Strata London talk and for taking the time to collaborate on this Domino Data Science Field Note focused on his ML product management insights and lessons learned. If you are interested in hearing more practical insights on ML or AI product management, then consider attending Pete’s upcoming session at Rev.
Domino Data Science Field Notes provide highlights of data science research, trends, techniques, and more, that support data scientists and data science leaders accelerate their work or careers. If you are interested in your data science work being covered in this blog series, please send us an email at content(at)dominodatalab(dot)com.

Ann Spencer is the former Head of Content for Domino where she provided a high degree of value, density, and analytical rigor that sparks respectful candid public discourse from multiple perspectives, discourse that’s anchored in the intention of helping accelerate data science work. Previously, she was the data editor at O’Reilly, focusing on data science and data engineering.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.