
Crunchbase recently converted its backend database to a Neo4j graph database. This will give it great flexibility in the future, but for now, the data is exposed similarly to how it always has been: individual entities are retrieved and attribute data must be used to form edges between them prior to any graph analysis. Aside from traversing links manually on the web pages, there are no provisions for graph analysis.
To enable more powerful manipulations of this data, during my time at Zipfian Academy, I created my "Visibly Connected" project. "Visibly Connected" facilitates the construction and network analysis of Crunchbase data and additionally provides data ready to use in NetworkX or Gephi.
Below, I present an analysis of acquisitions represented in the Crunchbase data, along with a description of the techniques I used. Technical details on the software itself are documented in the public project.
Available Data
The entire Crunchbase data representing companies, financial organizations, and people are stored in the project. Most people will want to access the data using the NetworkX gpickle files for each node type. GraphML files are also available for direct import to Gephi.
The data provided contains over 24,000 financial organizations, 200,000 people, and 200,000 companies. Of these, only 9861 companies were involved with acquisitions.
Building the Graph
Visibly Connected is written in Python and relies on the NetworkX library for network storage and graph analyses. Building the graph is easiest using the GraphBuilder class, a super class of NetworkX's directed graph. Instantiating the graph object and reading nodes is relatively easy as shown in the snippet below. The complete program is found in src/graph/build_acquisition_digraph.py. The full program contains a few techniques to trim the unnecessary data from the graph.
COMPANIES_COMPLETE = r'./data/company_complete.pkl'x = gb.GraphBuilder()x.read_gpickle(COMPANIES_COMPLETE)The relationships, or edges, are built using the attribute data of each node. You provide the node type and a list of relationships. Relationships are limited to those defined in Crunchbase and currently additionally limited to acquisition (being acquired), acquisitions (acquiring others), and Investments (provided funding to a company). Keep in mind one significant bias of open source data: if someone doesn't want the information public they can remove it.
.add_relations_from_nodes('company', ['acquisitions', 'acquisition'])
x.summary()Congratulations, you have a network. For most analyses you will want to clean it up a bit. Nodes that don't connect to anything tend to be uninteresting in network analysis (a personal judgment.) Small clusters may or may not be of interest. The lines below remove unconnected nodes, and then subgraphs with fewer than four nodes. Filtering, explained in the technical documents, can be used to keep or remove nodes based on arbitrarily complex conditions.
x.remove_nodes_from(x.isolates())
x.remove_small_components(min_size=4)
x.summary()Finally, if you would like to save or export your graph, it's a one-line affair. The GraphML file format can be read directly into Gephi.The gpickle file can be read using the GraphBuilder class or NetworkX.
ACQUISITIONS_GPICKLE = r'./data/full_acquisitions_digraph.pkl.gz'x.write_gpickle(ACQUISITIONS_GPICKLE)The full_acquisitions_digraph_file and the corresponding GraphML file are available in the project data directory along with some others.
Results for the Acquisitions Graphs
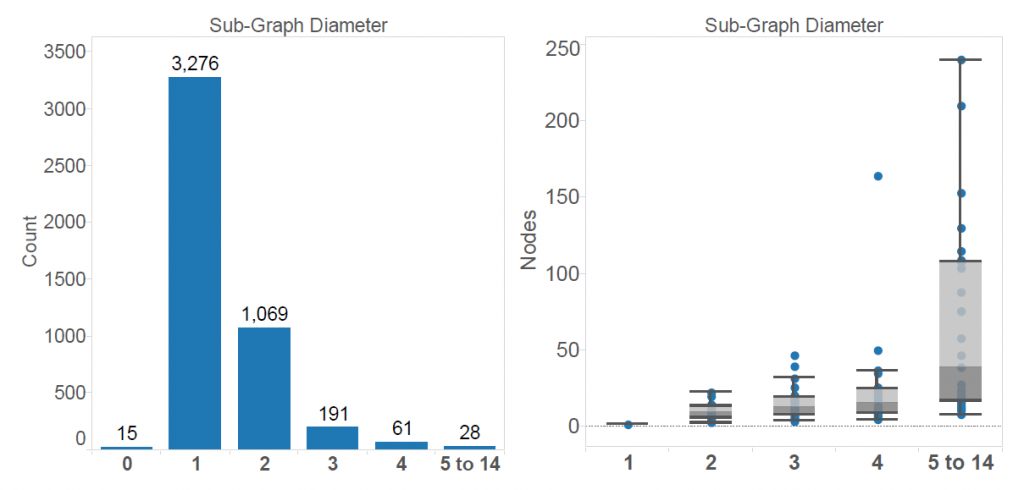
The second half of the python script mentioned above was used to generate several networks and data for the charts. The visualizations were generated in Gephi, although Matplotlib could also be used. In the data provided there are 4,640 subgraphs without connections to each other. They range in size from one to 242 nodes and in diameter from 1 to 14. Diameter is the longest path from any node to any other node in the network. The image below shows the two graph structures accounting for 70% of the acquisition subgraphs.
Yes, that's right: according to the Crunchbase data, no fewer than 15 companies bought themselves leading to one-node 0-diameter graphs. The 3,276 graphs with two nodes represent one company buying exactly one other company. The figure below shows the number of nodes in each subgraph and their relationship to the diameter of the subgraphs.
Obviously, acquisitions involving a few companies are the most common. It gets a little more interesting when companies start gobbling up companies that have been gobbling up other companies. Google and some of its purchases are a good example.
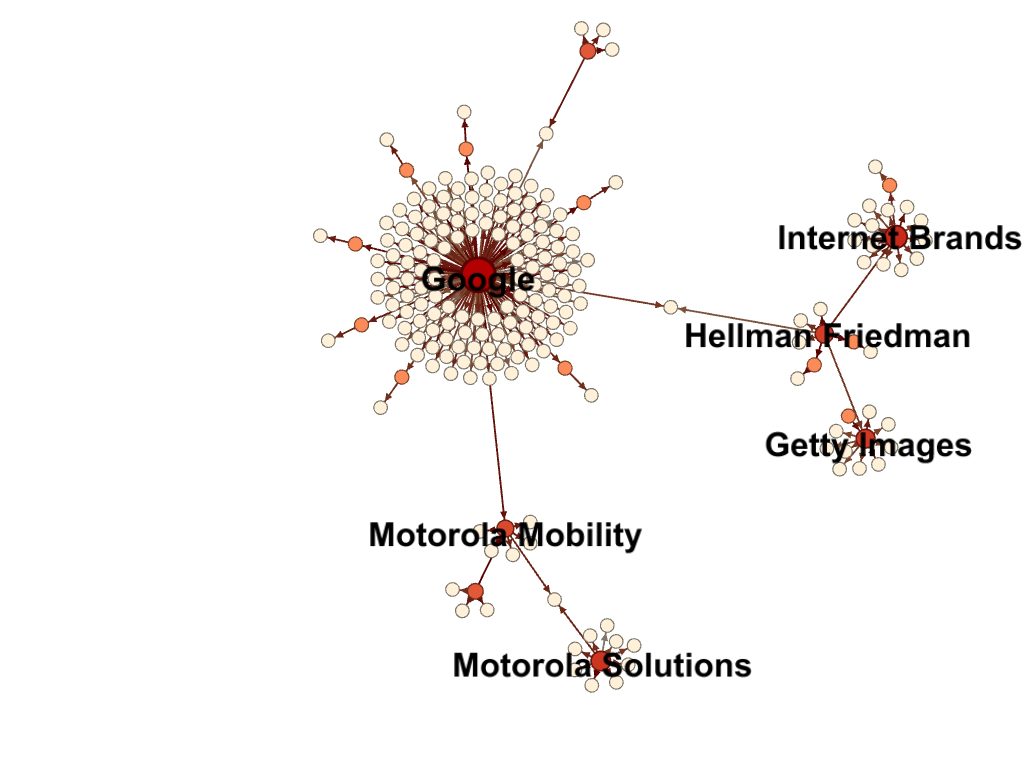
However, this graph is not all companies Google has bought. Note that nodes linking Mobility Solutions and Hellman Friedman to Google indicate they were bought by both companies. They were, just at different times.
The largest acquisition subgraph, of diameter 14, is comprised of two major companies. From a community perspective, they have a single tenuous connection. Want to know? Try out the software.
Discussion
The acquisitions are in my opinion not the most interesting data in Crunchbase. I encourage you to look at the rest of the data and think about taking advantage of various graph-based community measures. There is a lot of fun stuff related to VCs, startup funding, and people shifting from company to company. Two quick ideas:
- Which VCs or Angels get in on the good companies first? Who always follows someone else?
- Which financial organizations are closely tied with one another based on companies funded or funding rounds participated in?
Keep in mind that there are significant biases. The survivorship bias has been written about by Jamie Davidson, and Benn Stancil who has related software on GitHub and has an alternate set of Crunchbase data in more traditional tables.
There are more details on software, data, and files in the project README.md. If you have any questions feel free to contact me.

Casson Stallings is a Principal Data Scientist at Metabolon. Previously, Casson was a Senior Data Science Consultant at Mammoth Data. Casson taught and mentored students and consulted with numerous clients in a variety of fields. He has recently been developing Monte Carlo statistical models, mining large financial datasets for interesting data stories, and building geo-referenced databases for predictive modeling.
Summary
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.