Domino Paves the Way for the Future of Enterprise Data Science with Latest Release
Nick Elprin2020-06-10 | 11 min read

Today, we announced the latest release of Domino’s data science platform which represents a big step forward for enterprise data science teams. We’re introducing groundbreaking new features – including On-demand Spark clusters, enhanced project management, and the ability to export models – that give enterprises unprecedented power to scale their data science capabilities by addressing common struggles.
I’m also proud to announce an exciting new product: Domino Model Monitor (DMM). DMM creates a “single pane of glass” to monitor the performance of all models across your entire organization — even models built or deployed outside of Domino. You can identify data drift, missing information, and other issues, and take corrective action before bigger problems occur.
We invite you to join one of our upcoming webinars on Domino 4.2 and DMM to see the new capabilities first hand, and keep reading to learn more today.
Domino’s best-in-class Workbench is now even more powerful for data scientists
The Workbench is the core of the Domino platform, enabling collaborative R&D for data science teams with the tools and languages they already know and trust. Data science teams love the Workbench component because it helps them create a knowledge flywheel, accelerating the research process by automating DevOps work, making work reproducible and reusable, and tracking and organizing ML experiments.
Domino 4.2 offers several game-changing Workbench experiences for data scientists and data science leaders.
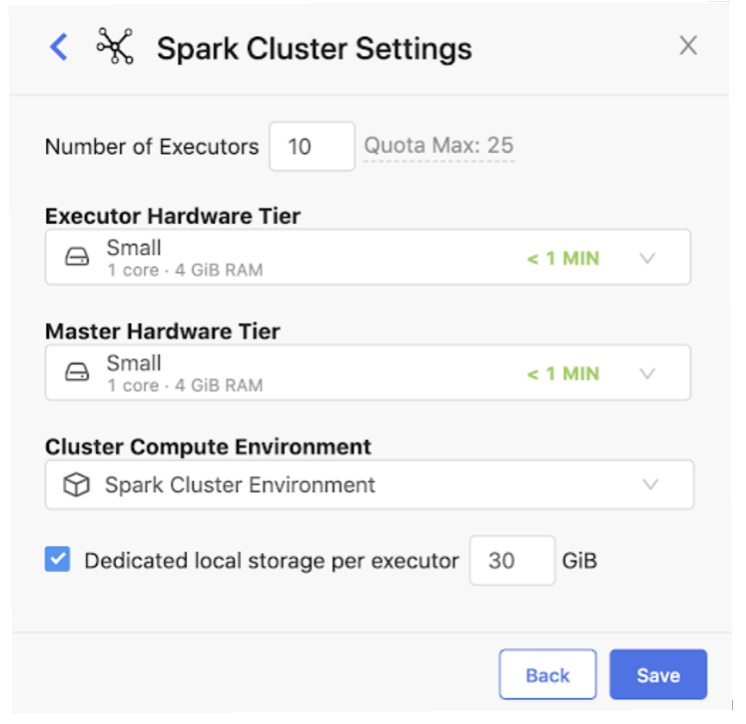
- On-Demand Spark clusters: Data scientists can now, with one click, spin up their own Spark clusters to use for fast, distributed processing of the analyses running in Domino. They choose the cluster size they need, and Domino takes care of the DevOps work on the back end to make sure that the packages and dependencies are properly distributed across the cluster. That makes data scientists more productive and reduces headaches for IT organizations.With On-Demand Spark in Domino, data science teams can unite Spark and non-Spark workloads in a single unified platform.
- The Workspace user experience has been redesigned to make data scientists much more productive when doing interactive exploratory analysis. Now when you launch tools such as Jupyter or RStudio in Domino, it’s easier to see your file changes, resource (CPU, memory) usage, and logs in one place. And because we have an open architecture, these UX improvements apply to any type of tool you’re using in Domino, including commercial tools like SAS Studio or MATLAB.
- Domino 4.2 also includes a preview of functionality for deeper integration with external git repositories (e.g., Github, Bitbucket, Gitlab).
Our open platform is now certified to run Microsoft AKS, and can export models to Amazon SageMaker.
We are committed to providing an open data science platform that allows data scientists to apply the right tool(s) to the task at hand, whether proprietary or open source. Domino connects with technologies spanning the end-to-end data science management lifecycle, from data prep and cleansing through model visualization and utilization, for a holistic, best-in-class solution to data science. And we believe IT teams should be able to choose the data science infrastructure that best suits their organizations’ needs for scalability, enterprise standardization, and ecosystem integration.
That’s why we recently replatformed Domino to be Kubernetes-native– laying the foundation to support today’s increasingly prevalent multi-cloud strategies. We plug into customers’ existing single or multi-tenant Kubernetes clusters, enabling more efficient utilization of underlying compute resources for data science workloads.
Domino 4.2 supports additional Kubernetes distributions and multi-tenancy. In particular, the platform is now certified to run Microsoft Azure Kubernetes Service (AKS), with support for Red Hat OpenShift coming soon. This builds on the platform’s existing support for open source Rancher, Amazon Elastic Kubernetes Service (EKS), Google Cloud Kubernetes (GKE), and VMWare Pivotal Container Service (PKS).
We’re also pleased to add the ability for data science teams to export a completed model for deployment in Amazon SageMaker. Today, many of the Fortune 100 companies that we’re proud to call customers use the model hosting function inside Domino to support their diverse business and operational requirements. But some customers prefer to use Amazon SageMaker for its own highly-scalable and low-latency hosting functionality. Domino 4.2 adds the ability to export a SageMaker-compatible Docker image with your model, which includes all of the packages, code, and more, to deploy the model directly in SageMaker.
Domino Model Monitor unifies the end-to-end model management process with model ops and governance.
Once models are in production, it’s critical to monitor their performance in case real-world data changes to necessitate model retraining or tuning. In many organizations, this responsibility falls to either the IT team, who has insufficient tools to assess model performance, or the data science team, taking time away from important new research. We believe model-driven businesses need better ways of managing models that are becoming increasingly critical to core business processes.
To that end, we’re thrilled to announce Domino Model Monitor (DMM). DMM lets companies monitor their models to detect drift and prediction performance issues before they cause financial loss or degraded customer experience.
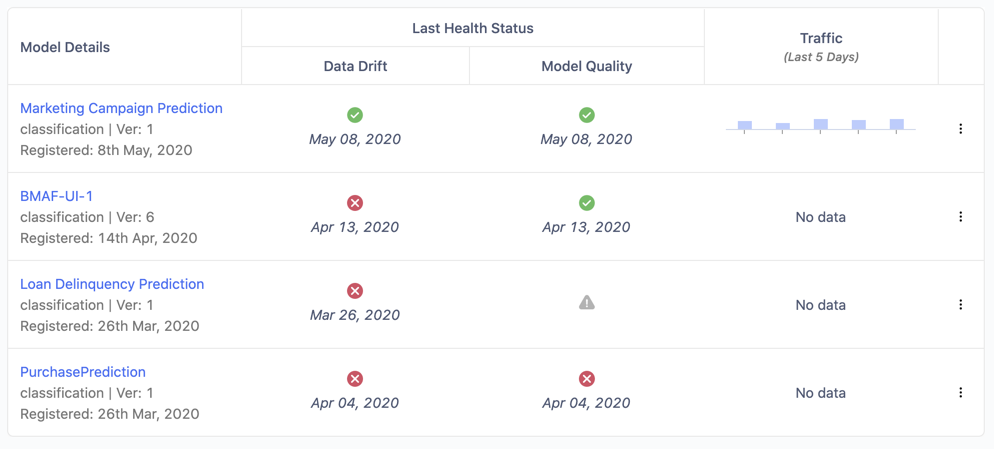
DMM allows companies to view all deployed models across their organization in a single portal, no matter the language, deployment infrastructure, or how they were created. It establishes a consistent approach for monitoring across teams and models so you can break down departmental silos, eliminate inconsistent or infrequent monitoring practices, and establish a standard for model health metrics across your organization.
It starts by monitoring production data that’s provided as an input to a model, and compares individual features to the counterparts that were used to originally train the model. This analysis of data drift is a great way to determine if customer preferences have changed, economic or competitive factors have impacted your business, or a data pipeline has broken and null values are feeding a model that was expecting more useful information.
You can also upload live prediction data and, optionally, any ground truth data so that prediction accuracy can be analyzed. If DMM detects data drift or a decrease in model accuracy using a threshold you control, it can provide an alert so data scientists can assess the model and decide what the best corrective action should be. By allowing data science teams to focus on monitoring of potential “at-risk” models, they have more time for experimentation and problem-solving. And IT teams can sleep easier knowing that they have everything they need to deeply understand model performance in an easy-to-understand dashboard.
Security and project management improvements reflect our unwavering commitment to the enterprise.
We’re on a mission to harden data science as an enterprise-grade business capability in order to maximize the impact of data science teams. In addition to the product improvements highlighted above that strengthen our data science platform across key functional areas, Domino 4.2 includes additional security updates and powerful new product management capabilities that are critical to earning trust and driving visibility among enterprise teams.
The Knowledge Center inside Domino is the place where an organizations’ data science learnings are centralized so that data scientists can find, reuse, reproduce, and collaborate – leading to more efficient experimentation.
In Domino 4.2 we’ve added the ability for data science leaders to more effectively manage their data science teams and their work. They can set goals for projects, define custom stages to assess their research process, and drill into projects to review recent activity, blockers, and progress toward goals. Data science leaders gain visibility into projects and workloads across their teams, improving transparency for all stakeholders. This also helps data science leaders surface best practices and improve communication and collaboration, which ultimately paves the way for faster research.
For many organizations, this approach to project management is enough to manage the end-to-end process for building and deploying data science projects at scale. However, many organizations have standardized on using Jira to manage data science teams, and we’re excited to deliver on our promise for Jira integration in Domino 4.2. Project goals and stages can be directly linked to Jira tasks to integrate with established tools and processes.

Wrap-up
The team here at Domino has put a lot of energy into this latest release, and we’re excited to bring these new innovations to data science teams who are pushing the envelopes of innovation across all industries that they operate in. We appreciate the ongoing feedback received from customers and friends throughout the development process and are inspired to keep improving Domino to remain the best-in-class system of record for research in the enterprise.
Here are some additional resources to help you learn more about Domino and the newest capabilities offered in Domino 4.2 and Domino Model Monitor:
- Learn about the Domino data science platform.
- Try Domino.
- Attend the live webinar on June 25 to learn more about Domino 4.2.
- Attend the live webinar on July 14 to learn more about model monitoring best practices and Domino Model Monitor.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
Summary
- Domino’s best-in-class Workbench is now even more powerful for data scientists
- Our open platform is now certified to run Microsoft AKS, and can export models to Amazon SageMaker.
- Domino Model Monitor unifies the end-to-end model management process with model ops and governance.
- Security and project management improvements reflect our unwavering commitment to the enterprise.
- Wrap-up
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.