
This article provides an excerpt "Deep Reinforcement Learning" from the book, Deep Learning Illustrated by Krohn, Beyleveld, and Bassens. The article includes an overview of reinforcement learning theory with focus on the deep Q-learning. It also covers using Keras to construct a deep Q-learning network that learns within a simulated video game environment. Many thanks to Addison-Wesley Professional for the permission to excerpt the chapter.
Introduction
Recent feats in machine learning, like developing a program to defeat a human in a game Go, have been powered by reinforcement learning. Reinforcement learning is the process of training a program to attain a goal through trial and error by incentivizing it with a combination of rewards and penalties. An agent works in the confines of an environment to maximize its rewards. From games to simulating evolution, reinforcement learning has been used as a tool to explore emergent behavior. As Domino seeks to help data scientists accelerate their work, we reached out to AWP Pearson for permission to excerpt the chapter “Deep Reinforcement Learning” from the book, Deep Learning Illustrated: A Visual, Interactive Guide to Artificial Intelligence by Krohn, Beyleveld, and Bassens. Many thanks to AWP Pearson for providing the permissions to excerpt the work and enabling us to provide a complementary Domino project.
This project works through the classic Cart-Pole problem, that is balancing a pole attached to a moveable cart. The contents will cover
- Using Keras and OpenAI Gym to create a deep learning model and provide the environment to train
- Defining the agent
- Modeling interactions between the agent and the environment
Deep Reinforcement Learning
In Chapter 4, we introduced the paradigm of reinforcement learning (as distinct from supervised and unsupervised learning), in which an agent (e.g., an algorithm) takes sequential actions within an environment. The environments—whether they be simulated or real world—can be extremely complex and rapidly changing, requiring sophisticated agents that can adapt appropriately in order to succeed at fulfilling their objective. Today, many of the most prolific reinforcement learning agents involve an artificial neural network, making them deep reinforcement learning algorithms.
In this chapter, we will
- Cover the essential theory of reinforcement learning in general and, in particular, a deep reinforcement learning model called deep Q-learning
- Use Keras to construct a deep Q-learning network that learns how to excel within simulated, video game environments
- Discuss approaches for optimizing the performance of deep reinforcement learning agents
- Introduce families of deep RL agents beyond deep Q-learning
Essential Theory of Reinforcement Learning
Recall from Chapter 4, specifically, Figure 4.3 that reinforcement learning is a machine learning paradigm involving:
- An agent taking an action within an environment (let’s say the action is taken at some timestep t).
- The environment returning two types of information to the agent:
- Reward: This is a scalar value that provides quantitative feedback on the action that the agent took at timestep t. This could, for example, be 100 points as a reward for acquiring cherries in the video game Pac-Man. The agent’s objective is to maximize the rewards it accumulates, and so rewards are what reinforce productive behaviors that the agent discovers under particular environmental conditions.
- State: This is how the environment changes in response to an agent’s action. During the forthcoming timestep (t + 1), these will be the conditions for the agent to choose an action in.
- Repeating the above two steps in a loop until reaching some terminal state. This terminal state could be reached by, for example, attaining the maximum possible reward, attaining some specific desired outcome (such as a self-driving car reaching its programmed destination), running out of allotted time, using up the maximum number of permitted moves in a game, or the agent dying in a game.
Reinforcement learning problems are sequential decision-making problems. In Chapter 4, we discussed a number of particular examples of these, including:
- Atari video games, such as Pac-Man, Pong, and Breakout
- Autonomous vehicles, such as self-driving cars and aerial drones
- Board games, such as Go, chess, and shogi
- Robot-arm manipulation tasks, such as removing a nail with a hammer
The Cart-Pole Game
In this chapter, we will use OpenAI Gym—a popular library of reinforcement learning environments (examples provided in Figure 4.13) [int the book]—to train an agent to play Cart-Pole, a classic problem among academics working in the field of control theory. In the Cart-Pole game:
- The objective is to balance a pole on top of a cart. The pole is connected to the cart at a purple dot, which functions as a pin that permits the pole to rotate along the horizontal axis, as illustrated in Figure 13.1. [Note: An actual screen capture of the Cart-Pole game is provided in Figure 4.13a.]

- The cart itself can only move horizontally, either to the left or to the right. At any given moment—at any given timestep—the cart must be moved to the left or to the right; it can’t remain stationary.
- Each episode of the game begins with the cart positioned at a random point near the center of the screen and with the pole at a random angle near vertical.
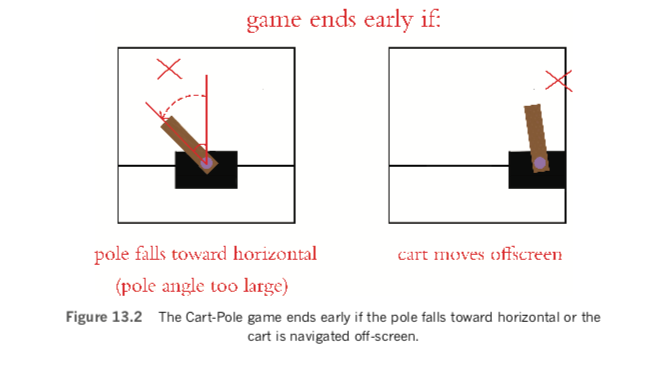
- As shown in Figure 13.2, an episode ends when either
- The pole is no longer balanced on the cart—that is, when the angle of the
pole moves too far away from vertical toward horizontal - The cart touches the boundaries—the far right or far left of the screen
- In the version of the game that you’ll play in this chapter, the maximum number of timesteps in an episode is 200. So, if the episode does not end early (due to los- ing pole balance or navigating off the screen), then the game will end after 200 timesteps.
- One point of reward is provided for every timestep that the episode lasts, so the maximum possible reward is 200 points.
The Cart-Pole game is a popular introductory reinforcement learning problem because it’s so simple. With a self-driving car, there are effectively an infinite number of possible environmental states: As it moves along a road, its myriad sensors—cameras, radar, lidar, accelerometers, microphones, and so on—stream in broad swaths of state information from the world around the vehicle, on the order of a gigabyte of data per second.[Note: Same principle as radar, but uses lasers instead of sound. The Cart-Pole game, in stark contrast, has merely four pieces of state information:
- The position of the cart along the one-dimensional horizontal axis
- 2. The cart’s velocity
- The angle of the pole
- The pole’s angular velocity
Likewise, a number of fairly nuanced actions are possible with a self-driving car, such as accelerating, braking, and steering right or left. In the Cart-Pole game, at any given timestep t, exactly one action can be taken from only two possible actions: move left or move right.
Markov Decision Processes
Reinforcement learning problems can be defined mathematically as something called a Markov decision process. MDPs feature the so-called Markov property—an assumption that the current timestep contains all of the pertinent information about the state of the environment from previous timesteps. With respect to the Cart-Pole game, this means that our agent would elect to move right or left at a given timestep t by considering only the attributes of the cart (e.g., its location) and the pole (e.g., its angle) at that particular timestep t. [Note: The Markov property is assumed in many financial-trading strategies. As an example, a trading strategy might take into account the price of all the stocks listed on a given exchange at the end of a given trading day, while it does not consider the price of the stocks on any previous day.]
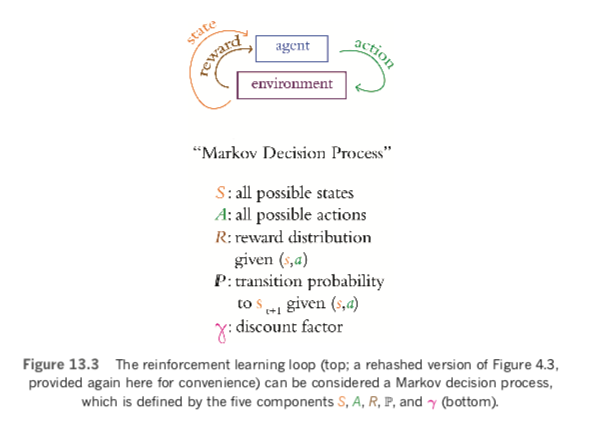
As summarized in Figure 13.3, the MDP is defined by five components:
- S is the set of all possible states. Following set-theory convention, each individual possible state (i.e., a particular combination of cart position, cart velocity, pole angle, and angular velocity) is represented by the lowercase s. Even when we consider the relatively simple Cart-Pole game, the number of possible recombinations of its four state dimensions is enormous. To give a couple of coarse examples, the cart could be moving slowly near the far-right of the screen with the pole balanced vertically, or the cart could be moving rapidly toward the left edge of the screen with the pole at a wide angle turning clockwise with pace.
- A is the set of all possible actions. In the Cart-Pole game, this set contains only two elements (left and right); other environments have many more. Each individual possible action is denoted as a.
- R is the distribution of reward given a state-action pair—some particular state paired with some particular action—denoted as (s, a). It’s a distribution in the sense of being a probability distribution: The exact same state-action pair (s, a) might randomly result in different amounts of reward r on different occasions. [Note: Although this is true in reinforcement learning in general, the Cart-Pole game in particular is a relatively simple environment that is fully deterministic. In the Cart-Pole game, the exact same state-action pair (s, a) will in fact result in the same reward every time. For the purposes of illustrating the principles of reinforcement learning in general, we use examples in this section that imply the Cart-Pole game is less deterministic than it really is.] The details of the reward distribution R—its shape, including its mean and variance—are hidden from the agent but can be glimpsed by taking actions within the environment. For example, in Figure 13.1, you can see that the cart is centered within the screen and the pole is angled slightly to the left. [Note: For the sake of simplicity, let’s ignore cart velocity and pole angular velocity for this example, because we can’t infer these state aspects from this static image.] We’d expect that pairing the action of moving left with this state s would, on average, correspond to a higher expected reward r relative to pairing the action of moving right with this state: Moving left in this state s should cause the pole to stand more upright, increasing the number of timesteps that the pole is kept balanced for, thereby tending to lead to a higher reward r. On the other hand, the move right in this state s would increase the probability that the pole would fall toward horizontal, thereby tending toward an early end to the game and a smaller reward r.
- P, like R, is also a probability distribution. In this case, it represents the probability of the next state (i.e., st+1) given a particular state-action pair (s, a) in the current timestep t. Like R, the P distribution is hidden from the agent, but again aspects of it can be inferred by taking actions within the environment. For example, in the Cart-Pole game, it would be relatively straightforward for the agent to learn that the left action corresponds directly to the cart moving leftward. [Note: As with all of the other artificial neural networks in this book, the ANNs within deep reinforcement learning agents are initialized with random starting parameters. This means that, prior to any learning (via, say, playing episodes of the Cart-Pole game), the agent has no awareness of even the simplest relationships between some state-action pair (s,a) and the next state st+1. For example, although it may be intuitive and obvious to a human player of the Cart-Pole game that the action left should cause the cart to move leftward, nothing is “intuitive” or “obvious” to a randomly initialized neural net, and so all relationships must be learned through gameplay.] More- complex relationships—for example, that the left action in the state s captured in Figure 13.1 tends to correspond to a more vertically oriented pole in the next state st+1—would be more difficult to learn and so would require more gameplay.
- γ (gamma) is a hyperparameter called the discount factor (also known as decay). To explain its significance, let’s move away from the Cart-Pole game for a moment and back to Pac-Man. The eponymous Pac-Man character explores a two-dimensional surface, gaining reward points for collecting fruit and dying if he gets caught by one of the ghosts that’s chasing him. As illustrated by Figure 13.4, when the agent considers the value of a prospective reward, it should value a reward that can be attained immediately (say, 100 points for acquiring cherries that are only one pixel’s distance away from Pac-Man) more highly than an equivalent reward that would require more timesteps to attain (100 points for cherries that are a distance of 20 pixels away). Immediate reward is more valuable than some distant reward, because we can’t bank on the distant reward: A ghost or some other hazard could get in Pac-Man’s way. [Note: The γ discount factor is analogous to the discounted cash flow calculations that are common in accounting: Prospective income a year from now is discounted relative to income expected today. Later in this chapter, we introduce concepts called value functions (V ) and Q-value functions (Q). Both V and Q incorporate γ because it prevents them from becoming unbounded (and thus computationally impossible) in games with an infinite number of possible future timesteps.] If we were to set γ = 0.9, then cherries one timestep away would be considered to be worth 90 points, [Note: 100 ×γt = 100 × 0.91 = 90] whereas cherries 20 timesteps away would be considered to be worth only 12.2 points. [Note: 100×γt =100×0.920 =12.16 ]
The Optimal Policy
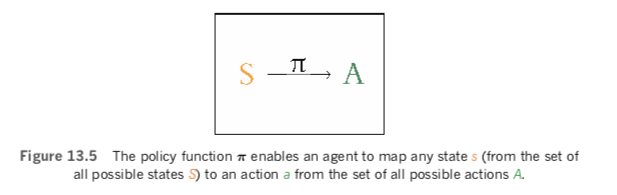
The ultimate objective with an MDP is to find a function that enables an agent to take an appropriate action a (from the set of all possible actions A) when it encounters any particular state s from the set of all possible environmental states S. In other words, we’d like our agent to learn a function that enables it to map S to A. As shown in Figure 13.5, such a function is denoted by π and we call it the policy function.
The high-level idea of the policy function π, using vernacular language, is this: Regardless of the particular circumstance the agent finds itself in, what is the policy it should follow that will enable it to maximize its reward? For a more concrete definition of this reward-maximization idea, you are welcome to pore over this:

In this equation:
- J(π) is called an objective function. This is a function that we can apply machine learning techniques to in order to maximize reward. [Note: The cost functions (a.k.a. loss functions) referred to throughout this book are examples of objective functions. Whereas cost functions return some cost value C, the objective function J(π) returns some reward value r. With cost functions, our objective is to minimize cost, so we apply gradient descent to them (as depicted by the valley- descending trilobite back in Figure 8.2). With the function J(π), in contrast, our objective is to maximize reward, and so we technically apply gradient ascent to it (conjuring up Figure 8.2 imagery, imagine a trilobite hiking to identify the peak of a mountain) even though the mathematics are the same as with gradient descent.]
- π represents any policy function that maps S to A.
- π∗ represents a particular, optimal policy (out of all the potential π policies) for mapping S to A. That is, π∗ is a function that—fed any state s—will return an action a that will lead to the agent attaining the max-imum possible discounted future reward.

- To calculate the discounted future reward
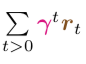
over all future timesteps (i.e., t>0), we do the following.
- Multiply the reward that can be attained in any given future timestep (rt) by the discount factor of that timestep (γt).
- Accumulate these individual discounted future rewards
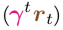
by summing them all up (using Σ ).
Essential Theory of Deep Q-Learning Networks
In the preceding section, we defined reinforcement learning as a Markov decision process. At the end of the section, we indicated that as part of an MDP, we’d like our agent— when it encounters any given state s at any given timestep t—to follow some optimal policy π∗ that will enable it to select an action a that maximizes the discounted future reward it can obtain. The issue is that—even with a rather simple reinforcement learning problem like the Cart-Pole game—it is computationally intractable (or, at least, extremely computationally inefficient) to definitively calculate the maximum cumulative discounted future reward,
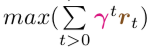
Because of all the possible future states S and all the possible actions A that could be taken in those future states, there are way too many possible future outcomes to take into consideration. Thus, as a computational shortcut, we’ll describe the Q-learning approach for estimating what the optimal action a in a given situation might be.
Value Functions
The story of Q-learning is most easily described by beginning with an explanation of value functions. The value function is defined by V π (s). It provides us with an indication of how valuable a given state s is if our agent follows its policy π from that state onward.
As a simple example, consider yet again the state s captured in Figure 13.1. [Note: As we did earlier in this chapter, let’s consider cart position and pole position only, because we can’t speculate on cart velocity or pole angular velocity from this still image.] Assuming our agent already has some reasonably sensible policy π for balancing the pole, then the cumulative discounted future reward that we’d expect it to obtain in this state is prob- ably fairly large because the pole is near vertical. The value V π (s), then, of this particular state s is high.
On the other hand, if we imagine a state sh where the pole angle is approaching horizontal, the value of it—V π(sh)—is lower, because our agent has already lost control of the pole and so the episode is likely to terminate within the next few timesteps.
Q-Value Functions
The Q-value function builds on the value function by taking into account not only state: It considers the utility of a particular action when that action is paired with a given state—that is, it rehashes our old friend, the state-action pair symbolized by (s, a). Thus, where the value function is defined by V π (s), the Q-value function is defined by Qπ (s, a). [Note: The “Q” in Q-value stands for quality but you seldom hear practitioners calling these “quality-value functions.”]
Let’s return once more to Figure 13.1. Pairing the action left (let’s call this aL) with this state s and then following a pole-balancing policy π from there should generally correspond to a high cumulative discounted future reward. Therefore, the Q-value of this state-action pair (s, aL) is high.
In comparison, let’s consider pairing the action right (we can call it aR) with the state s from Figure 13.1 and then following a pole-balancing policy π from there. Although this might not turn out to be an egregious error, the cumulative discounted future reward would nevertheless probably be somewhat lower relative to taking the left action. In this state s, the left action should generally cause the pole to become more vertically oriented (enabling the pole to be better controlled and better balanced), whereas the rightward action should generally cause it to become somewhat more horizontally oriented—thus, less controlled, and the episode somewhat more likely to end early. All in all, we would expect the Q-value of (s, aL ) to be higher than the Q-value of (s, aR).
Estimating an Optimal Q-Value
When our agent confronts some state s, we would then like it to be able to calculate the optimal Q-value, denoted as Q∗ (s, a). We could consider all possible actions, and the action with the highest Q-value—the highest cumulative discounted future reward— would be the best choice.
In the same way that it is computationally intractable to definitively calculate the optimal policy π∗ (Equation 13.1) even with relatively simple reinforcement learning problems, so too is it typically computationally intractable to definitively calculate an optimal Q-value, Q∗(s, a). With the approach of deep Q-learning (as introduced in Chapter 4; see Figure 4.5), however, we can leverage an artificial neural network to estimate what the optimal Q-value might be. These deep Q-learning networks (DQNs for short) rely on this equation:

In this equation:
- The optimal Q-value (Q∗ (s, a)) is being approximated.
- The Q-value approximation function incorporates neural network model parameters (denoted by the Greek letter theta, θ) in addition to its usual state s and action a inputs. These parameters are the usual artificial neuron weights and biases that we have become familiar with since Chapter 6.
In the context of the Cart-Pole game, a DQN agent armed with Equation 13.2 can, upon encountering a particular state s, calculate whether pairing an action a (left or right) with this state corresponds to a higher predicted cumulative discounted future reward. If, say, left is predicted to be associated with a higher cumulative discounted future reward, then this is the action that should be taken. In the next section, we’ll code up a DQN agent that incorporates a Keras-built dense neural net to illustrate hands-on how this is done.
For a thorough introduction to the theory of reinforcement learning,
including deep Q-learning networks, we recommend the recent edition of
Richard Sutton (Figure 13.6) and Andrew Barto’s Reinforcement Learning:
An Introduction,15 which is available free of charge at bit.ly/SuttonBarto.

Defining a DQN Agent
Our code for defining a DQN agent that learns how to act in an environment—in this particular case, it happens to be the Cart-Pole game from the OpenAI Gym library of environments—is provided within our Cartpole DQN Jupyter notebook. [Note: Our DQN agent is based directly on Keon Kim’s, which is available at his GitHub repository at bit.ly/keonDQN.] Its dependencies are as follows:
import random
import gym
import numpy as np
from collections import deque
from keras.models import Sequential from keras.layers import Dense
from keras.optimizers
import Adam
import osThe most significant new addition to the list is gym, the Open AI Gym itself. As usual, we discuss each dependency in more detail as we apply it. The hyperparameters that we set at the top of the notebook are provided in Example 13.1.
Example 13.1 Cart-Pole DQN hyperparameters
env = gym.make("CartPole-v0")
state_size = env.observation_space.shape[0]action_size = env.action_space.n
batch_size = 32
n_episodes = 1000
output_dir = "model_output/cartpole/"
if not os.path.exists(output_dir):
os.makedirs(output_dir)Let’s look at this code line by line:
- We use the Open AI Gym
make()method to specify the particular environment that we’d like our agent to interact with. The environment we choose is version zero (v0) of the Cart-Pole game, and we assign it to the variableenv. On your own time, you’re welcome to select an alternative Open AI Gym environment, such as one of those presented in Figure 4.13.
From the environment, we extract two parameters:
state_size: the number of types of state information, which for the Cart-
Pole game is 4 (recall that these are cart position, cart velocity, pole angle, and pole angular velocity).action_size: the number of possible actions, which for Cart-Pole is 2 (left and right).- We set our mini-batch size for training our neural net to
32. - We set the number of episodes (rounds of the game) to 1000. As you’ll soon see, this is about the right number of episodes it will take for our agent to excel regularly at the Cart-Pole game. For more-complex environments, you’d likely need to increase this hyperparameter so that the agent has more rounds of gameplay to learn in.
- We define a unique directory name (
'model_output/cartpole/') into which we’ll output our neural network’s parameters at regular intervals. If the directory doesn’t yet exist, we useos.makedirs()to make it.
The rather large chunk of code for creating a DQN agent Python class—called DQNAgent—is provided in Example 13.2.
Example 13.2 A deep Q-learning agent
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_decay = 0.995
self.epsilon_min = 0.01
self.learning_rate = 0.001
self.model = self._build_model()
def _build_model(self):
model = Sequential()
model.add(Dense(32, activation="relu",
input_dim=self.state_size))
model.add(Dense(32, activation="relu"))
model.add(Dense(self.action_size, activation="linear"))
model.compile(loss="mse",
optimizer=Adam(lr=self.learning_rate))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action,
reward, next_state, done))
def train(self, batch_size):
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward # if done
if not done:
target = (reward +
self.gamma *
np.amax(self.model.predict(next_state)[0]))
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def save(self, name):
self.model.save_weights(name)Initialization Parameters
We begin Example 13.2 by initializing the class with a number of parameters:
state_sizeandaction_sizeare environment-specific, but in the case of the Cart-Pole game are 4 and 2, respectively, as mentioned earlier.memoryis for storing memories that can subsequentlyreplayed in order to train our DQN’s neural net. The memories are stored as elements of a data structure called adeque (pronounced “deck”), which is the same as a list except that—because we specified maxlen=2000—it only retains the 2,000 most recent memories. That is, whenever we attempt to append a 2,001st element onto the deque, its first element is removed, always leaving us with a list that contains no more than 2,000 elements.gammais the discount factor (a.k.a. decay rate) γ that we introduced earlier in this chapter (see Figure 13.4). This agent hyperparameter discounts prospective rewards in future timesteps. Effective γ values typically approach 1 (for example, 0.9, 0.95, 0.98, and 0.99). The closer to 1, the less we’re discounting future reward. [Note: Indeed, if you were to set γ = 1 (which we don’t recommend) you wouldn’t be discounting future reward at all.] Tuning the hyperparameters of reinforcement learning models such as γ can be a fiddly process; near the end of this chapter, we discuss a tool called SLM Lab for carrying it out effectively.epsilon—symbolized by the Greek letter ε—is another reinforcement learning hyperparameter called exploration rate. It represents the proportion of our agent’s actions that are random (enabling it to explore the impact of such actions on the next state st+1 and the reward r returned by the environment) relative to how often we allow its actions to exploit the existing “knowledge” its neural net has accumulated through gameplay. Prior to having played any episodes, agents have no gameplay experience to exploit, so it is the most common practice to start it off exploring 100 percent of the time; this is why we setepsilon = 1.0.- As the agent gains gameplay experience, we very slowly decay its exploration rate so that it can gradually exploit the information it has learned (hopefully enabling it to attain more reward, as illustrated in Figure 13.7). That is, at the end of each episode the agent plays, we multiply its ε by
epsilon_decay. Common options for this hyperparameter are 0.990, 0.995, and 0.999. [Note: Analogous to setting γ = 1, settingepsilon_decay= 1 would mean ε would not be decayed at all—that is, exploring at a continuous rate. This would be an unusual choice for this hyperparameter.] epsilon_minis a floor (a minimum) on how low the exploration rate ε can decay to. This hyperparameter is typically set to a near-zero value such as 0.001, 0.01, or 0.02. We set it equal to 0.01, meaning that after ε has decayed to 0.01 (as it will in our case by the 911th episode), our agent will explore on only 1 percent of the actions it takes—exploiting its gameplay experience the other 99 percent of the time. [Note: If at this stage this exploration rate concept is somewhat unclear, it should become clearer as we examine our agent’s episode-by-episode results later on.]learning_rateis the same stochastic gradient descent hyperparameter that we covered in Chapter 8.- Finally,
_build_model()—by the inclusion of its leading underscore—is being suggested as a private method. This means that this method is recommended for use “internally” only—that is, solely by instances of the classDQNAgent.
Building the Agent’s Neural Network Model
The _build_model() method of Example 13.2 is dedicated to constructing and compiling a Keras-specified neural network that maps an environment’s state s to the agent’s Q-value for each available action a. Once trained via gameplay, the agent will then be able to use the predicted Q-values to select the particular action it should take, given a particular environmental state it encounters. Within the method, there is nothing you haven’t seen before in this book:
- We specify a sequential model.
- We add to the model the following layers of neurons.
- The first hidden layer is dense, consisting of 32 ReLU neurons. Using the
input_dimargument, we specify the shape of the network’s input layer, which is the dimensionality of the environment’s state information s. In the case of the Cart-Pole environment, this value is an array of length 4, with one element each for cart position, cart velocity, pole angle, and pole angular velocity. [Note: In environments other than Cart-Pole, the state information might be much more complex. For example, with an Atari video game environment like Pac-Man, state s would consist of pixels on a screen, which would be a two- or three-dimensional input (for monochromatic or full-color, respectively). In a case such as this, a better choice of first hidden layer would be a convolutional layer such asConv2D(see Chapter 10).] - The second hidden layer is also dense, with 32 ReLU neurons. As mentioned earlier, we’ll explore hyperparameter selection—including how we home in on a particular model architecture—by discussing the SLM Lab tool later on in this chapter.
- The output layer has dimensionality corresponding to the number of possible actions. [Note: Any previous models in this book with only two outcomes (as in Chapters 11 and 12) used a single sigmoid neuron. Here, we specify separate neurons for each of the outcomes, because we would like our code to generalize beyond the Cart-Pole game. While Cart-Pole has only two actions, many environments have more than two.] In the case of the Cart-Pole game, this is an array of length 2, with one element for left and the other for right. As with a regression model (see Example 9.8), with DQNs the z values are output directly from the neural net instead of being converted into a probability between 0 and 1. To do this, we specify the
linearactivation function instead of the sigmoid or softmax functions that have otherwise dominated this book.
- As indicated when we compiled our regression model (Example 9.9), mean squared error is an appropriate choice of cost function when we use linear activation in the output layer, so we set the
compile()method’s loss argument tomse. We return to our routine optimizer choice,Adam.
Remembering Gameplay
At any given timestep t—that is, during any given iteration of the reinforcement learning loop (refer back to Figure 13.3)—the DQN agent’s remember() method is run in order to append a memory to the end of its memory deque. Each memory in this deque consists of five pieces of information about timestep t:
- The state st that the agent encountered
- The action at that the agent took
- The reward rt that the environment returned to the agent
- The next_state st+1 that the environment also returned to the agent
- A Boolean flag done that is true if timestep t was the final iteration of the episode, and
falseotherwise
Training via Memory Replay
The DQN agent’s neural net model is trained by replaying memories of gameplay, as shown within the train() method of Example 13.2. The process begins by randomly sampling a minibatch of 32 (as per the agent’s batch_size parameter) memories from the memory deque (which holds up to 2,000 memories). Sampling a small subset of memories from a much larger set of the agent’s experiences makes model-training more efficient: If we were instead to use, say, the 32 most recent memories to train our model, many of the states across those memories would be very similar. To illustrate this point, consider a timestep t where the cart is at some particular location and the pole is near vertical. The adjacent timesteps (e.g., t − 1, t + 1, t + 2) are also likely to be at nearly the same location with the pole in a near-vertical orientation. By sampling from across a broad range of memories instead of temporally proximal ones, the model will be provided with a richer cornucopia of experiences to learn from during each round of training.
For each of the 32 sampled memories, we carry out a round of model training as follows: If done is True—that is, if the memory was of the final timestep of an episode— then we know definitively that the highest possible reward that could be attained from this timestep is equal to the reward rt. Thus, we can just set our target reward equal to reward.
Otherwise (i.e., if done is False) then we try to estimate what the target reward— the maximum discounted future reward—might be. We perform this estimation by starting with the known reward rt and adding to it the discounted [Note: That is, multiplied by gamma, the discount factor γ.] maximum future Q-value. Possible future Q-values are estimated by passing the next (i.e., future) state st+1 into the model’s predict() method. Doing this in the context of the Cart-Pole game returns two outputs: one output for the action left and the other for the action right. Whichever of these two outputs is higher (as determined by the NumPy amax function) is the maximum predicted future Q-value.
Whether target is known definitively (because the timestep was the final one in an episode) or it’s estimated using the maximum future Q-value calculation, we continue onward within the train() method’s for loop:
- We run the
predict()method again, passing in the current state st. As before, in the context of the Cart-Pole game this returns two outputs: one for the left action and one for the right. We store these two outputs in the variabletarget_f. - Whichever action at the agent actually took in this memory, we use
target_f[0][action] = targetto replace thattarget_foutput with the target reward. [Note: We do this because we can only train the Q-value estimate based on actions that were actually taken by the agent: We estimated target based onnext_statest+1 and we only know what st+1 was for theactionat that was actually taken by the agent at timestep t. We don’t know what next state st+1 the environment might have returned had the agent taken a different action than it actually took.]
We train our model by calling the fit() method.
- The model input is the current state st and its output is
target_f, which incorporates our approximation of the maximum future discounted reward. By tuning the model’s parameters (represented by θ in Equation 13.2), we thus improve its capacity to accurately predict the action that is more likely to be associated with maximizing future reward in any given state. - In many reinforcement learning problems,
epochscan be set to1. Instead of recycling an existing training dataset multiple times, we can cheaply engage in more episodes of the Cart-Pole game (for example) to generate as many fresh training data as we fancy. - We set
verbose=0because we don’t need any model-fitting outputs at this stage to monitor the progress of model training. As we demonstrate shortly, we’ll instead monitor agent performance on an episode-by-episode basis.
Selecting an Action to Take
To select a particular action at to take at a given timestep t, we use the agent’s act() method. Within this method, the NumPy rand function is used to sample a random value between 0 and 1 that we’ll call v. In conjunction with our agent’s epsilon, epsilon_decay, and epsilon_min hyperparameters, this v value will determine for us whether the agent takes an exploratory action or an exploitative one:
- If the random value v is less than or equal to the exploration rate ε, then a random exploratory action is selected using the
randrangefunction. In early episodes, when ε is high, most of the actions will be exploratory. In later episodes, as ε decays further and further (according to the epsilon_decay hyperparameter), the agent will take fewer and fewer exploratory actions. - Otherwise—that is, if the random value v is greater than ε—the agent selects an action that exploits the “knowledge” the model has learned via memory replay. To exploit this knowledge, the
statest is passed in to the model’spredict()method, which returns an activation output for each of the possible actions the agent could theoretically take. We use the NumPyargmaxfunction to select the action at associated with the largest activation output. [Note: Recall that the activation is linear, and thus the output is not a probability; instead, it is the discounted future reward for that action.]
{Note: We introduced the exploratory and exploitative modes of action when discussing the initialization parameters for our DQNAgent class earlier, and they’re illustrated playfully in Figure 13.7.]
Saving and Loading Model Parameters
Finally, the save() and load() methods are one-liners that enable us to save and load the parameters of the model. Particularly with respect to complex environments, agent performance can be flaky: For long stretches, the agent may perform very well in a given environment, and then later appear to lose its capabilities entirely. Because of this flakiness, it’s wise to save our model parameters at regular intervals. Then, if the agent’s performance drops off in later episodes, the higher-performing parameters from some earlier episode can be loaded back up.
Interacting with an OpenAI Gym Environment
Having created our DQN agent class, we can initialize an instance of the class—which we name agent—with this line of code:
agent = DQNAgent(state_size, action_size)The code in Example 13.3 enables our agent to interact with an OpenAI Gym environment, which in our particular case is the Cart-Pole game.
Example 13.3 DQN agent interacting with an OpenAI Gym environmentfor e in range(n_episodes):
state = env.reset()
state = np.reshape(state, [1, state_size])
done = False
time = 0
while not done:
#env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
reward = reward if not done else -10
next_state = np.reshape(next_state, [1, state_size])
agent.remember(state, action, reward, next_state, done)
state = next_state
if done:
print("episode: {}/{}, score: {}, e: {:.2}"
.format(e, n_episodes-1, time, agent.epsilon))
time += 1
if len(agent.memory) > batch_size:
agent.train(batch_size)
if e % 50 == 0:
agent.save(output_dir + "weights_"
+ "{:04d}".format(e) + ".hdf5")Recalling that we had set the hyperparameter n_episodes to 1000, Example 13.3 consists of a big for loop that allows our agent to engage in these 1,000 rounds of game- play. Each episode of gameplay is counted by the variable e and involves:
- We use
env.reset()to begin the episode with a randomstatest. For the purposes of passing state into our Keras neural network in the orientation the model is expecting, we usereshapeto convert it from a column into a row. [Note: We previously performed this transposition for the same reason back in Example 9.11.] - The
env.render()line is commented out because if you are running this code via a Jupyter notebook within a Docker container, this line will cause an error. If, however, you happen to be running the code via some other means (e.g., in a Jupyter notebook without using Docker) then you can try uncommenting this line. If an error isn’t thrown, then a pop-up window should appear that renders the environment graphically. This enables you to watch your DQN agent as it plays the Cart-Pole game in real time, episode by episode. It’s fun to watch, but it’s by no means essential: It certainly has no impact on how the agent learns! - We pass the
statest into the agent’act()method, and this returns the agent’sactionat, which is either 0 (representing left) or 1 (right). - The action at is provided to the environment’s
step()method, which returns the next_state st+1, the current reward rt, and an update to the Boolean flag done. - If the episode is done (i.e., done equals true), then we set reward to a negative value (-10). This provides a strong disincentive to the agent to end an episode early by losing control of balancing the pole or navigating off the screen. If the episode is not done (i.e.,
doneisFalse), thenrewardis+1for each additional timestep of gameplay.Nested within our thousand-episode loop is awhileloop that iterates over the timesteps of a given episode. Until the episode ends (i.e., untildoneequalsTrue), in each timestep t (represented by the variable time), we do the following. - In the same way that we needed to reorient
stateto be a row at the start of the episode, we use reshape to reorientnext_stateto a row here.
- We use our agent’s
remember()method to save all the aspects of this timestep (thestatest, the action at that was taken, the reward rt, the nextstatest+1, and the flag done) to memory.
We setstateequal tonext_statein preparation for the next iteration of the loop, which will be timestep t + 1. - If the episode ends, then we print summary metrics on the episode (see Figures 13.8 and 13.9 for example outputs).
- Add 1 to our timestep counter
time. - If the use the agent’s
train()method to train its neural net parameters by replaying its memories of gameplay.[Note: You can optionally move this training step up so that it’s inside the while loop. Each episode will take a lot longer because you’ll be training the agent much more often, but your agent will tend to solve the Cart-Pole game in far fewer episodes.] - Every 50 episodes, we use the agent’s
save()method to store the neural net model’s parameters.
As shown in Figure 13.8, during our agent’s first 10 episodes of the Cart-Pole game, the scores were low. It didn’t manage to keep the game going for more than 42 timesteps (i.e., a score of 41).

During these initial episodes, the exploration rate ε began at 100 percent. By the 10th episode, ε had decayed to 96 percent, meaning that the agent was in exploitative mode (refer back to Figure 13.7) on about 4 percent of timesteps. At this early stage of training, however, most of these exploitative actions would probably have been effectively random anyway.
As shown in Figure 13.9, by the 991st episode our agent had mastered the Cart-Pole game.
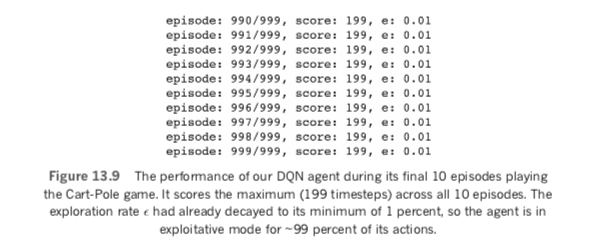
It attained a perfect score of 199 in all of the final 10 episodes by keeping the game going for 200 timesteps in each one. By the 911th episode,28 the exploration rate ε had reached its minimum of 1 percent so during all of these final episodes the agent is in exploitative mode in about 99 percent of timesteps. From the perfect performance in these final episodes, it’s clear that these exploitative actions were guided by a neural net well trained by its gameplay experience from previous episodes.
As mentioned earlier in this chapter, deep reinforcement learning agents often dis- play finicky behavior. When you train your DQN agent to play the Cart-Pole game, you might find that it performs very well during some later episodes (attaining many consecutive 200-timestep episodes around, say, the 850th or 900th episode) but then it performs poorly around the final (1,000th) episode. If this ends up being the case, you can use the load() method to restore model parameters from an earlier, higher-performing phase.
Hyperparameter Optimization with SLM Lab
At a number of points in this chapter, in one breath we’d introduce a hyperparameter and then in the next breath we’d indicate that we’d later introduce a tool called SLM Lab for tuning that hyperparameter. Well, that moment has arrived! [Note: “SLM” is an abbreviation of strange loop machine, with the strange loop concept being related to ideas about the experience of human consciousness. See Hofstadter, R. (1979). Gödel, Escher, Bach. New York: Basic Books.]
SLM Lab is a deep reinforcement learning framework developed by Wah Loon Keng and Laura Graesser, who are California-based software engineers (at the mobile-gaming firm MZ and within the Google Brain team, respectively). The framework is available in this repo and has a broad range of implementations and functionality related to deep reinforcement learning:
- It enables the use of many types of deep reinforcement learning agents, including DQN and others (forthcoming in this chapter).
- It provides modular agent components, allowing you to dream up your own novel categories of deep RL agents.
- You can straightforwardly drop agents into environments from a number of differ- ent environment libraries, such as OpenAI Gym and Unity (see Chapter 4).
- Agents can be trained in multiple environments simultaneously. For example, a single DQN agent can at the same time solve the OpenAI Gym Cart-Pole game and the Unity ball-balancing game Ball2D.
- You can benchmark your agent’s performance in a given environment against others’ efforts.
Critically, for our purposes, the SLM Lab also provides a painless way to experiment with various agent hyperparameters to assess their impact on an agent’s performance in a given environment. Consider, for example, the experiment graph shown in Figure 13.10. In this particular experiment, a DQN agent was trained to play the Cart-Pole game during a number of distinct trials. Each trial is an instance of an agent with particular, distinct hyperparameters trained for many episodes. Some of the hyperparameters varied between trials were as follows.
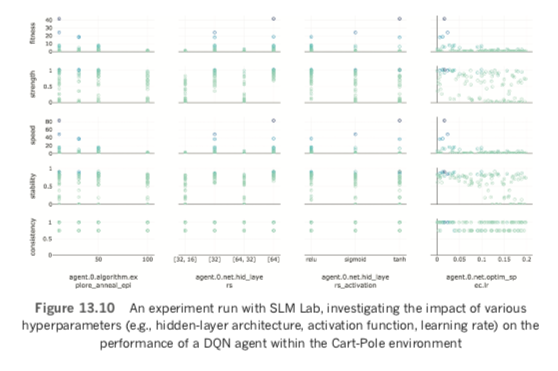
- Dense net model architecture
- [32]: a single hidden layer, with 32 neurons
- [64]: also a single hidden layer, this time with 64 neurons
- [32, 16]: two hidden layers; the first with 32 neurons and the second with 16
- [64, 32]: also with two hidden layers, this time with 64 neurons in the first hidden layer and 32 in the second
- Activation function across all hidden layers
- Sigmoid
- Tanh
- ReLU
- Optimizer learning rate (η), which ranged from zero up to 0.2
- Exploration rate (ε) annealing, which ranged from 0 to 100 [Note: Annealing is an alternative to ε decay that serves the same purpose. With the epsilon and epsilon_min hyper- parameters set to fixed values (say, 1.0 and 0.01, respectively), variations in annealing will adjust epsilon_decay such that an ε of 0.01 will be reached by a specified episode. If, for example, annealing is set to 25 then ε will decay at a rate such that it lowers uniformly from 1.0 in the first episode to 0.01 after 25 episodes. If annealing is set to 50 then ε will decay at a rate such that it lowers uniformly from 1.0 in the first episode to 0.01 after 50 episodes.]
SLM Lab provides a number of metrics for evaluating model performance (some of which can be seen along the vertical axis of Figure 13.10):
- Strength: This is a measure of the cumulative reward attained by the agent.
- Speed: This is how quickly (i.e., over how many episodes) the agent was able to
reach its strength. - Stability: After the agent solved how to perform well in the environment, this is a measure of how well it retained its solution over subsequent episodes.
- Consistency: This is a metric of how reproducible the performance of the agent was across trials that had identical hyperparameter settings.
Fitness: An overall summary metric that takes into account the above four
metrics simultaneously. Using the fitness metric in the experiment captured by Figure 13.10, it appears that the following hyperparameter settings are optimal for this DQN agent playing the Cart-Pole game:
- A single-hidden-layer neural net architecture, with 64 neurons in that single layer outperforming the 32-neuron model.
- The tanh activation function for the hidden layer neurons.
- A low learning rate (η) of ~0.02.
- Trials with an exploration rate (ε) that anneals over 10 episodes outperform trials that anneal over 50 or 100 episodes.
Details of running SLM Lab are beyond the scope of our book, but the library is well documented at https://github.com/kengz/SLM-Lab.
Agents Beyond DQN
In the world of deep reinforcement learning, deep Q-learning networks like the one we built in this chapter are relatively simple. To their credit, not only are DQNs (comparatively) simple, but—relative to many other deep RL agents—they also make efficient use of the training samples that are available to them. That said, DQN agents do have drawbacks. Most notable are:
- If the possible number of state-action pairs is large in a given environment, then the Q-function can become extremely complicated, and so it becomes intractable to estimate the optimal Q-value, Q∗.
- Even in situations where finding Q∗ is computationally tractable, DQNs are not great at exploring relative to some other approaches, and so a DQN may not con- verge on Q∗ anyway.
Thus, even though DQNs are sample efficient, they aren’t applicable to solving all problems.
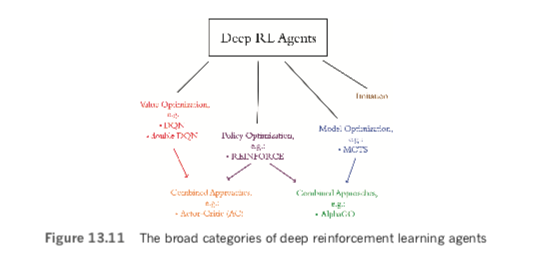
To wrap up this deep reinforcement learning chapter, let’s briefly introduce the types of agents beyond DQNs. The main categories of deep RL agents, as shown in Figure 13.11, are:
- Value optimization: These include DQN agents and their derivatives (e.g., double DQN, dueling QN) as well as other types of agents that solve reinforcement learning problems by optimizing value functions (including Q-value functions).
- Imitation learning: The agents in this category (e.g., behavioral cloning and conditional imitation learning algorithms) are designed to mimic behaviors that are taught to them through demonstration, by—for example—showing them how to place dinner plates on a dish rack or how to pour water into a cup. Although imitation learning is a fascinating approach, its range of applications is relatively small and we don’t discuss it further in this book.
- Model optimization: Agents in this category learn to predict future states based on (s, a) at a given timestep. An example of one such algorithm is Monte Carlo tree search (MCTS), which we introduced with respect to AlphaGo in Chapter 4.
- Policy optimization: Agents in this category learn policies directly, that is, they directly learn the policy function π shown in Figure 13.5. We’ll cover these in further detail in the next section.
Policy Gradients and the REINFORCE Algorithm
Recall from Figure 13.5 that the purpose of a reinforcement learning agent is to learn some policy function π that maps the state space S to the action space A. With DQNs, and indeed with any other value optimization agent, π is learned indirectly by estimating a value function such as the optimal Q-value, Q∗. With policy optimization agents, π is learned directly instead.
Policy gradient (PG) algorithms, which can perform gradient ascent32 on π directly, are exemplified by a particularly well-known reinforcement learning algorithm called REINFORCE.33 The advantage of PG algorithms like REINFORCE is that they are likely to converge on a fairly optimal solution,34 so they’re more widely applicable than value optimization algorithms like DQN. The trade-off is that PGs have low consistency. That is, they have higher variance in their performance relative to value optimization approaches like DQN, and so PGs tend to require a larger number of training samples.
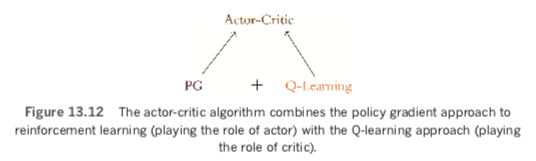
The Actor-Critic Algorithm
As suggested by Figure 13.11, the actor-critic algorithm is an RL agent that combines the value optimization and policy optimization approaches. More specifically, as depicted in Figure 13.12, the actor-critic combines the Q-learning and PG algorithms. At a high level, the resulting algorithm involves a loop that alternates between:
- Actor: a PG algorithm that decides on an action to take.
- Critic: a Q-learning algorithm that critiques the action that the actor selected, providing feedback on how to adjust. It can take advantage of efficiency tricks in Q-learning, such as memory replay.
In a broad sense, the actor-critic algorithm is reminiscent of the generative adver- sarial networks of Chapter 12. GANs have a generator network in a loop with a discriminator network, with the former creating fake images that are evaluated by the latter. The actor-critic algorithm has an actor in a loop with a critic, with the former taking actions that are evaluated by the latter.
The advantage of the actor-critic algorithm is that it can solve a broader range of prob- lems than DQN, while it has lower variance in performance relative to REINFORCE. That said, because of the presence of the PG algorithm within it, the actor-critic is still somewhat sample inefficient.
While implementing REINFORCE and the actor-critic algorithm are beyond the scope of this book, you can use SLM Lab to apply them yourself, as well as to examine their underlying code.
Summary
In this chapter, we covered the essential theory of reinforcement learning, including Markov decision processes. We leveraged that information to build a deep Q-learning agent that solved the Cart-Pole environment. To wrap up, we introduced deep RL algorithms beyond DQN such as REINFORCE and actor-critic. We also described SLM Lab—a deep RL framework with existing algorithm implementations as well as tools for optimizing agent hyperparameters.
This chapter brings an end to Part III of this book, which provided hands-on applications of machine vision (Chapter 10), natural language processing (Chapter 11), art-generating models (Chapter 12), and sequential decision-making agents. In Part IV, the final part of the book, we will provide you with loose guidance on adapting these applications to your own projects and inclinations.

Summary
- Introduction
- Deep Reinforcement Learning
- Essential Theory of Reinforcement Learning
- The Cart-Pole Game
- Markov Decision Processes
- The Optimal Policy
- Essential Theory of Deep Q-Learning Networks
- Value Functions
- Q-Value Functions
- Estimating an Optimal Q-Value
- Defining a DQN Agent
- Initialization Parameters
- Building the Agent’s Neural Network Model
- Remembering Gameplay
- Training via Memory Replay
- Selecting an Action to Take
- Saving and Loading Model Parameters
- Interacting with an OpenAI Gym Environment
- Hyperparameter Optimization with SLM Lab
- Agents Beyond DQN
- Policy Gradients and the REINFORCE Algorithm
- The Actor-Critic Algorithm
- Summary



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.