
You can now run JupyterLab in Domino, using a new Domino feature that lets data scientists specify any web-based tools they want to run on top of the Domino platform.
Introduction
Domino is a data science platform that supports the entire data science lifecycle, from exploratory analysis through experimentation and all the way to deployment. Throughout those stages of work, Domino lets data scientists work on scalable self-service infrastructure while enabling best practices like reproducibility and collaboration.
From the beginning, our philosophy has been to be an open platform that supports the latest open source tools. Most of the data scientists who use Domino work with Python, R, Jupyter, and RStudio, though we support a variety of others. Today, we’re excited to announce support for JupyterLab, along with a flexible plugin framework that lets data scientists add their own tools to run on the Domino platform.
How to use JupyterLab in Domino
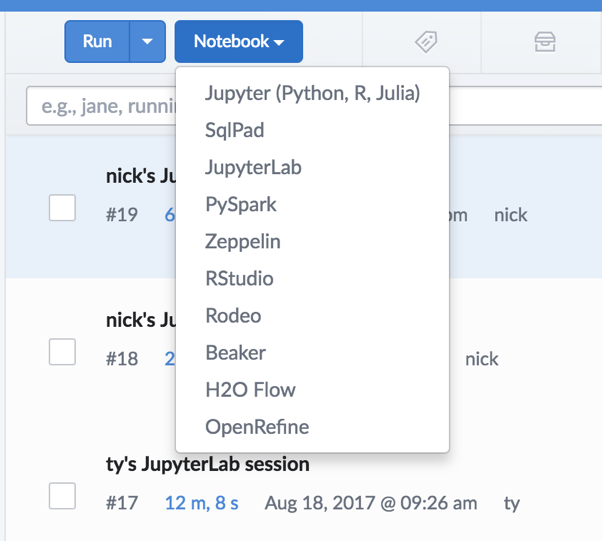
1) From the “notebook” dropdown menu, choose “JupyterLab"
2) When the green “open session” button appears, click it
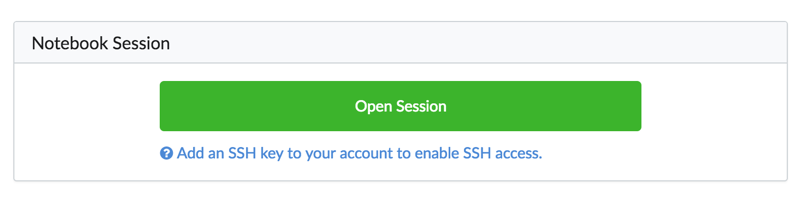
You’ll be dropped into a JupyterLab environment, where you can play with all its functionality. Note that this is running through Domino’s execution layer: we’ve launched it on a hardware tier that you can choose, and we’ve setup all the necessary network configuration to drop you into the environment. If you save your work, your changes will be committed back to the Domino project so your colleagues can use them.
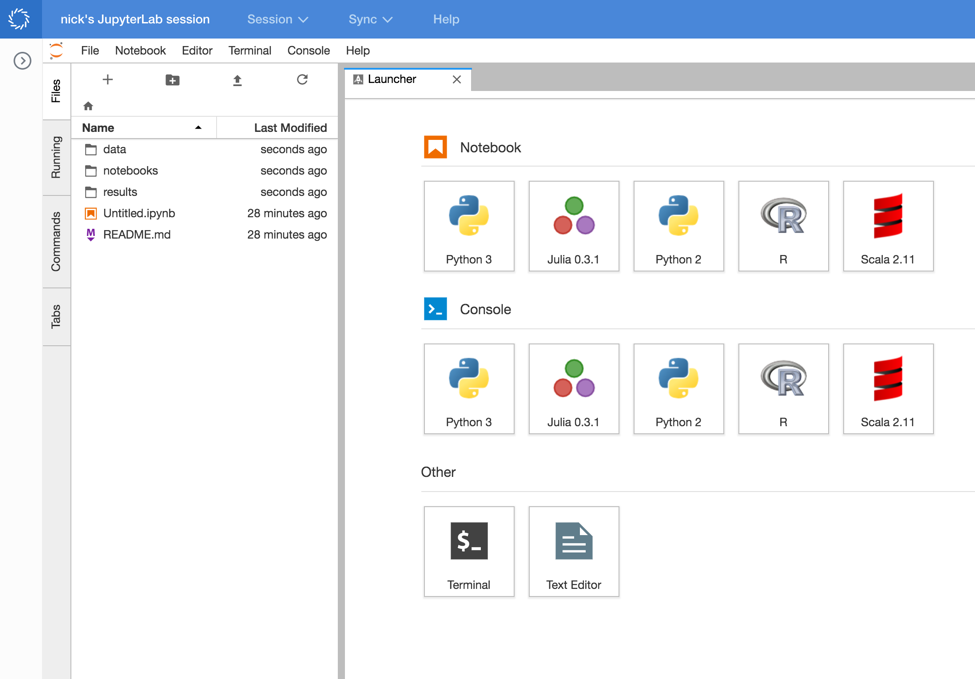
JupyterLab is still in alpha. You can read more about it on its Github page.
The configuration of JupyterLab we have set up in Domino has support for the Python, Julia, and Scala kernels; currently the R kernel won’t work properly.
Why JupyterLab
Jupyter Notebooks are fantastic for interactive, exploratory analysis. Often, though, data scientists need to work in projects that have many files and scripts that aren’t used interactively. They want a proper IDE, not just a notebook — so they can edit source files, use multiple tabs, browse files, and more. For work like this, data scientists use rich editors on their desktop, such as PyCharm, Sublime, or even emacs or vim. JupyterLab offers many of the features those tools have, while providing the benefits of a Notebook experience.
The JupyterLab project on Github describes itself as:
“JupyterLab is the next generation user interface for Project Jupyter. It offers all the familiar building blocks of the classic Jupyter Notebook (notebook, terminal, text editor, file browser, rich outputs, etc.) in a flexible and powerful user interface that can be extended through third party extensions that access our public APIs. Eventually, JupyterLab will replace the classic Jupyter Notebook.”
You can watch this nice talk about JupyterLab from PyCon Seattle 2017. Among the variety of features beyond Notebooks, some of our favorites are:
- Flexible keybindings, so you can use vim or emacs shortcuts
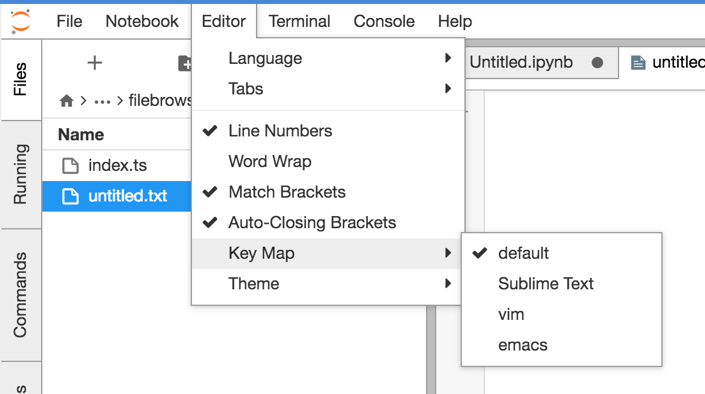
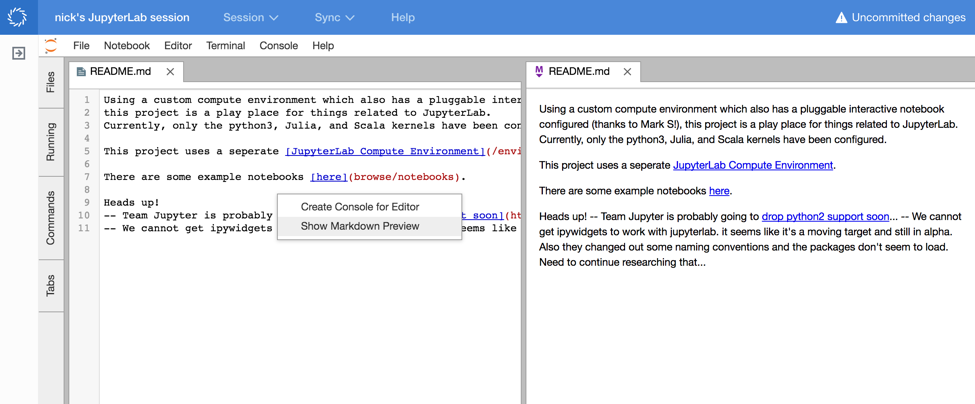
- Configurable window pane arrangement, which among other things, lets you edit and preview markdown side by side
- View as CSV files as tables
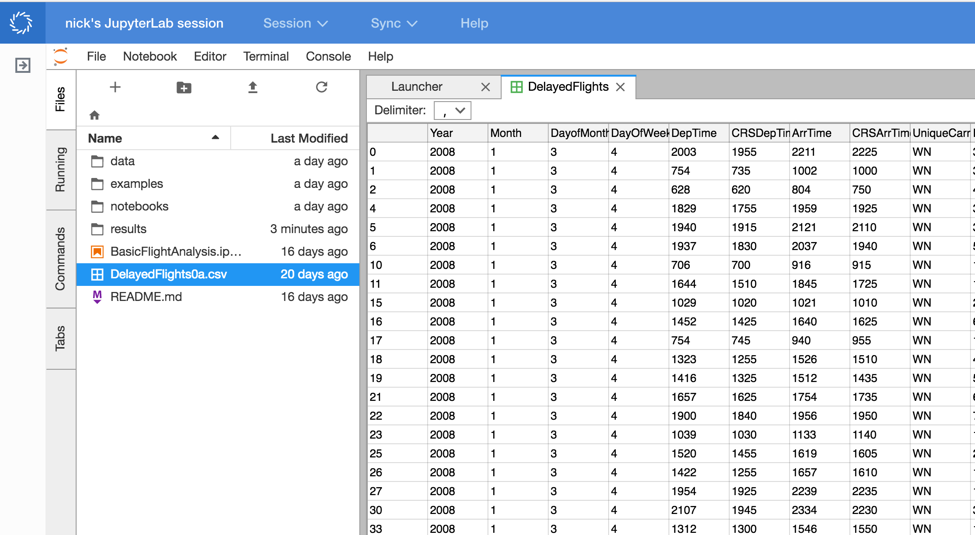
Pluggable interactive tools
There’s something special about how Domino supports JupyterLab: instead of hard-coding support for JupyterLab, we built an extensibility point that allows data scientists to run whatever tools they want on the Domino platform.
Over the last couple of years working with data science teams, we’ve had requests to support a variety of interactive tools, for example, Zeppelin, Hue, Beaker, and others. So we built a plugin point in Domino so you can specify your own tools to use. This builds on top of our Compute Environment functionality, which lets you specify packages and configuration via Docker — Domino keeps your Environments built, cached, reproducible, revisioned and shareable.
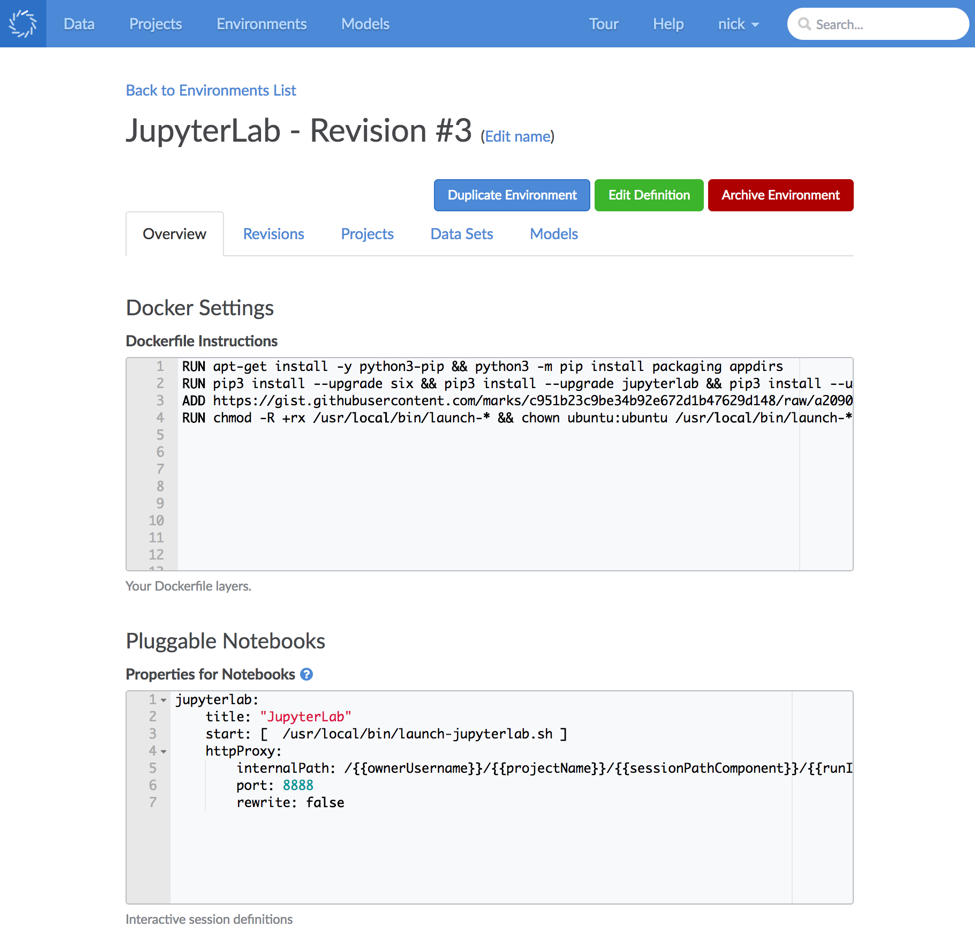
Now, Domino Compute Environments also let you specify which interactive tools should be available. This works using a YAML configuration format. For example, here’s the definition for JupyterLab in one of our Compute Environments:
jupyterlab:
title: "JupyterLab"
start: [ /usr/local/bin/launch-jupyterlab.sh ]
httpProxy:
internalPath: /{{ownerUsername}}/{{projectName}}/{{sessionPathComponent}}/{{runId}}
port: 8888
rewrite: false
Here’s how it looks in the Compute Environment we defined for this demo project. Notice that the definition of the Environment contains the instructions for installing JupyterLab and the YAML to tell Domino how to launch the tool. Compute Environments in Domino are revisioned and shareable, so if one of these definitions changes, that change will be available to anyone using the environment; and if something breaks, you can revert to an old version to restore functionality.
When you add tools like this to your Compute Environment, Domino makes them available for anyone to spin up through our UI. We’ll add your custom tools to our standard tools, which include Jupyter Notebooks and RStudio. When you launch a workspace with one of these tools, Domino will run it on whatever hardware you choose, in a container with a consistent set of packages, with all your project files loaded. This makes it easy for you to collaborate with colleagues and scale your infrastructure on demand.
Are there interesting web-based data science tools you’d like to see running in Domino? Let us know and we’ll run a blog post show how it works.
More about Domino
This post is focused on how to use Domino to run JupyterLab. The full platform offers much more, including:
- Running other interactive tools on scalable infrastructure, including Jupyter Notebooks and RStudio
- Running batch experiments such as model training tasks across elastic compute resources, to develop breakthrough research faster
- Tracking of work in a central place, to facilitate collaboration and reproducibility
- Easy ways to deploy or productionize data science work, either as scheduled jobs, production-grade APIs, or self-service apps and dashboards for business stakeholders
Check out Domino to learn more.

Domino Data Lab empowers the largest AI-driven enterprises to build and operate AI at scale. Domino’s Enterprise AI Platform unifies the flexibility AI teams want with the visibility and control the enterprise requires. Domino enables a repeatable and agile ML lifecycle for faster, responsible AI impact with lower costs. With Domino, global enterprises can develop better medicines, grow more productive crops, develop more competitive products, and more. Founded in 2013, Domino is backed by Sequoia Capital, Coatue Management, NVIDIA, Snowflake, and other leading investors.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.