High-performance Computing with Amazon's X1 Instance - Part II
Eduardo Ariño de la Rubia2016-10-10 | 5 min read

When you have at your disposal 128 cores and 2TB of RAM, it’s hard not to experiment and attempt to find ways to leverage the amount of power that is at your fingertips. We’re excited to remind our readers that we support Amazon’s X1 instances in Domino, you can do data science on machines with 128 cores and 2TB of RAM — with one click:
The X1 hardware tier is available in our cloud-hosted environment and can be made available to customers using Domino in their VPCs. Needless to say, with access to this unprecedented level of compute power, we continue to have some fun in this continuation of our first post. After some encouragement from some contacts in the industry, I decided to see if other algorithms could leverage the power of the X1. In particular, a deep learning neural network and some random forests.
Deep Learning
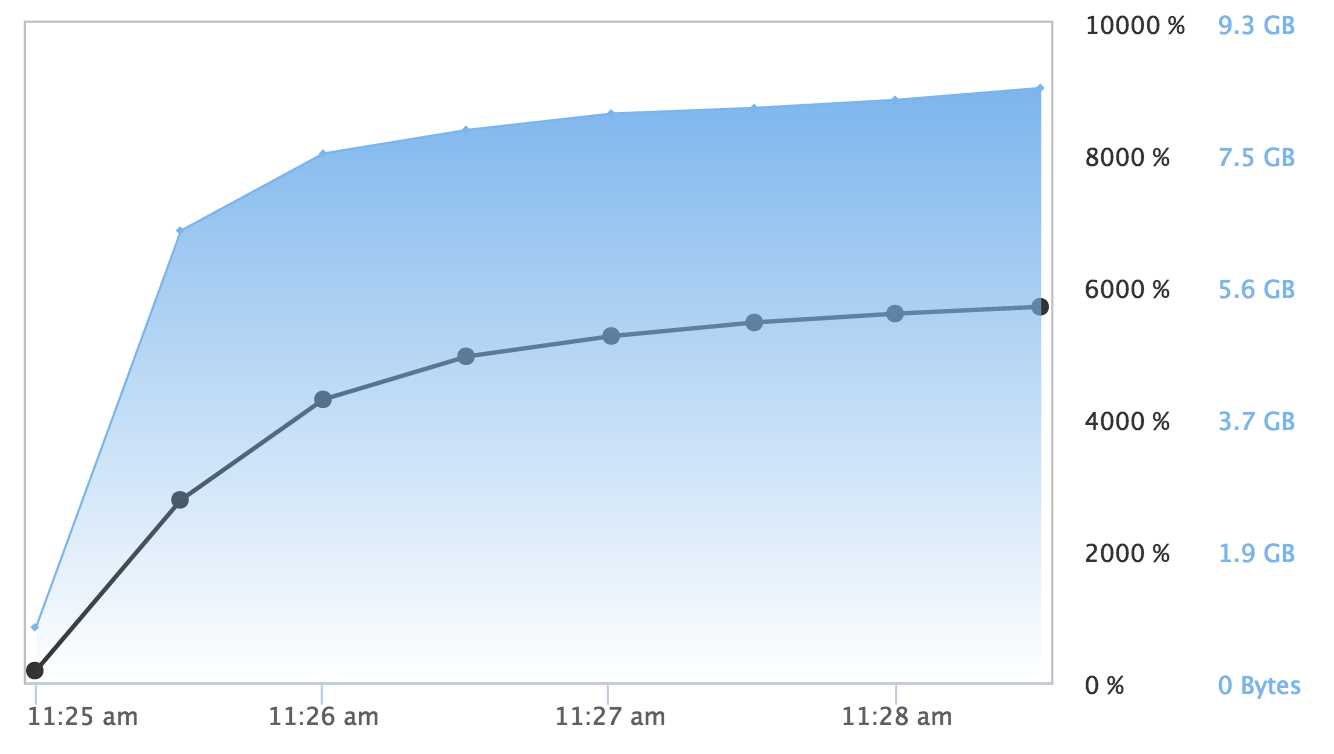
While deep learning neural networks are most often trained on GPUs, H2O.ai has a deep learning model which works quite well on CPUs. Using H2O's h2o.deeplearning model and a rectifier activation function with two hidden layers of 200 neurons each, I was able to train a network on 10 million rows of the airline dataset in just 4 minutes! The deep learning model did not scale to all 128 cores (more accurately, AWS vCPUs), but leveraged nearly 50% of the CPU capacity available, and generated a very respectable AUC of 0.7255915 on the validation test set.
Random Forests
Random forests are notoriously slow to train. They have impressive performance characteristics and real-world behavior but can be slow to build, especially with large datasets. Unlike GBMs, random forest training is much more parallelizable. For the first test, I used H2O's random forest implementation, having used it in the past for both Kaggle competitions and customer solutions and found it performed well. For this test, I trained a random forest with 1000 trees on 10 million rows of data on the X1 instance. This algorithm was able to utilize nearly all the processing power of the X1 instance.
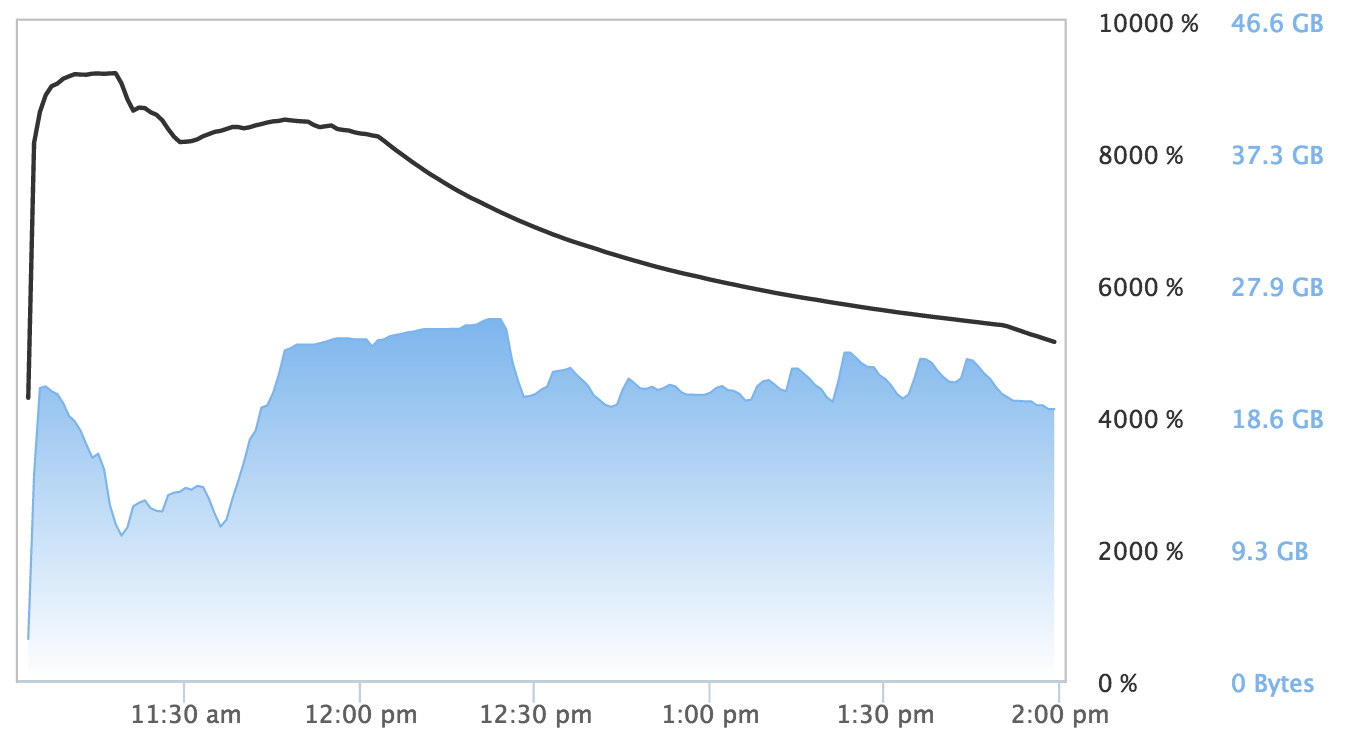
As mentioned, training a random forest models can be time-consuming. The X1 took almost 3 hours to complete the training. However, the model's AUC of 0.7699968 against the validation data illustrates the predictive power of using random forest with very large datasets.
For the second test, I decided to try my hand at scikit-learn’s RandomForestClassifier as it has proven itself to be a mature and robust implementation of the Random Forest algorithm. To parallelize the training of a RandomForestClassifier across 128 cores, all I needed to do was pass the parameter n_jobs=-1 to the constructor. Scikit-learn is not parallelizing resamples and cross-validation, but the actual construction of a single RandomForestClassifier object.
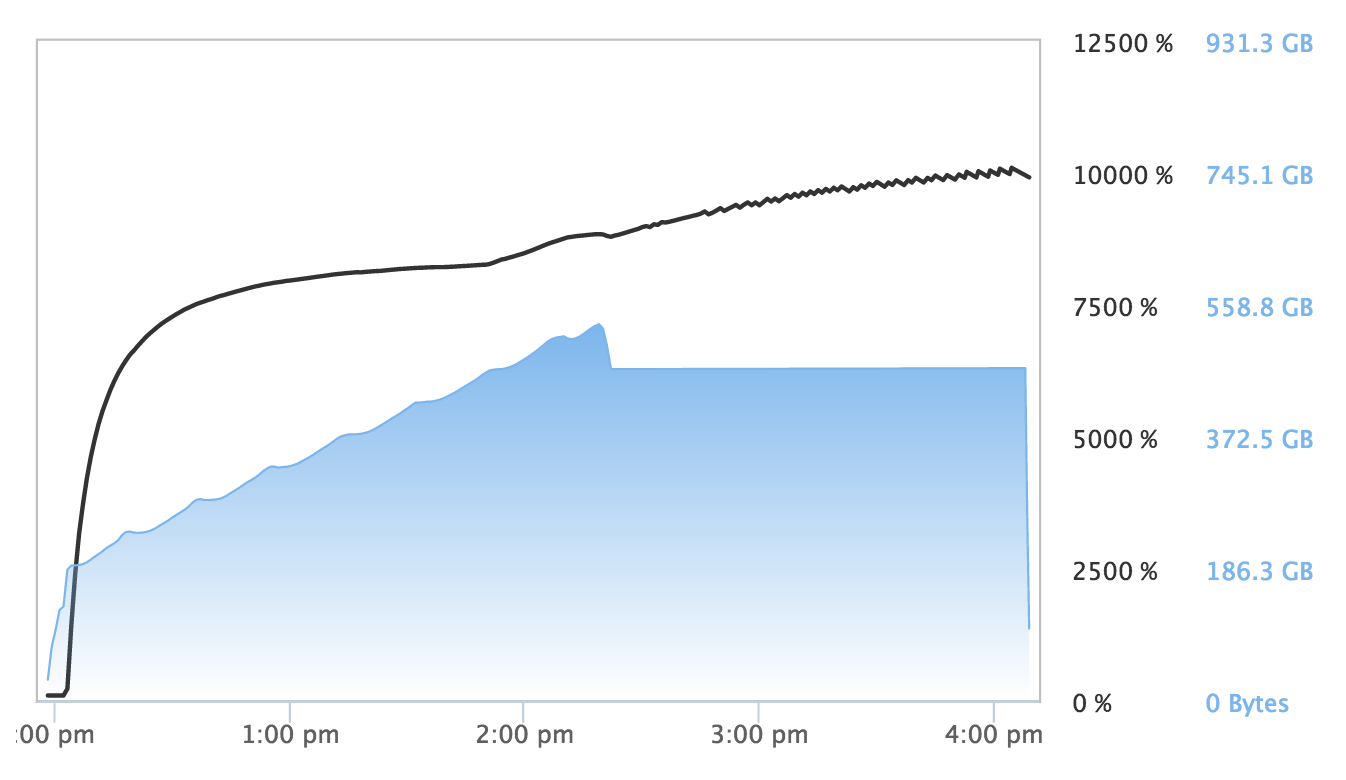
The scikit-learn RandomForestClassifer took over an hour longer to train than the H2O random forest, completing it in slightly over 4 hours. The AUC for this implementation was 0.759779, lower than the H2O model. All random forest algorithms are not alike, and in this case, H2O's algorithm provided faster performance and higher accuracy out of the box than the scikit-learn implementation.
The scikit-learn's RandomForestClassifier also used far more memory than H2O's algorithm: Training the scikit-learn classifier used 540GB of RAM, nearly 20x the 24GB H2O's random forest used at peak. Both of these memory footprints fit comfortably in the X1 instance's vast addressable memory space. That said, 540GB of RAM is ¼ of the X1's memory. One can imagine scikit-learn’s memory usage severely limiting the size of models that can be trained using it’s RandomForestClassifier.
We will continue to write about high-performance machine learning over the next few months, exploring the X1, Amazon's new P2 GPU instances (16 NVIDIA K80 GPUs, 64 vCPUs, 732GB RAM), and whatever else we can lay our hands on. It is important to note that these blog posts should not be considered definitive posts on the performance of any libraries or algorithms we use. Rather, they are directionally useful for understanding the challenges of leveraging such massive compute power. We hope that our customers and other vendors will start publishing similar posts, describing how the community can take advantage of the power of these new platforms and move state of the art forward.
Banner image titled "Forest" by Loren Kerns. Licensed under CC BY 2.0

Eduardo Ariño de la Rubia is a lifelong technologist with a passion for data science who thrives on effectively communicating data-driven insights throughout an organization. A student of negotiation, conflict resolution, and peace building, Ed is focused on building tools that help humans work with humans to create insights for humans.
Summary
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.