
spaCy is a python library that provides capabilities to conduct advanced natural language processing analysis and build models that can underpin document analysis, chatbot capabilities, and all other forms of text analysis.
The spaCy library is available under the MIT license and is developed primarily by Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd from Explosion Explosion.AI.
The latest release, spaCy 3.0, brings many improvements to help build, configure and maintain your NLP models, including
- Newly trained and retrained transformer-based pipelines that lift accuracy scores significantly.
- Additional configuration capabilities to build your training workflow and tune your training runs
- Quickstart Widget to help build your configuration files
- Easier integration with other tools such as Streamlit, FastAPI, or Ray to build workflows that provide results to your end-user.
- Parallel/Distributed capabilities with Ray for faster training cycles
- Wrappers that enable you to bring other frameworks such as PyTorch and TensorFlow
These features combine to make spaCy better than ever at processing large volumes of text and tuning your configuration to match your specific use case in a way that provides better accuracy.
Retrieved from https://spacy.io/
Getting Started
Previously, we published a blog that covers the installation steps and an introduction into spaCy that processes raw text into an NLP document and walks through the steps required to analyze and visualize data in many different ways, including entity detection and sentiment analysis.
Improved transformer-based pipelines
The first step in processing raw text into an NLP workflow is to tokenize the text into a document object. This is often referred to as a processing pipeline. spaCy includes many different pre-built processing pipelines covering different languages and preference settings to provide higher accuracy or higher efficiency depending on your use case and the speed at which you need to process text.
These trained pipelines include components that perform different functions such as
- Entity Recognition - finding people, places, items, or timestamps within a document.
- Part of Speech - identifying noun, verb, adjective, and adverb within a document.
- Dependency Parser - identifying the relationship and ontology of words to assess their context.
These components are added as arguments during the initial phase of converting your raw text into an NLP document object.

spaCy processing pipeline diagram retrieved from https://spacy.io
Here, we parse three separate pieces of text into a single document and then run a summary of all found entities within the text.
import spacy
texts = ["David works as a Data Scientist at Domino Data Lab","Domino Data Lab is a company that provides enterprise-class data science capabilities through its platform.","David joined Domino Data Lab in February 2020."]
nlp = spacy.load("en_core_web_lg")
for doc in nlp.pipe(texts, disable=["tagger", "parser"]):
# Print all found entities within the document.
print([(ent.text, ent.label_) for ent in doc.ents])This code's output correctly identifies that a person, an organization, and a date have been entered within the document.
[('David', 'PERSON')]
[('Domino Data Lab', 'ORG')]
[('David', 'PERSON'), ('Domino Data Lab', 'ORG'), ('February 2020', 'DATE')]This is possible due to the pre-trained processing pipeline we call as part of our initial load - "en_core_web_lg". These pre-configured models are a good start for processing text; however, included in spaCy 3.0 is a widget to help you to optimize your configuration.

Bench-marking data from https://spacy.io
These models often trade efficiency versus quality score. For example, if we change the pre-trained model from "en_core_web_lg" to "en_core_web_sm" we see much quicker processing times for the document. Still, we also note that it doesn't correctly tag Domino Data Lab as an organization, instead of thinking that it is a person.
import spacy
texts = ["David works as a Data Scientist at Domino Data Lab","Domino Data Lab is a company that provides enterprise-class data science capabilities through its platform.","David joined Domino Data Lab in February 2020."
]
nlp = spacy.load("en_core_web_sm")
for doc in nlp.pipe(texts, disable=["tagger", "parser"]):
# Print all found entities within the document.
print([(ent.text, ent.label_) for ent in doc.ents])[('Domino Data', 'PERSON')]
[('David', 'PERSON'), ('Domino Data', 'PERSON'), ('February 2020', 'DATE')]These pre-configured models are a good start for processing text; however, included in spaCy 3.0 is a widget to help you to optimize your configuration.
Configuration file and Quick-start Widget
spaCy v3 introduces an extensive configuration system that allows you to create a configuration file containing the settings, hyperparameters, and NLP components you want to apply.
Configuration files can easily be called into your project.
python -m spacy init fill-config base_config.cfg config.cfgA configuration file's advantage is that there are no hidden elements to how your model is being processed. This lets you see the exact settings of a model run when looking back at your results, alongside the usual version control aspects of holding the configuration as a file.

How config files are used within spaCy
Configuration files also let you include custom models and functions that you have built-in other frameworks, providing flexibility to ensure that how you run your spaCy model is purpose-built for the use case at hand.
spaCy v3 also includes a convenient Quickstart widget that lets you generate a starting point configuration file built from many recommended settings that can be adjusted as you tune your model.
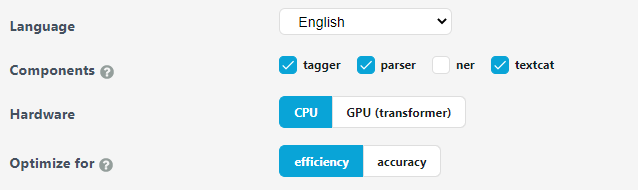
spaCy Quickstart widget retrieved from https://spacy.io
spaCy Projects
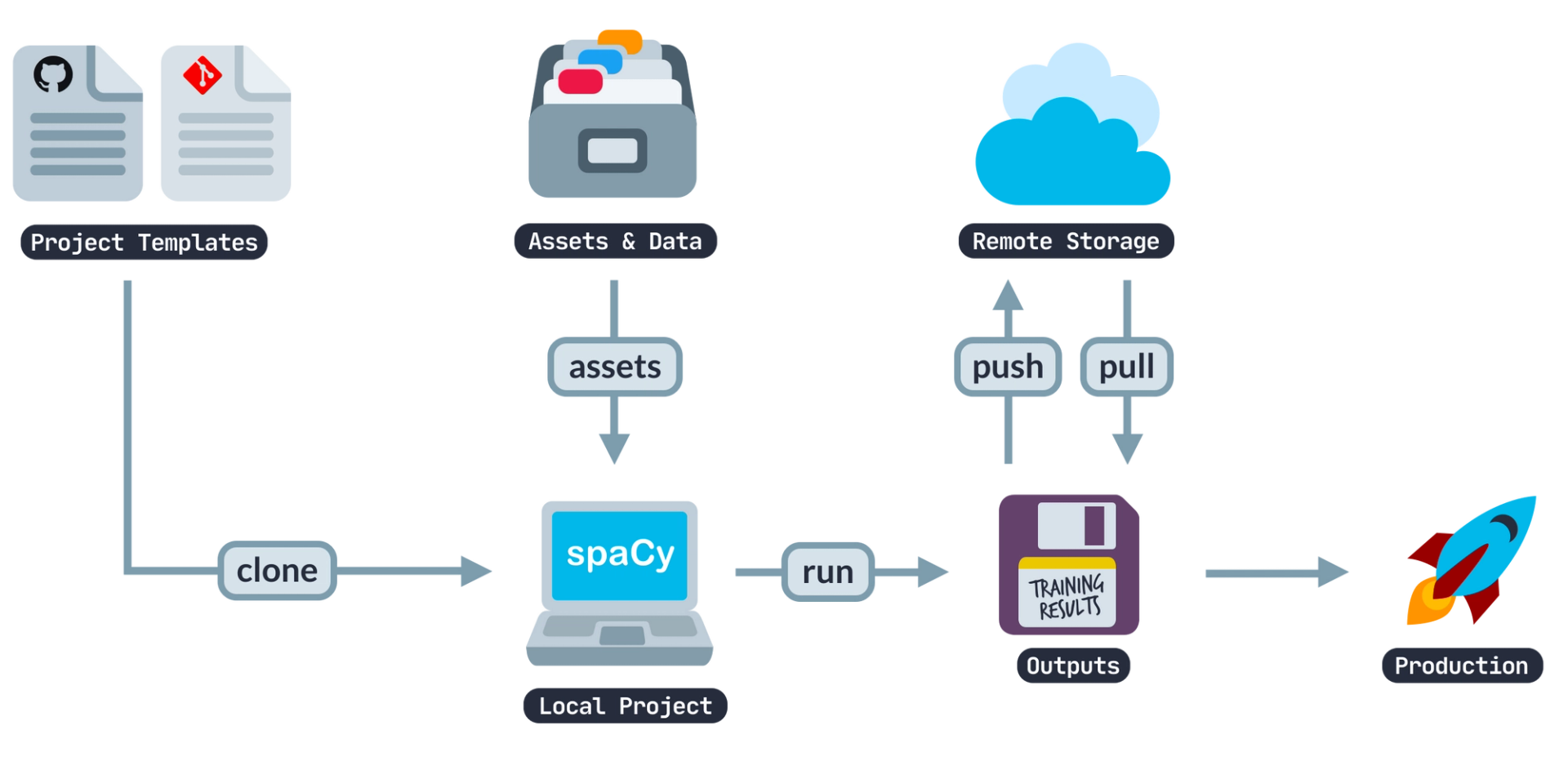
Projects are a brand new feature within spaCy v3 that lets you create and use reference project architecture that sets up patterns and practices for all of your NLP workflows.
Projects also include several pre-defined project templates designed to integrate with data science tools to let you track and manage your data, share your results through visualization, and serve your models as APIs.

Project templates available within spaCy
This ability to structure a typical NLP workflow inside your data science team helps build efficiency and a systemized way of tackling all NLP tasks inside your organization.
Conclusion
spaCy v3 represents a major improvement overall for the library. The newly trained processing pipeline significantly improves the accuracy of all output generated by spaCy. The inclusion of configuration files, project templates, and integrations allows you to more easily configure and control how NLP projects are run within your team and, in turn, improve the speed at which you can produce results for your end-users.
The improvement of existing components and inclusion of new components in the processing pipelines, such as dependency matching, sentence recognition, and morphological prediction, provide users a lot more capability to analyze text and produce accurate and relevant results. The addition of wrappers to allow you to call functions from other model libraries also extends this flexibility to customize how you build, train, and deploy your models.

Summary
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.