
What is Factor Analysis?
P-values. T-tests. Categorical variables. All are contenders for the most misused statistical technique or data science tool. Yet factor analysis is a whole different ball game. Though far from over-used, it is unquestionably the most controversial statistical technique, due to its role in debates about general intelligence. You didn't think statistical techniques could be divisive, did you? [Not counting that one time that the U.C. Berkeley stats department left Andrew Gelman.]
In data science texts, factor analysis is that technique that is always mentioned along with PCA, and then subsequently ignored. It is like the Many Worlds interpretation of quantum mechanics, nay, it is the Star Wars Holiday Special of data science. Everyone is vaguely familiar with it, but no one seems to really understand it.
Factor analysis aims to give insight into the latent variables that are behind people's behavior and the choices that they make. PCA, on the other hand, is all about the most compact representation of a dataset by picking dimensions that capture the most variance. This distinction can be subtle, but one notable difference is that PCA assumes no error of measurement or noise in the data: all of the 'noise' is folded into the variance capturing. Another important difference is that the number of researcher degrees of freedom, or choices one has to make, is much greater than that of PCA. Not only does one have to choose the number of factors to extract (there are ~10 theoretical criteria which rarely converge), but then decide on the method of extraction (there are ~7), as well as the type of rotation (there are also 7), as well as whether to use a variance or covariance matrix, and so on.
The goal of factor analysis is to figure out if many individual behaviors of users can't be explained by a smaller number of latent characteristics. Making this more concrete, imagine you operate a restaurant. Although some of your customers eat pretty healthily, you notice that many often order a side of poutine with their otherwise dietetic kale salad. Being an inquisitive and data-oriented restaurateur, you come up with a hypothesis – Every order can be explained with one 'healthfulness' dimension, and people who order Poutine and kale salad at the same time are somewhere in the middle of a dimension characterized by 'Exclusive Kale and Squash eaters' on one end, and 'Eats nothing but bacon' on the other.
However, you note that this might not explain differences in how customers actually place their orders, so you come up with another – Perhaps there are two dimensions, one which is about how much people love or hate kale, and the other is about how much people love or hate Poutine. Maybe these dimensions, you reason, are orthogonal. Maybe they are somewhat negatively correlated. Maybe there is also a dimension concerned with how much your customers like the other competing dishes on the menu.
You start to notice a trend in your own hypotheses and realize that there could be any number of theorized dimensions. What you really want to know is the smallest number of dimensions that explain the most amount of variance in how your customers place their orders. Presumably, so you can keep more Poutine to yourself. ('Cause that stuff is delicious).
More technically, running a factor analysis is the mathematical equivalent of asking a statistically savvy oracle the following: "Suppose there are N latent variables that are influencing people's choices –tell me how much each variable influence the responses for each item that I see, assuming that there is measurement error on everything". Oftentimes, the 'behavior' or responses that are being analyzed comes in the form of how people answer questions on surveys.
Mathematically speaking, for person i, item j and behavior Yij, Factor analysis seeks to determine the following:
Yij = Wj1 * Fi1 + Wj2 * Fi2 + … + Uij
Where W's are the factor weights or loadings, F's are the factors, and U is the measurement error / the variance that can't be accounted for by the other terms in the equation. The insight of the people who created factor analysis was that this equation is actually a matrix reduction problem.
Just like any technique, it won't run blind – you have to determine the number of factors to extract, similar to picking the number of dimensions to reduce to with PCA. There are numerous indicators about which number you should pick; I'll go over the best ones later. I mention this because when you read guides and papers about factor analysis, the biggest concern is extracting the right number of factors properly. Make no mistake—this is something to worry about. However, the most important part of the factor or all data analysis for that matter, alas, is almost never mentioned. The number one thing to be mindful of when doing data or factor analysis is the tendency for your brain has to lie to you. Given the striking number of researcher degrees of freedom involved in factor analysis, it is very easy to justify making different choices because the results don't conform to your intuitions.
Don't believe me? Try this: Jack, George, and Anne are guests at a dinner party. Jack is looking at Anne, and Anne is looking at George. Jack is married, George is not. Is a married person looking at an unmarried person?
A) Yes
B) No
C) Not enough information.
Most people upon reading this question realize there is a trick involved, and grab a piece of paper to work out the answer. They then pick C. It seems logical. Yet the correct answer is A – it doesn't matter if Anne is married or not. Reno really is west of Los Angeles. The struggle continues.
Unless you take an intentional stance against it, your brain will try and rationalize its preconceived notions on to your analysis. This usually takes the form of rounding factor loadings up or down or justifying how many factors to extract. Remember: You want to believe what the data says you should believe.
Getting Started with Factor Analysis in R
Preprocessing
Before you do factor analysis, you'll need a few things.
First: Download R and RStudio if you don't already have it. Then Get the 'Psych' package. It is unparalleled as free Factor Analysis software. Load it by typing library(psych)
Next: Get Data. On my end, I'll be using the 'bfi' dataset that comes with the psych package. The data is in the form of responses to personality questions known as the Big Five Inventory. However, any sort of record of behavior will do – at the end of the day, you'll need to be able to make a full correlation matrix. The larger your sample size, the better. A sample size of 400-500 is generally agreed to be a good rule of thumb.
Now the fun begins. The psych package as a handy describe function. (Note: Each alphanumeric pair represents a personality 'trait', taken with a 6-point Likert scale.)
> describe(bfi) vars n mean sd median trimmed mad min max range skew kurtosis seA1 1 2784 2.41 1.41 2 2.23 1.48 1 6 5 0.83 -0.31 0.03 A2 2 2773 4.80 1.17 5 4.98 1.48 1 6 5 -1.12 1.05 0.02 A3 3 2774 4.60 1.30 5 4.79 1.48 1 6 5 -1.00 0.44 0.02 A4 4 2781 4.70 1.48 5 4.93 1.48 1 6 5 -1.03 0.04 0.03 A5 5 2784 4.56 1.26 5 4.71 1.48 1 6 5 -0.85 0.16 0.02 C1 6 2779 4.50 1.24 5 4.64 1.48 1 6 5 -0.85 0.30 0.02 C2 7 2776 4.37 1.32 5 4.50 1.48 1 6 5 -0.74 -0.14 0.03 C3 8 2780 4.30 1.29 5 4.42 1.48 1 6 5 -0.69 -0.13 0.02 C4 9 2774 2.55 1.38 2 2.41 1.48 1 6 5 0.60 -0.62 0.03 C5 10 2784 3.30 1.63 3 3.25 1.48 1 6 5 0.07 -1.22 0.03 E1 11 2777 2.97 1.63 3 2.86 1.48 1 6 5 0.37 -1.09 0.03 E2 12 2784 3.14 1.61 3 3.06 1.48 1 6 5 0.22 -1.15 0.03 E3 13 2775 4.00 1.35 4 4.07 1.48 1 6 5 -0.47 -0.47 0.03 E4 14 2791 4.42 1.46 5 4.59 1.48 1 6 5 -0.82 -0.30 0.03 E5 15 2779 4.42 1.33 5 4.56 1.48 1 6 5 -0.78 -0.09 0.03 N1 16 2778 2.93 1.57 3 2.82 1.48 1 6 5 0.37 -1.01 0.03 N2 17 2779 3.51 1.53 4 3.51 1.48 1 6 5 -0.08 -1.05 0.03 N3 18 2789 3.22 1.60 3 3.16 1.48 1 6 5 0.15 -1.18 0.03 N4 19 2764 3.19 1.57 3 3.12 1.48 1 6 5 0.20 -1.09 0.03 N5 20 2771 2.97 1.62 3 2.85 1.48 1 6 5 0.37 -1.06 0.03 O1 21 2778 4.82 1.13 5 4.96 1.48 1 6 5 -0.90 0.43 0.02 O2 22 2800 2.71 1.57 2 2.56 1.48 1 6 5 0.59 -0.81 0.03 O3 23 2772 4.44 1.22 5 4.56 1.48 1 6 5 -0.77 0.30 0.02 O4 24 2786 4.89 1.22 5 5.10 1.48 1 6 5 -1.22 1.08 0.02 O5 25 2780 2.49 1.33 2 2.34 1.48 1 6 5 0.74 -0.24 0.03 gender 26 2800 1.67 0.47 2 1.71 0.00 1 2 1 -0.73 -1.47 0.01 education 27 2577 3.19 1.11 3 3.22 1.48 1 5 4 -0.05 -0.32 0.02 age 28 2800 28.78 11.13 26 27.43 10.38 3 86 83 1.02 0.56 0.21There is some demographic data included in this dataset, which I will trim for the factor analysis.
df <- bfi[1:25]While factor analysis works for both covariance as well as correlation matrices, the recommended practice is to use a correlation matrix. That's right—All you really need is a correlation matrix of different indicators of behavior (even if that behavior is 'clicking on a button', 'answering a question a certain way', or 'actually giving us money').
Determining the Number of Factors
Though there are myriad indicators for the 'proper' number of factors to extract, there are two main techniques, other than the time-honored tradition of inspecting various factor solutions and interpreting the results. The first is to inspect a scree plot, or an'eigenvalue vs. number of factors / components' chart. (A screed plot, on the other hand, usually involves lots of cement)
>scree(df)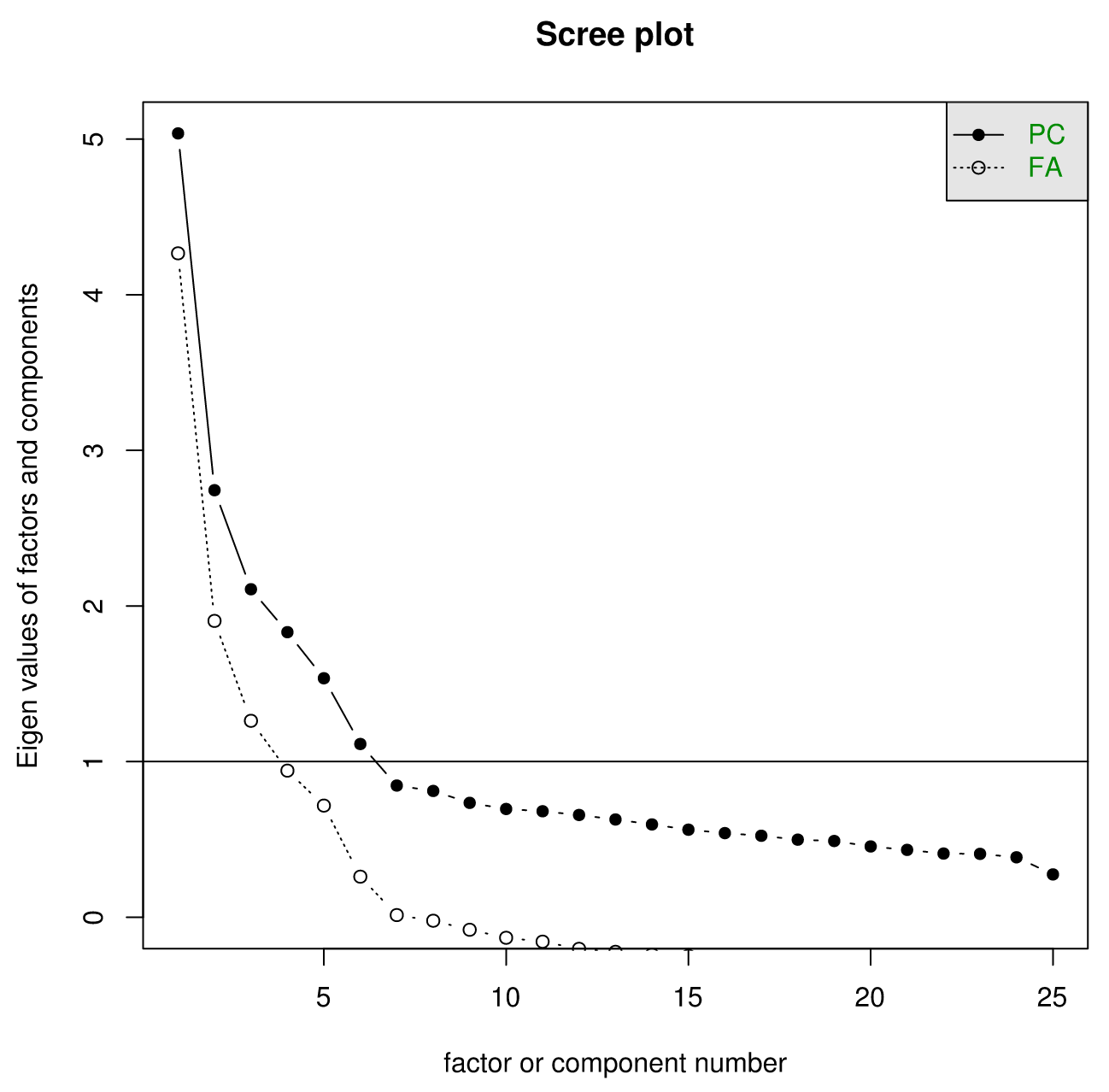
After a certain point, each additional factor or component will result in a mere marginal reduction of eigenvalue. (Translation: Each additional factor doesn't explain too much more variance.) There will generally be some sort of 'Elbow', and the idea is you pick the last factor that still reduces the variance. Is this subjective? Yes. Can intuition be built around this rule? Yes.
A word of caution: There is a tendency to just take the number of factors whose eigenvalues are greater than one. This is a near-universal mistake. Don't do it. You've been warned. Also, it helps to make sure that you are viewing the scree plot full-sized, and not just in the small RStudio plot window.
In this case, if we strictly follow the 'find the elbow' rule, it looks like '6' is the highest number one could get away with. There are more sophisticated methods for double-checking the number of factors to extract, like parallel analysis. A description of parallel analysis, courtesy of The Journal of Vegetation Science: "In this procedure, eigenvalues from a data set prior to rotation are compared with those from a matrix of random values of the same dimensionality (p variables and n samples)." The idea is that any eigenvalues below those generated by random chance are superfluous.
>fa.parallel(bfi)Parallel analysis suggests that the number of factors = 6 and the number of components = 6
Here is the plot output:
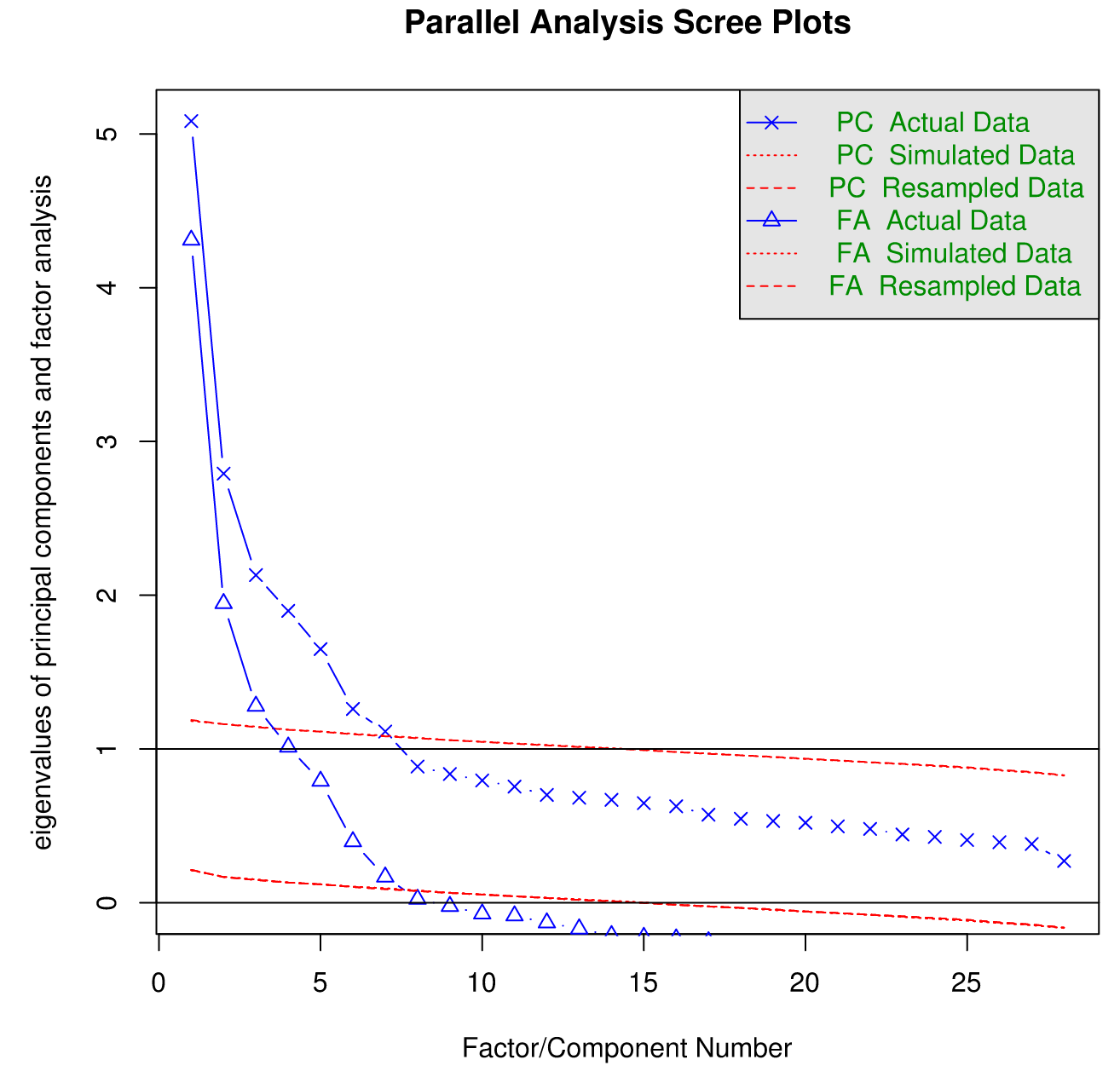
By know you are thinking "okay, we've decided on the number of factors to extract. Can we just get it over with already? My buddy is doing PCA and she's already left to go eat her Kale and Poutine lunch." Not so fast. We have to figure out how to extract the 6 factors and then if and how we want to rotate them to aid our interpretation.
Factor Extraction
There are a plethora of factor extraction techniques, the merits of most of which are compared in this (useful) thrill-a-minute thesis.
Here is what you need to know. There are three main factor extraction techniques: Ordinary least Squares (also called 'Minimum Residuals', or 'Minres', for short), Maximum Likelihood, and Principal Axis factoring. OLS / Minres has been found to outperform other methods in a variety of situations, and usually gives a solution close to what you would get if you used Maximum Likelihood. Maximum Likelihood is useful because you can calculate confidence intervals. Principal axis factoring is a widely used method that places most of the variance on the first factor. As with all data analysis, if you have robust, meaningful results or signal in your data from a new method or experiment, then what you'll be concerned with should be invariant to the factor extraction technique. But if your work is sensitive to smaller differences in factor loading scores and interpretation, than it is worth taking the time to figure out which tool is best for you. For an exploratory analysis of the bfi data, the ols / minres method suffices
Rotation
Factor extraction is one thing, but they are usually difficult to interpret, which arguably defeats the whole point of this exercise. To adjust for this, it is common to 'rotate', or choose slightly different axes in the n-factor subspace so that your results are more interpretable. Essentially, rotation sacrifices some of the explained variances for actually knowing what is going on. (This is a little hand-wavy, but rotation is strongly recommended by most, if not all of notable 20th-century psychometricians.)
Quite unlike Kale, rotation comes in two distinct flavors. An orthogonal rotation assumes that the factors uncorrelated, while an oblique rotation assumes they are correlated. The choice between orthogonal vs. oblique choice depends on your particular use-case. If your data consists of items from one large domain and you have no reason to think that certain behaviors could be completely uncorrelated, use oblique rotation. If you want to know more, see here for a brief overview, and here for a little more depth.
Two popular types of rotation are Varimax (orthogonal), and Oblimin (oblique). Given that the data I am analyzing is based on personality items, I'll choose oblimin rotation, as there is good apriori reason to assume that the factors of personality are not orthogonal.
Factor analysis has a really simple command in R:
> fa(df,6,fm='minres',rotate='oblimin')Factor Analysis using method = minres Call: fa(r = df, nfactors = 6, rotate = "oblimin", fm = "minres") Standardized loadings (pattern matrix) based upon correlation matrix MR2 MR1 MR3 MR5 MR4 MR6 h2 u2 comA1 0.10 -0.11 0.08 -0.56 0.05 0.28 0.33 0.67 1.7 A2 0.04 -0.03 0.07 0.69 0.00 -0.06 0.50 0.50 1.0 A3 -0.01 -0.12 0.03 0.62 0.06 0.10 0.51 0.49 1.2 A4 -0.07 -0.06 0.20 0.39 -0.11 0.15 0.28 0.72 2.2 A5 -0.16 -0.21 0.01 0.45 0.12 0.21 0.48 0.52 2.3 C1 0.01 0.05 0.55 -0.06 0.18 0.07 0.35 0.65 1.3 C2 0.06 0.13 0.68 0.01 0.11 0.17 0.50 0.50 1.3 C3 0.01 0.06 0.55 0.09 -0.05 0.04 0.31 0.69 1.1 C4 0.05 0.08 -0.63 -0.07 0.06 0.30 0.55 0.45 1.5 C5 0.14 0.19 -0.54 -0.01 0.11 0.07 0.43 0.57 1.5 E1 -0.13 0.59 0.11 -0.12 -0.09 0.08 0.38 0.62 1.3 E2 0.05 0.69 -0.01 -0.07 -0.06 0.03 0.55 0.45 1.1 E3 0.00 -0.35 0.01 0.15 0.39 0.21 0.48 0.52 2.9 E4 -0.05 -0.55 0.03 0.19 0.03 0.29 0.56 0.44 1.8 E5 0.17 -0.41 0.26 0.07 0.22 -0.02 0.40 0.60 2.9 N1 0.85 -0.09 0.00 -0.06 -0.05 0.00 0.70 0.30 1.0 N2 0.85 -0.04 0.01 -0.02 -0.01 -0.08 0.69 0.31 1.0 N3 0.64 0.15 -0.04 0.07 0.06 0.11 0.52 0.48 1.2 N4 0.39 0.44 -0.13 0.07 0.11 0.09 0.48 0.52 2.5 N5 0.40 0.25 0.00 0.16 -0.09 0.20 0.35 0.65 2.8 O1 -0.05 -0.05 0.08 -0.04 0.56 0.03 0.34 0.66 1.1 O2 0.11 -0.01 -0.07 0.08 -0.37 0.35 0.29 0.71 2.4 O3 -0.02 -0.10 0.02 0.03 0.66 0.00 0.48 0.52 1.1 O4 0.08 0.35 -0.02 0.15 0.38 -0.02 0.25 0.75 2.4 O5 0.03 -0.06 -0.02 -0.05 -0.45 0.40 0.37 0.63 2.1 MR2 MR1 MR3 MR5 MR4 MR6SS loadings 2.42 2.22 2.04 1.88 1.67 0.83 Proportion Var 0.10 0.09 0.08 0.08 0.07 0.03 Cumulative Var 0.10 0.19 0.27 0.34 0.41 0.44 Proportion Explained 0.22 0.20 0.18 0.17 0.15 0.07 Cumulative Proportion 0.22 0.42 0.60 0.77 0.93 1.00 With factor correlations of MR2 MR1 MR3 MR5 MR4 MR6MR2 1.00 0.25 -0.18 -0.10 0.02 0.18 MR1 0.25 1.00 -0.22 -0.31 -0.19 -0.06 MR3 -0.18 -0.22 1.00 0.20 0.19 -0.03 MR5 -0.10 -0.31 0.20 1.00 0.25 0.15 MR4 0.02 -0.19 0.19 0.25 1.00 0.02 MR6 0.18 -0.06 -0.03 0.15 0.02 1.00Mean item complexity = 1.7 Test of the hypothesis that 6 factors are sufficient.The degrees of freedom for the null model are 300 and the objective function was 7.23 with Chi Square of 20163.79 The degrees of freedom for the model are 165 and the objective function was 0.36 The root mean square of the residuals (RMSR) is 0.02 The df corrected root mean square of the residuals is 0.03 The harmonic number of observations is 2762 with the empirical chi square 660.84 with prob < 1.6e-60 The total number of observations was 2800 with MLE Chi Square = 1013.9 with prob < 4.4e-122 Tucker Lewis Index of factoring reliability = 0.922 RMSEA index = 0.043 and the 90 % confidence intervals are 0.04 0.045 BIC = -295.76 Fit based upon off diagonal values = 0.99 Measures of factor score adequacy MR2 MR1 MR3 MR5 MR4 MR6Correlation of scores with factors 0.93 0.89 0.88 0.87 0.85 0.77 Multiple R square of scores with factors 0.87 0.80 0.78 0.77 0.73 0.59 Minimum correlation of possible factor scores 0.73 0.59 0.56 0.53 0.46 0.18 There is a lot in this output, I won't unpack it all – You can find more detail in the documentation of the psych package. Included in the printout are metrics about how well the model fit the data. The standard rule of thumb is that the RMSEA index should be less than .06. I've highlighted it to make things easier. The other metrics can be valuable, but each has a specific case or three for which it doesn't work, rmsea works across the board. Double check to make sure this value isn't too high. Then, the fun part – do a rough inspection of the factors by calling
> print(fa(df,6,fm='minres',rotate='oblimin')$loadings,cut=.2)Loadings: MR2 MR1 MR3 MR5 MR4 MR6 A1 -0.558 0.278 A2 0.690 A3 0.619 A4 0.392 A5 -0.207 0.451 0.208 C1 0.548 C2 0.681 C3 0.551 C4 0.632 0.300 C5 0.540 E1 0.586 E2 0.686 E3 0.349 0.391 0.207 E4 -0.551 0.288 E5 -0.405 0.264 0.224 N1 0.850 N2 0.850 N3 0.640 N4 0.390 0.436 N5 0.403 0.255 0.202 O1 0.563 O2 -0.367 0.352 O3 0.656 O4 0.354 0.375 O5 -0.451 0.400 MR2 MR1 MR3 MR5 MR4 MR6SS loadings 2.305 1.973 1.925 1.700 1.566 0.777 Proportion Var 0.092 0.079 0.077 0.068 0.063 0.031 Cumulative Var 0.092 0.171 0.248 0.316 0.379 0.410 Always be sure to look at the last factor—in this case, none of the loadings on the last factor are the highest, which suggests that it is unnecessary. Thus we move to a 5-factor solution:
> fa(df,5,fm='minres','oblimin')Factor Analysis using method = minres Call: fa(r = df, nfactors = 5, n.obs = "oblimin", fm = "minres") Standardized loadings (pattern matrix) based upon correlation matrix MR2 MR3 MR5 MR1 MR4 h2 u2 comA1 0.20 0.04 -0.36 -0.14 -0.04 0.15 0.85 2.0 A2 -0.02 0.09 0.60 0.01 0.03 0.40 0.60 1.1 A3 -0.03 0.03 0.67 -0.07 0.04 0.51 0.49 1.0 A4 -0.06 0.20 0.46 -0.04 -0.15 0.29 0.71 1.7 A5 -0.14 0.00 0.58 -0.17 0.06 0.48 0.52 1.3 C1 0.06 0.53 0.00 0.05 0.16 0.32 0.68 1.2 C2 0.13 0.64 0.11 0.13 0.06 0.43 0.57 1.2 C3 0.04 0.56 0.11 0.08 -0.06 0.32 0.68 1.1 C4 0.12 -0.64 0.06 0.04 -0.03 0.47 0.53 1.1 C5 0.14 -0.57 0.01 0.16 0.10 0.43 0.57 1.4 E1 -0.09 0.10 -0.10 0.56 -0.11 0.37 0.63 1.3 E2 0.06 -0.03 -0.09 0.67 -0.07 0.55 0.45 1.1 E3 0.06 -0.02 0.30 -0.34 0.31 0.44 0.56 3.0 E4 0.00 0.01 0.36 -0.53 -0.05 0.52 0.48 1.8 E5 0.18 0.27 0.08 -0.39 0.22 0.40 0.60 3.1 N1 0.85 0.01 -0.09 -0.09 -0.05 0.71 0.29 1.1 N2 0.82 0.02 -0.08 -0.04 0.01 0.66 0.34 1.0 N3 0.67 -0.06 0.10 0.14 0.03 0.53 0.47 1.2 N4 0.41 -0.16 0.09 0.42 0.08 0.48 0.52 2.4 N5 0.44 -0.02 0.22 0.25 -0.14 0.34 0.66 2.4 O1 -0.01 0.06 0.02 -0.06 0.53 0.32 0.68 1.1 O2 0.16 -0.10 0.21 -0.03 -0.44 0.24 0.76 1.9 O3 0.01 0.00 0.09 -0.10 0.63 0.47 0.53 1.1 O4 0.08 -0.04 0.14 0.36 0.38 0.26 0.74 2.4 O5 0.11 -0.05 0.10 -0.07 -0.52 0.27 0.73 1.2 MR2 MR3 MR5 MR1 MR4SS loadings 2.49 2.05 2.10 2.07 1.64 Proportion Var 0.10 0.08 0.08 0.08 0.07 Cumulative Var 0.10 0.18 0.27 0.35 0.41 Proportion Explained 0.24 0.20 0.20 0.20 0.16 Cumulative Proportion 0.24 0.44 0.64 0.84 1.00 With factor correlations of MR2 MR3 MR5 MR1 MR4MR2 1.00 -0.21 -0.03 0.23 -0.01 MR3 -0.21 1.00 0.20 -0.22 0.20 MR5 -0.03 0.20 1.00 -0.31 0.23 MR1 0.23 -0.22 -0.31 1.00 -0.17 MR4 -0.01 0.20 0.23 -0.17 1.00Mean item complexity = 1.6 Test of the hypothesis that 5 factors are sufficient.The degrees of freedom for the null model are 300 and the objective function was 7.23 with Chi Square of 20163.79 The degrees of freedom for the model are 185 and the objective function was 0.63 The root mean square of the residuals (RMSR) is 0.03 The df corrected root mean square of the residuals is 0.04 The harmonic number of observations is 2762 with the empirical chi square 1474.6 with prob < 1.3e-199 The total number of observations was 2800 with MLE Chi Square = 1749.88 with prob < 1.4e-252 Tucker Lewis Index of factoring reliability = 0.872 RMSEA index = 0.055 and the 90 % confidence intervals are 0.053 0.057 BIC = 281.47 Fit based upon off diagonal values = 0.98 Measures of factor score adequacy MR2 MR3 MR5 MR1 MR4Correlation of scores with factors 0.93 0.88 0.88 0.88 0.85 Multiple R square of scores with factors 0.86 0.77 0.78 0.78 0.72 Minimum correlation of possible factor scores 0.73 0.54 0.56 0.56 0.44 These metrics tell us that solution is certainly notterrible, and thus on to the factor inspection:
> print(fa(df,5,fm='minres',rotate='oblimin')$loadings,cut=.2)Loadings: MR2 MR3 MR5 MR1 MR4 A1 0.204 -0.360 A2 0.603 A3 0.668 A4 0.456 A5 0.577 C1 0.532 C2 0.637 C3 0.564 C4 -0.643 C5 -0.571 E1 0.565 E2 0.667 E3 0.303 -0.342 0.315 E4 0.362 -0.527 E5 0.274 -0.394 0.223 N1 0.852 N2 0.817 N3 0.665 N4 0.413 0.420 N5 0.439 0.223 0.247 O1 0.534 O2 0.211 -0.441 O3 0.633 O4 0.357 0.378 O5 -0.522 MR2 MR3 MR5 MR1 MR4SS loadings 2.412 1.928 1.922 1.839 1.563 Proportion Var 0.096 0.077 0.077 0.074 0.063 Cumulative Var 0.096 0.174 0.250 0.324 0.387 Right off the bat, this loading table looks a lot cleaner – items clearly load on one predominant factor, and the items seem to be magically grouped by letter. Spoiler: it was this very kind of analysis that originally lead psychometricians and personality researchers to conclude that there are five major dimensions to interpersonal differences: Agreeableness, Conscientiousness, Extraversion, Neuroticism (sometimes called emotional stability), and Openness. Each one of those terms has a precise technical definition that usually differs from how you might use the words in conversations. But that is a whole different story.
Now comes the most rewarding part of factor analysis*– figuring out a concise name for the factor, or construct, that can explain how and why people made the choices they did. This is much harder to do, by the way, if you have underspecified the number of factors that best fit this data.
*Funny, only psychometricians seem to think that factor analysis is 'rewarding'.
This has really only been the tip of the iceberg — there is much more complexity involved in special kinds of rotation and factor extraction, bifactor solutions... Don't even get me started on factor scores. Factor analysis can be a powerful technique and is a great way of interpreting user behavior or opinions. The most important take away from this approach is that factor analysis lays bare the number of choices research must make when utilizing statistical tools, and the number of choices is directly proportional to the number of opportunities for your brain to project itself onto your data. Other techniques that seem simpler have merely made these choices behind the scenes. None, however, have the storied history of factor analysis.

Evan Warfel is the founder and director of Delphy Research as well as the head of Science and Product at Life Partner Labs. He is available for consulting.
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.