Horizontal Scaling for Parallel Experimentation
Eduardo Ariño de la Rubia2017-06-01 | 6 min read

The amount of time data scientists spend waiting for experiment results is the difference between making incremental improvements and making significant advances. With parallel experimentation, data scientists can run more experiments faster, leaving more time to try novel and unorthodox approaches—the kind that leads to exponential improvements and discoveries.
In a previous article, we demonstrated parallel experimentation on a micro-level: Using R and Python packages to leverage hardware with multi-core processors. In this article, we explain how parallel experimentation can be done on a macro level to get results even faster using horizontal scaling in the cloud.
What is Horizontal Scaling?
Horizontal scaling in data science is the ability to add and remove compute environments on-demand to support multiple concurrent experiments. Imagine you have a model training task or simulation that will take an hour to run even on high-end hardware, and you want to try a few variations of it. Perhaps you’re testing a trading strategy and you want to test it on multiple stocks, or you’re running a Monte Carlo simulation and you want to try multiple values for a random seed.
On a micro level, it is possible to find an optimal solution faster by seeding a model with multiple parameters and spreading the load across multiple cores. However, if you want to test multiple, independent approaches in parallel, you can do so with horizontal scaling.
The ability to horizontally scale compute resources would let you try out multiple types of models, or even feature engineering pipelines, without sacrificing performance or flexibility. This is powerful when leveraging simulation- and agent-based approaches for approximate and heuristic methods, where ensembling multiple strategies can provide a better solution than any single strategy, no matter how perfectly tuned.
Horizontal scalability is often used by data science teams that need to train thousands (if not millions) of models and score large numbers of independent examples.
An example use case is ad-tech or social networking companies that want to develop a model for per-user recommendations or forecasting. The models can be trained in parallel across a large user base Having the ability to scale model training horizontally allows those teams to build models customized for each specific user’s preferences and idiosyncrasies. Scoring these models is done in batches, where the responses are serialized to a back-end cache for sub-millisecond lookup. This massively parallel scoring step can also leverage horizontal scalability, given a caching infrastructure that can support a number of parallel insertions and updates.
Challenges
Unfortunately, many data scientists have been unable to take advantage of horizontal scaling. Here’s why:
If they’re running experiments on local hardware, they must either do these tasks in series or compete for fixed computing resources with their colleagues.
If they’re running experiments in the cloud, they can—in theory—create multiple instances to run in parallel, but the amount of time, effort, and knowledge it takes to do that is prohibitive.
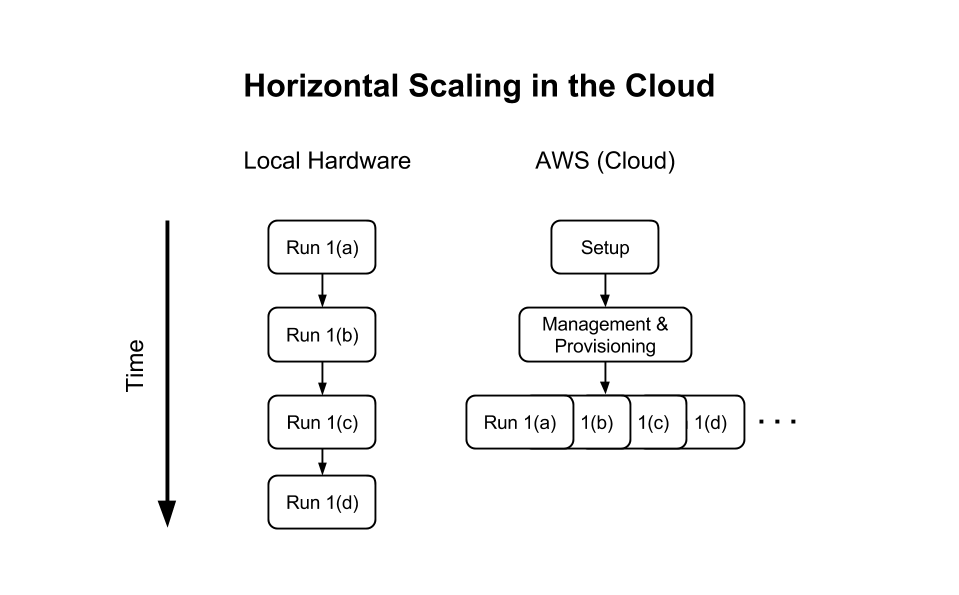
(How prohibitive is it? One popular tutorial contains 15 steps just to start a Jupyter notebook on EC2, and all 15 steps are fraught with potential errors. Furthermore, those steps depend on open-source software that could be updated at any time with unexpected consequences.)
The inability to conduct parallel experiments using horizontal scaling hurts companies. It creates a bottleneck that not only slows down progress, but also fundamentally changes data scientists’ tolerance for curiosity and exploration. There’s no incentive to try bold, non-traditional approaches that are more likely to lead to bigger improvements, transformational insights, and a competitive edge.
Solution
Although it may seem that horizontal scaling for parallel experimentation is only accessible to large organizations with virtually unlimited resources and DevOps support, that is no longer the case today.
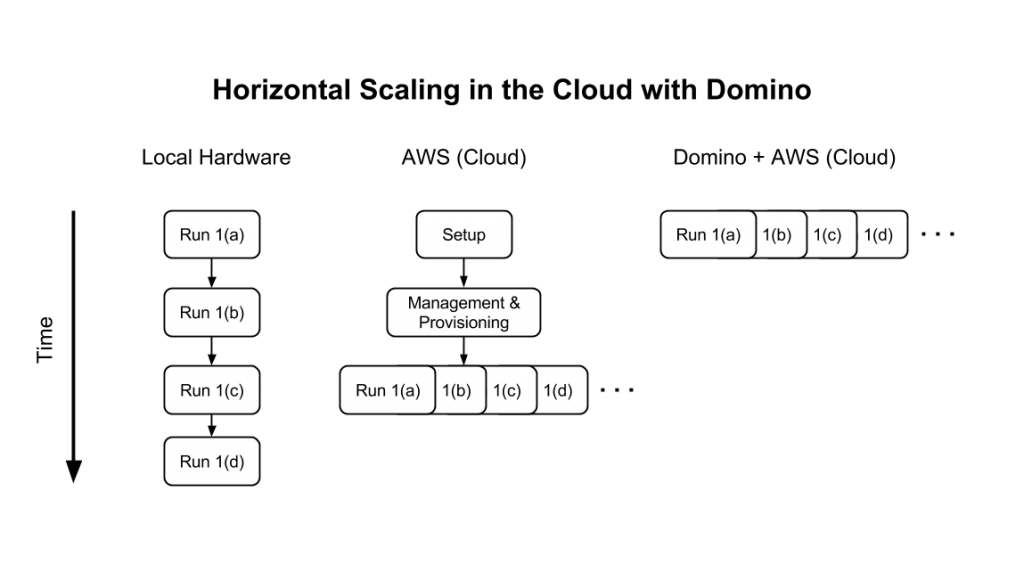
Data science platforms like Domino act as an abstraction layer that lets data scientists spin up cloud compute environments on-demand, directly from their command line, without the need for DevOps help or long and fragile configuration steps. Domino will spin up an AWS EC2 instance for each experiment (at each experiment’s designated machine type), spin it down when the run is complete, and automatically detect and store results from each one.
Running a handful of experiments in parallel is nice, but true scalability goes beyond that. Imagine your team could initiate hundreds of concurrent experiments to run in parallel, each on their own AWS machine. Again, this is theoretically possible to set up on your own in AWS, but the cost and effort of configuring and maintaining such an infrastructure could quickly counteract any gains in productivity. With a platform like Domino, a data scientist can do this with a single command or through an API.
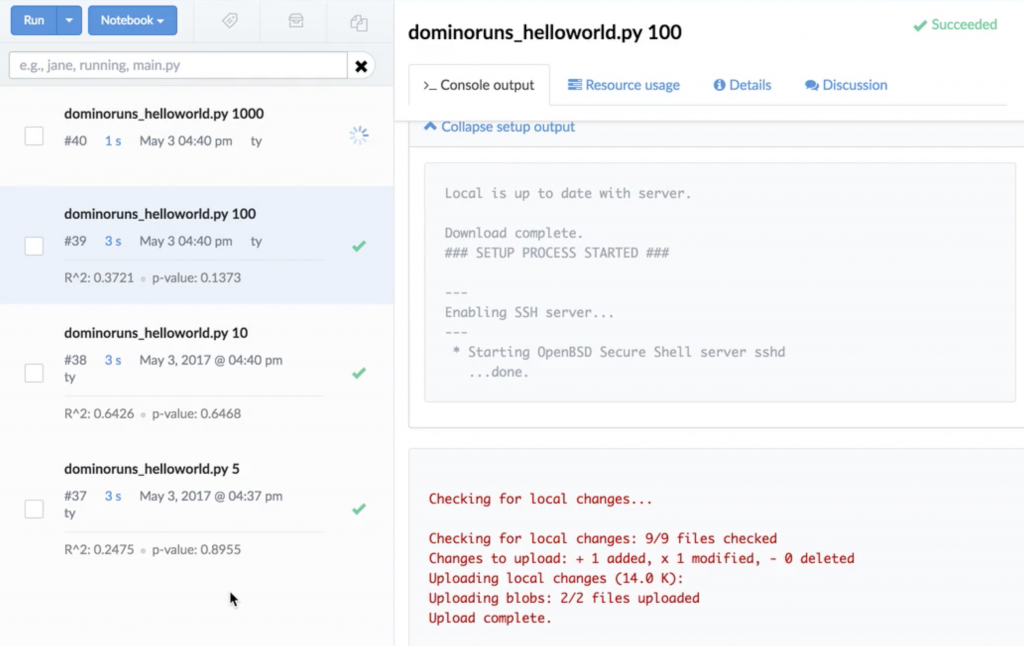
Example of Horizontal Scaling from the CLI
We want to benchmark over 100 model types on classification and regression tasks. Training hundreds of models on local hardware or on self-managed cloud could take hours, but with horizontal scalability (with Domino) it's possible to train the models in parallel with a simple "runner script" in the command line:
input_file=$1for object in cat $input_filedodomino run --title "batch: $input_file model: $object" --no-syncbuild_classification_models.R $objectdoneThis script queues all the experiments and lets us generate all the results.
Conclusion
Putting horizontal scaling in the hands of data scientists gives them the ability to innovate faster. The cloud makes horizontal scaling accessible to all data science teams, and Domino makes it easy.
If you are interested in giving your team the ability to conduct parallel experimentation with horizontal scalability, then learn more about using Domino on top of AWS.

Eduardo Ariño de la Rubia is a lifelong technologist with a passion for data science who thrives on effectively communicating data-driven insights throughout an organization. A student of negotiation, conflict resolution, and peace building, Ed is focused on building tools that help humans work with humans to create insights for humans.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.