How Enterprise MLOps Works Throughout the Data Science Lifecycle
David Weedmark2021-07-28 | 8 min read

The data science lifecycle (DLSC) has been defined as an iterative process that leads from problem formulation to exploration, algorithmic analysis and data cleaning to obtaining a verifiable solution that can be used for decision making. For companies creating models to scale, an enterprise Machine Learning Operation (MLOps) platform not only needs to support enterprise-grade development and production, it needs to follow the same standard process that data scientists use.
How Enterprise MLOps Integrates into the Data Science Lifecycle
The data science lifecycle can be divided into four steps or stages: Manage, Develop, Deploy and Monitor. Like any lifecycle, these stages are all interdependent. Not only can they be repeated through the life of each project, the stages are also repeated from one ML project to another, all through the life of the organization that creates them.
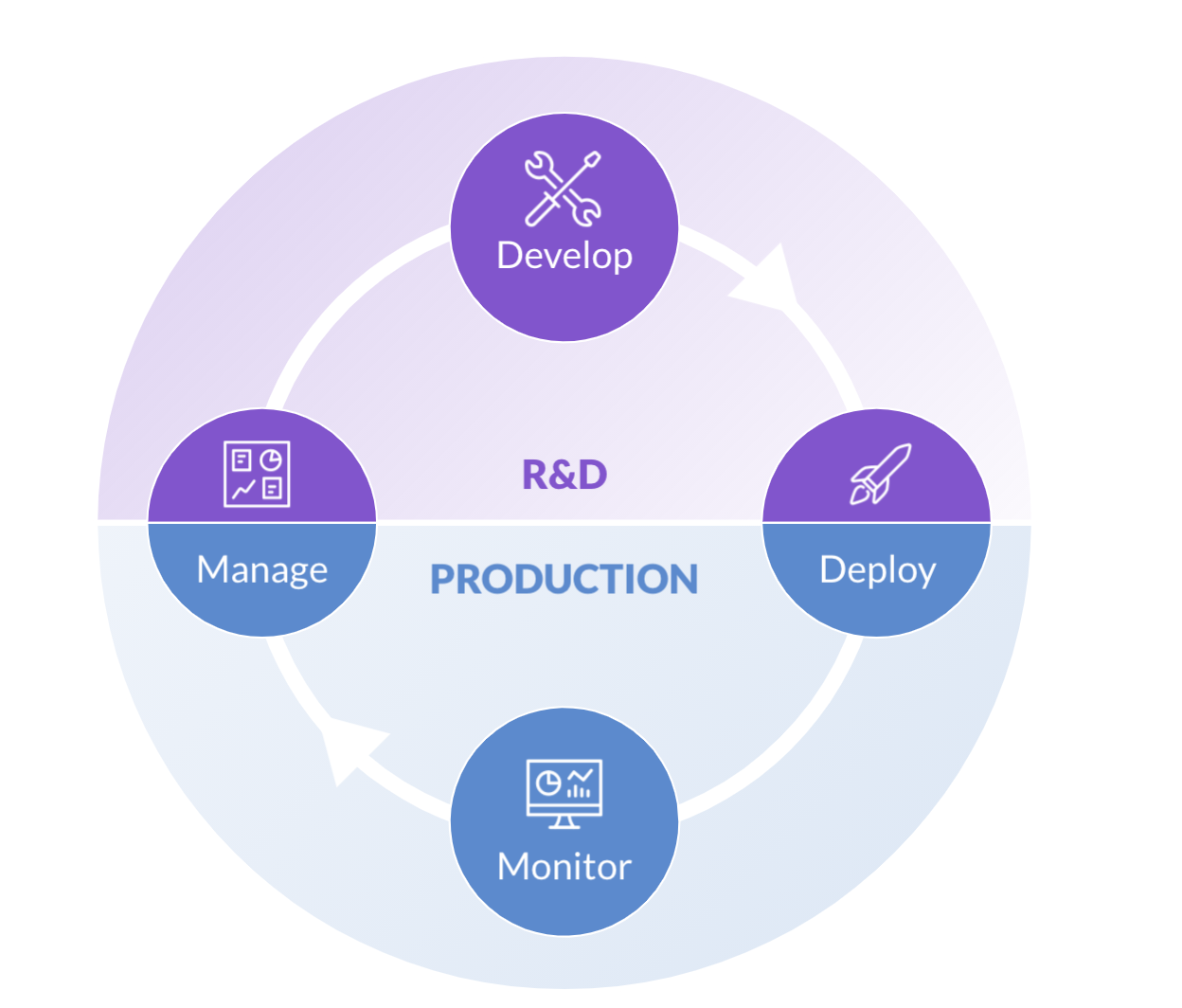
The more efficiently each stage is completed, the faster and more efficiently the organization can scale its operations. Efficient management, for example, leads to faster, more efficient development. Efficient monitoring leads to better management. And efficient development leads to more successful deployments.
While each new project usually begins with the Manage stage, it will often close with that stage as well.
The sets of information gained from the project are then carried forward to subsequent projects. This includes assets, like new algorithms and sources of new data, as well as the lessons learned by the teams working on them. Just as the projects and the data and the ML models themselves change, so do the individuals working on those projects in any enterprise environment.
Data scientists, analysts and ML engineers may move from one project to another, or they may leave the organization while new team members are brought on board. Regardless of these changes, however, the information generated throughout the DSLC needs to be retained to avoid duplicate efforts..
1. Manage Stage
The data science process in a business environment begins with the Manage stage. This is where the project requirements are established so that everyone involved has a clear understanding of the project requirements and objectives. Roles are assigned and work priorities are established before any research and development can begin.
After an ML model has been deployed and monitored, an enterprise-based team should then revisit the Manage stage to evaluate the success or failure of the project. Success breeds success, and lessons learned on one project can be carried into future projects, reducing future errors and thus increasing efficiency.
Domino’s Knowledge Center is the enterprise organization’s central repository of all such key learnings, driving compound knowledge. It’s the place where work is tracked and managed so that it can be easily found later, then reused or reproduced as needed, with relevant notes at each stage. Validators and auditors can use the Knowledge Center to ensure models are safe and trusted, thus reducing potential risks.
2. Develop Stage
The Develop stage is where data scientists build and assess models based on a variety of different modeling techniques. The ability to quickly and freely innovate is key here, since this is where ideas are researched, discussed, tested, refined and then researched again.
The Workbench is Domino's notebook-based environment where data scientists can do their R&D and experimentation. Durable Workspaces gives data scientists self-serve access to all the tools and infrastructure they need to run, track and compare experiments.
Since data scientists know what they need, Workbench gives them a place to select the tools and resources they need, when they need it, with just a few clicks of the mouse — and without the need for DevOps. This means they can independently do things like:
- Run and compare the progress of hundreds of experiments simultaneously
- Scale CPU, GPU and other resources on-demand
- Access multiple tools and workspaces like Jupyter, RStudio, Zeppelin, SAS Studio
- Add libraries, tools, and algorithms as needed
- Link to Git-based repositories to quickly integrate existing code
- Easily track code, data, tools, packages and compute environments to find and reproduce past results
Since Workbench provides all of these features from a centrally-managed environment, data scientists have the flexibility to use the tools and infrastructure they need within the governance framework of their organization.
3. Deploy Stage
When a developed model has been deemed successful, it’s ready to move from development into the Deploy stage, where it can be used in production – usually within a business process where it’s used for decision making. Efficient deployment requires a robust platform that can easily publish a model using the same tools and resources from development.
Within Domino’s Enterprise MLOps Enterprise platform, models in the Deploy stage are able to create the business value they were designed for. Business users can utilize the model via an API embedded into the same infrastructure which allows access from an existing program, web browser, or as an app.
Another important component of Domino’s platform for model deployment is the use of containers, which allows models to be easily moved and reproduced as needed, so that the same models can be scaled as many times as needed. Key to containerized models is Kubernetes, an open-source system that’s proved to be ideal for managing the complex requirements of automated deployment of multiple containerized models.
4. Monitor Stage
The Monitor stage follows right after deployment, as this is when organizations need to ensure that the model is performing as intended and that it’s providing the business value that was expected. Since enterprise organizations tend to have hundreds of models in production across different infrastructures, monitoring them all simultaneously can be challenging without the right platform.
Domino’s Model Monitoring provides a single pane of glass that can be used to monitor all of the models in production across the organization, while automatically detecting any problems and proactively alerting the appropriate team members when a model needs to be updated, paused or replaced.
Because monitoring also entails analysis from non-technical users from business units, Model Ops also allows you to create interactive apps from templates that can be used to run speculative analysis in different use-case scenarios. At the same time, data scientists and engineers can use Model Ops to schedule automated checks for performance drift, as well as to analyze and diagnose drift quickly from a single user interface.
MLOps in the Data Science Lifecycle
Embracing the DSLC is proving to be an important component in reducing inefficiencies and successfully scaling ML models for any profit-driven organization that develops and deploys ML models. Integrating operations with an enterprise-grade MLOps platform that was built around the DSLC ensures that all of your organization's resources are being used efficiently across multiple projects – from owned data sets and algorithms to the schedules of busy data scientists and developers.
If your company plans to be part of the future in ML/AI, and intends on stacking one successful project on top of another, take a few minutes to review our MLOps best practices article or watch a demo of Domino Enterprise MLOps Platform in action.


David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.
RELATED TAGS
SHARE

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.