In this article we talk about the foundations of Computer vision, the history and capabilities of the OpenCV framework, and how to make your first steps in accessing and visualising images with Python and OpenCV.
Introduction
One of the ultimate goals for artificial intelligence is to acquire the ability to comprehend the state of the physical world and to have the ability to react, similar to humans, in response to stimuli from the surrounding environment. In humans, these reactions are products of cognitive functions including visual perception. These functions allow humans to observe surroundings and to understand and decode visual perception into contextual information.
Computer vision (CV), as an interdisciplinary subfield of artificial intelligence, aims to mimic human cognitive functions to provide capabilities similar to human vision. These include understanding the content of digital images, types of objects, and their relationships. We consider the field interdisciplinary as different disciplines have contributed to CV development. For example, neuroscience has been a key contributor as it has enabled the decoding of human vision. CV is inherently part of computer science as machine learning approaches and algorithm theory are also essential for CV development.
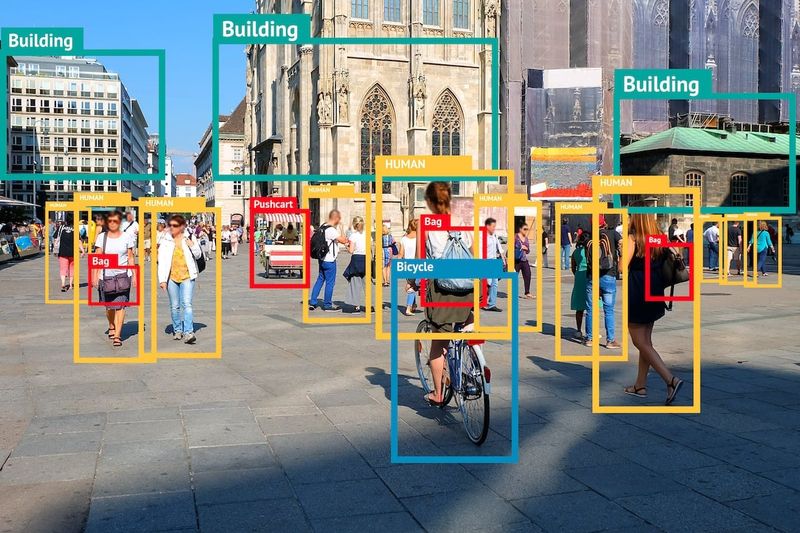
As humans, we can comprehend and extract information from an image instantaneously and with high accuracy. Humans can identify objects, and their relationships and can communicate their perception of the visual world through languages. For example, upon examining the image depicted in Figure 1 we can recognise a dog and the action portrayed, which is that the dog is jumping over a striped hurdle. We can identify colours (black, white, blue, yellow etc.) and features that make up objects (shapes, edges etc.).
In addition, there are two persons in the background, one standing and the other sitting.
Based on different objects and the associated action we can subsequently infer that this photo may demonstrate a dog show. For AI algorithms, however, acquiring and applying this seemingly easy human capability sits on a continuum of difficulty especially for complex images that require contextual understanding [1].
To simplify, there are two major components in a vision system: a) sensing/capturing and b) interpreting/converting components. In humans, our eyes act as the sensing device by capturing light that is reflected from objects, received via the iris, and projected to the retina. From there, specialised cells will transmit information to the brain through neurons. This information is subsequently decoded into meaning by the brain’s visual cortex.

Figure 1. Human visual perception of images leads to instantaneous detection of objects and their relationships. Source: Flickr8K datasets
We can identify that this image contains a number of objects and depicts an activity (dog jumping over a hurdle). The information also allows us to infer that this may illustrate a dog show.
For computers, a camera can act as the sensing/capturing component, storing and transferring the image information as pixels. The interpreting component in the CV environment is an AI agent, and this is where CV still lags behind the natural vision system. Converting pixels into meaning is the primary reason why CV is still a hard task for computers. For example, the image in Figure 1, is 500 x 497 pixels with red, green and blue (RGB) channels. Converting these pixels into meaningful information and an accurate image description is still a difficult task for an AI agent.
The human vision system is fast in sensing and interpreting an image with a reported 150 milliseconds to classify an animal from a natural scene [3]. Humans can also naturally involve context in interpreting an image. For example, we can infer using our prior knowledge that the image in Figure 1 potentially illustrates a dog show event. This is a significant advantage but difficult to incorporate into CV algorithms. The built-in attention mechanism into our vision system is also advantageous but also means that modification of parts of the image, where our brain doesn't tend to focus its attention, may not be captured and noticed.
Computer vision offers diverse applications in many domains. It allows special effects in the entertainment industry and provides the ability for image classification, objects recognition and tracking, face detection, content-based image retrieval, self-driving cars, robotics, medical, security and education.
Recent advances in deep learning coupled with the ability of these approaches to exploit Graphics Processing Units (GPUs) for accelerated training, together with the availability of large labelled datasets, have revolutionised the CV landscape. They utilise the strength of neural networks to solve CV tasks that traditional machine learning fails to solve efficiently. Traditional approaches are reliant on extracting image features to solve a variety of tasks including image classification. This feature extraction step is laborious and biased as it may not extract all the sufficient features required for an accurate outcome. Deep learning approaches bypass this step by automatic and unbiased extraction of image features.
There are a variety of Python tools that can be used for CV-related tasks one of which is Open-Source Computer Vision (OpenCV); a free, open-source library widely used in academic and commercial settings including in Google, Intel, Microsoft and IBM. OpenCV was released under the BSD license by Intel in June 2000 and is written in C++ with API support for different programming languages including Python, Java and MATLAB [4].
OpenCV-Python is an API for OpenCV to leverage the strength of Python and the OpenCV C++ API. For Python, this is a library of bindings aiming to solve CV-focused tasks. It exploits NumPy and its array structures allowing seamless integration with other libraries including SciPy and Matplotlib. It supports different platforms allowing it to run on Windows, Linux and macOS in addition to mobile operating systems.
OpenCV has been used in various domain supporting applications in image pre-processing, object detection, segmentation, face detection and recognition, face pose estimation and alignment, augmented reality, navigation and tracking [5-12]. Moreover, OpenCV includes a wealth of pre-defined functions and provides a collection of machine learning libraries including boosting, decision trees, KNN, Naïve Bayes, random forest, support vector machine and deep neural networks.
In the following sections we will cover some of the functions offered by the OpenCV including object detection, features extraction and classification.
Installing OpenCV
The first step is to install OpenCV-Python. The initial requirement is to have Python and pip (a package management system) installed. To install OpenCV run the following line command:
pip install opencv-pythonTo successfully run this code in Jupyter Notebook, an exclamation mark (!) needs to be used before pip:
!pip install opencv-pythonThis will initiate downloading OpenCV and installing dependencies (NumPy). Upon completion, a message to confirm successful installation will be displayed. The library can subsequently be imported:
import cv2Opening and displaying the image file
OpenCV allows reading different types of images (JPG, PNG, etc) which can be grayscale or colour images. The built-in function o read an image is cv2.imread() with the following syntax structure:
image = cv2.imread(filename, flags)In the above example, "image" is the variable into which the “filename” information will be stored. As we can see there are two inputs: “filename” and “flag”:
- filename: a required argument and the location of the image which can be provided as a relative or an absolute path.
- flags: this is an optional argument used to read an image in a particular format. For example, grayscale, colour or with alpha channel. The default value is cv2.IMREAD_COLOR or 1 which loads the image as a colour image and the following describes the flags in more detail:
- cv2.IMREAD_GRAYSCALE or 0: loads image in grayscale mode.
- cv2.IMREAD_COLOR or 1: the default flag which loads a colour image. Any transparency of the image will be neglected.
- cv2.IMREAD_UNCHANGED or -1: loads image including an alpha channel.
To display an image file, we can utilise the imshow() built-in function to display a representation of the NumPy 2D array that is produced after reading the image using the imread() function. It is important to emphasise that the OpenCV library uses a different format for storing channel information; BGR instead of RGB order. To properly show the original colour image in RGB, we need to swap the order of channels. This can be achieved by either NumPy slicing or cv2.cvtColor() built-in function. The entire process is demonstrated in the following block of code and the output images are illustrated in Figure 2.
f = plt.figure(figsize=(25, 20))
f.add_subplot(1, 4, 1)
# The return from imread is numpy 2D array representing the image
img_gray = cv2.imread("Resources/images/face.jpg", 0)
# We can use imshow to display a representation of the numpy 2D array. To display an image defining an appropriate colormap is required. For grascale image the colormap is "gray"
plt.imshow(img_gray, cmap="gray");
plt.grid(None)
plt.title("Image in gray");
# OpenCV library uses different format for storing channel information; BGR order convention instead of RGB order. To properly show the original colour image in RGB, we need to swap the order of channels.
f.add_subplot(1, 4, 2)
img_bgr = cv2.imread("Resources/images/face.jpg", 1)
plt.imshow(img_bgr);
plt.grid(None)
plt.title("Image in BGR");
# A way to reorder the channels to RGB:
f.add_subplot(1, 4, 3)
img_rgb = img_bgr[:, :, ::-1]
plt.imshow(img_rgb);
plt.grid(None)
plt.title("Image in RGB, manual swap");
Figure 2. Reading and displaying an image in RGB using OpenCV built-in functions.
Summary
In this article we talked about computer vision - the field of artificial intelligence that enables computers to derive meaningful information from images. We also discussed the history and capabilities of OpenCV - a free, cross-platform library for solving a wide range of computer vision problems.
In part two of this article we'll go into various techniques for feature extraction and image classification (e.g. SIFT, ORB, and FAST) and we'll show object classification using Deep Neural Networks.
Additional Resources
You can check the following additional resources:
- Free online courses on OpenCV - https://opencv.org/opencv-free-course/
- OpenCV official documentation - https://docs.opencv.org/4.x/
- There is an accompanying project with all code from this article, which you can access by signing up for the free Domino MLOps trial environment:
References
[1] N. Sharif, U. Nadeem, S. A. A. Shah, M. Bennamoun, and W. Liu, "Vision to language: Methods, metrics and datasets," in Machine Learning Paradigms: Springer, 2020, pp. 9-62.
[2] C. Rashtchian, P. Young, M. Hodosh, and J. Hockenmaier, "Collecting image annotations using amazon’s mechanical turk," in Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, 2010, pp. 139-147.
[3] S. Thorpe, D. Fize, and C. Marlot, "Speed of processing in the human visual system," nature, vol. 381, no. 6582, pp. 520-522, 1996.
[4] G. Bradski, "The openCV library," Dr. Dobb's Journal: Software Tools for the Professional Programmer, vol. 25, no. 11, pp. 120-123, 2000.
[5] A. A. Chaaraoui, P. Climent-Pérez, and F. Flórez-Revuelta, "Silhouette-based human action recognition using sequences of key poses," Pattern Recognition Letters, vol. 34, no. 15, pp. 1799-1807, 2013.
[6] N. Markuš, M. Frljak, I. S. Pandžić, J. Ahlberg, and R. Forchheimer, "Object detection with pixel intensity comparisons organized in decision trees," arXiv preprint arXiv:1305.4537, 2013.
[7] N. Markuš, M. Frljak, I. S. Pandžić, J. Ahlberg, and R. Forchheimer, "Eye pupil localization with an ensemble of randomized trees," Pattern recognition, vol. 47, no. 2, pp. 578-587, 2014.
[8] F. Timm and E. Barth, "Accurate eye centre localisation by means of gradients," Visapp, vol. 11, pp. 125-130, 2011.
[9] D. S. Bolme, B. A. Draper, and J. R. Beveridge, "Average of synthetic exact filters," in 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009: IEEE, pp. 2105-2112.
[10] X. Cao, Y. Wei, F. Wen, and J. Sun, "Face alignment by explicit shape regression," International journal of computer vision, vol. 107, no. 2, pp. 177-190, 2014.
[11] M. Danelljan, G. Häger, F. Khan, and M. Felsberg, "Accurate scale estimation for robust visual tracking," in British Machine Vision Conference, Nottingham, September 1-5, 2014, 2014: Bmva Press.
[12] K. Zhang, L. Zhang, and M.-H. Yang, "Fast compressive tracking," IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 10, pp. 2002-2015, 2014.

SHARE

Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.