Better Knowledge Management for Data Science Teams
Nick Elprin2016-06-01 | 7 min read
We’re excited to announce a set of big new features that make it easier for you to find and reuse past data science work in your team and organization. We’re calling these features “Discoverability,” and they encompass powerful ways to search, tag, and get recommendations about relevant analytical work.
In this post, we describe how these features work at a high level, along with a deeper dive into the motivation behind them and of the common challenges we think they solve. These features are available in Domino; if you’re interested in seeing them in action, sign up for a live demo.
Background & Motivation: Compounding Research
Anyone who has worked in a team and seen colleagues come and go, or seen projects multiply, knows how frustrating it can be to find past work when there is no standard place to put things, no “system of record.” Should you look in Dropbox? Google Docs? Github? Maybe just search my email or a company wiki page?
This wastes time. A lot of it, in some cases. According to a KMWorld article:
Some studies suggest that 90% of the time that knowledge workers spend in creating new reports or other products is spent in recreating information that already exists. In 1999, a European study by IDC examined that phenomenon, called the "knowledge work deficit," and concluded that the cost of intellectual rework, substandard performance and inability to find knowledge resources was $5,000 per worker per year.
And according to a McKinsey report, "employees spend 1.8 hours every day—9.3 hours per week, on average—searching and gathering information."
The productivity impact of wasted time is one thing — but when your work is critical to your business and competitive advantage, the inability to find and reuse past work causes an even bigger problem: it slows your rate of research improvements.
To illustrate why, we’ll use a concept from finance: compound interest. Compound interest causes an investment to grow exponentially because each additional dollar feeds back into the underlying amount that is growing.
(Source: http://financesolutions.org/about-compound-interest/)
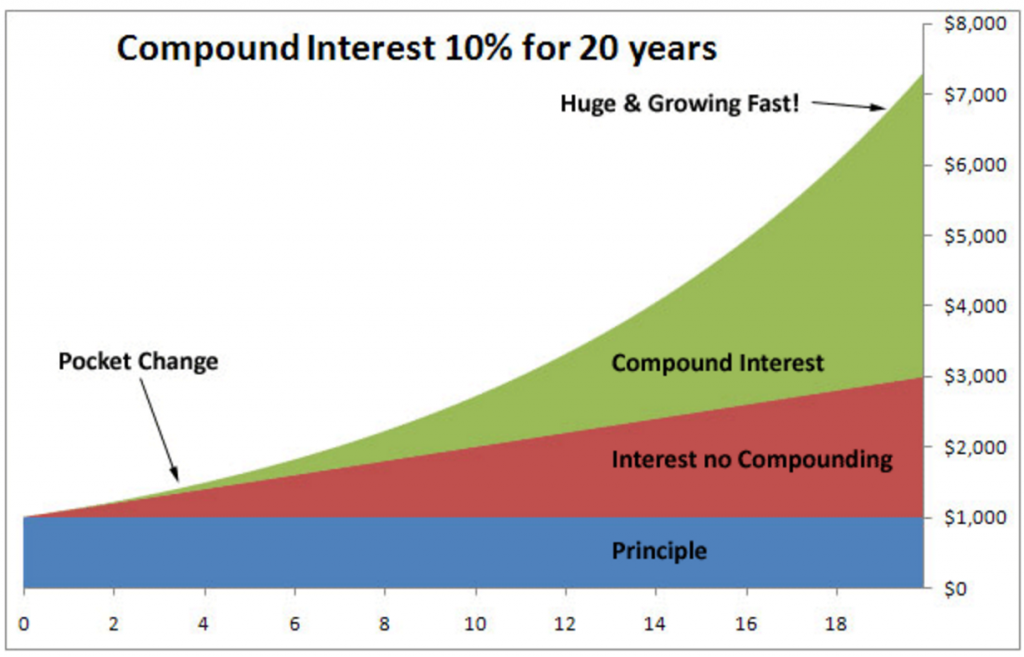
The same concept applies to your analytical work: if each project and work product become part of your company’s collective knowledge, so that colleagues in the future can easily build improve it or build upon it, then you are compounding your knowledge, and improving your models at an exponential rate.
So the question becomes: how do you ensure that your analytical work will be used as the starting point for subsequent improvements, so people don’t start from scratch again?
Searching & Browsing
To enable people to build upon past work, we first need to let them find past work. There are two classical approaches to this: let people organize or curate work; and let people search work. (Think of this as the “Yahoo vs Google” question.) We decided to allow both: Domino lets you tag your projects with a customizable set of tags, and it also lets you search the contents of all projects.
Search
Searching is self-explanatory and surprising powerful. Domino will now index all files in your projects, as well as meta data such as the titles of your experiments, and all comments about your results.
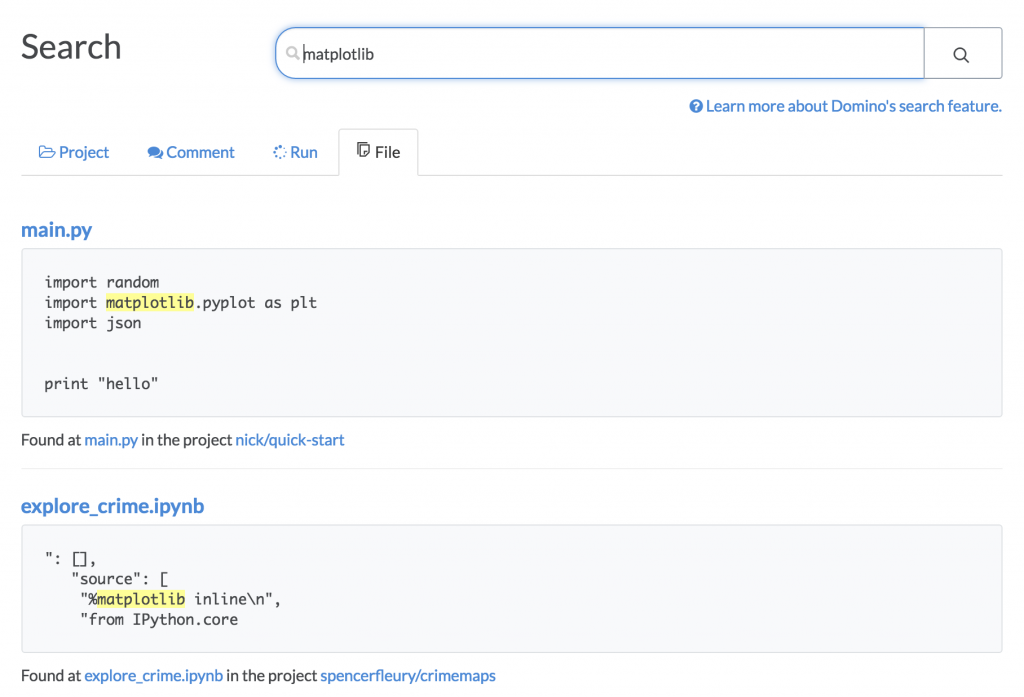
For example, let’s say I wanted to try using the matplotlib Python package, and I wanted to find examples I could copy or borrow from to help me learn:
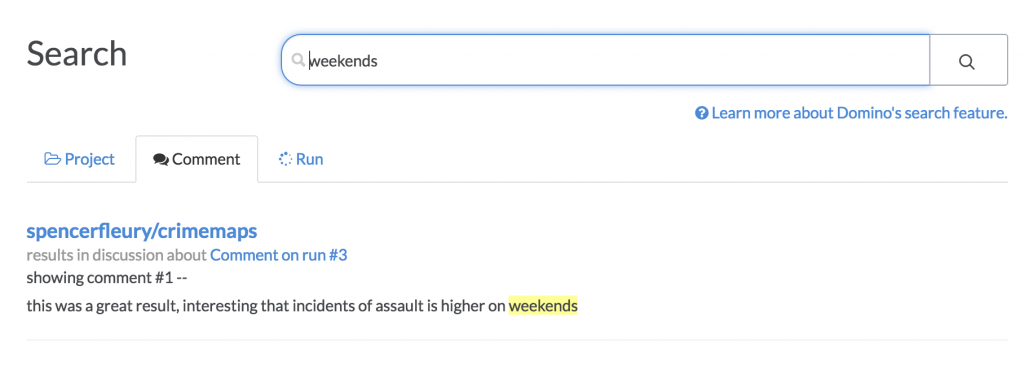
Or if we want to find past analysis involving crime data that related to differences between weekday and weekend incidents of crime, we can search experiments as well as discussion about results:
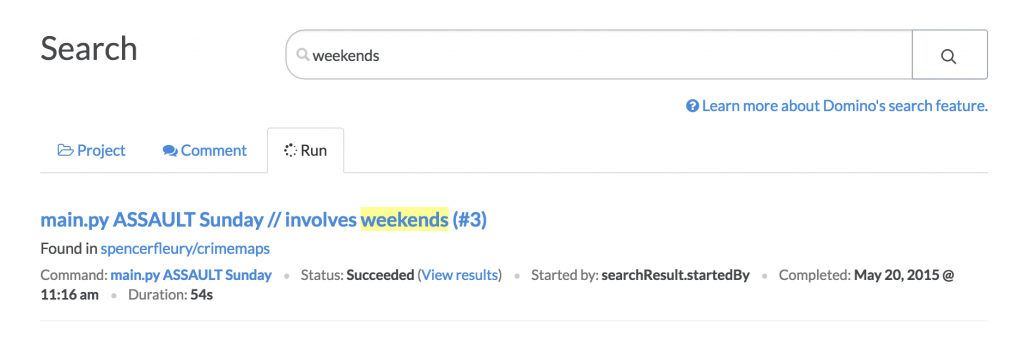
Search respects permissions, of course: you will only see results from projects you are authorized to access. Security (only being able to see what you’re allowed to) stands in natural tension with discoverability (being able to find and reuse relevant work). To let organizations maximize discoverability while enforcing access controls, we offer a way to set projects to be “searchable”, so that someone without access can still find them via a search (and thus know they exist), but will need to request access before being able to see the project contents.
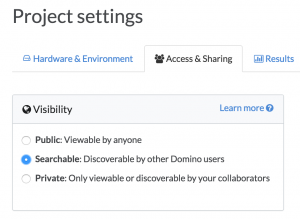
Tagging
Letting users tag things always sounds like a great idea — until you have a big mess on your hands. Tags can quickly become a swamp of unmanaged, redundant, low-quality information.
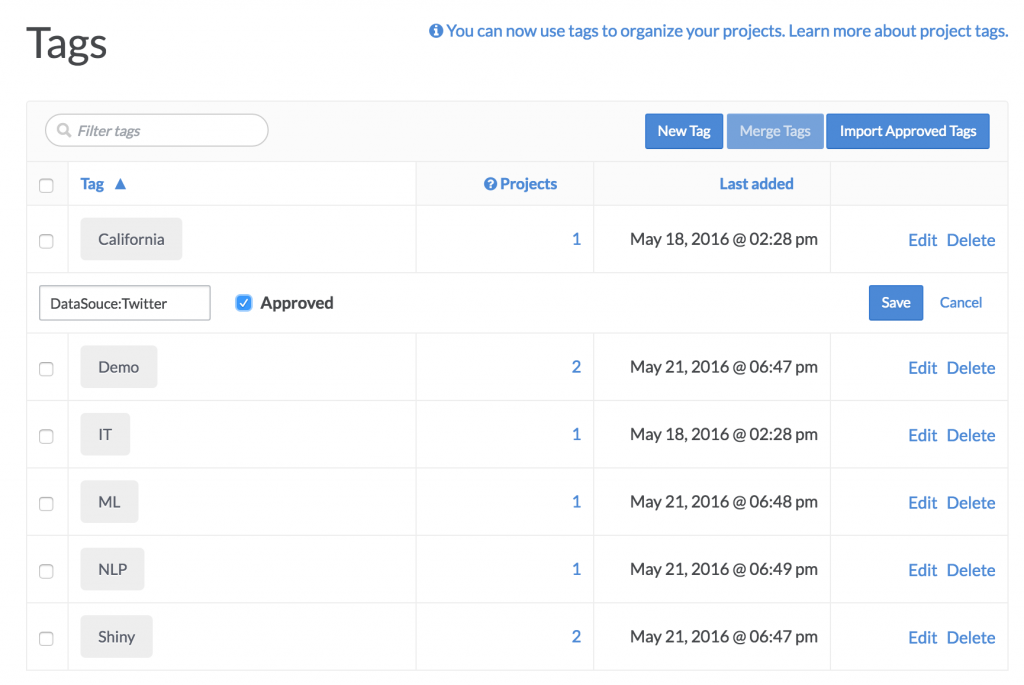
To address this, Domino’s tagging solution supports a “Librarian” or “Curator” role: a special type of administrator that can manage tags and designate certain tags as “blessed”, thereby giving them special status. Here’s how it works:
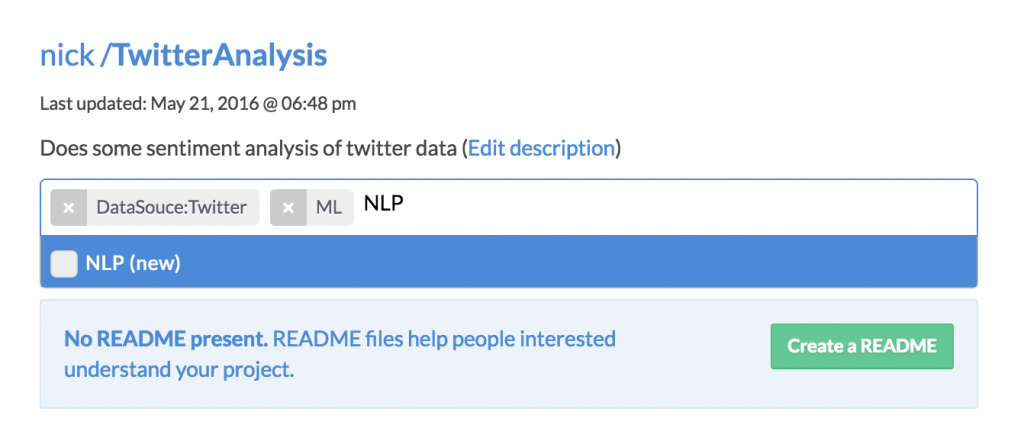
Researchers can tag their projects, just as you’d expect:
Librarians can manage the overall list of tags, merge duplicates, mark key tags as “Approved”, etc.
“Approved” tags show up differently in the UI, to signal to users that they are more trusted. E.g., if you are tagging a project, your auto-completed suggestions will show Approved tags in green:
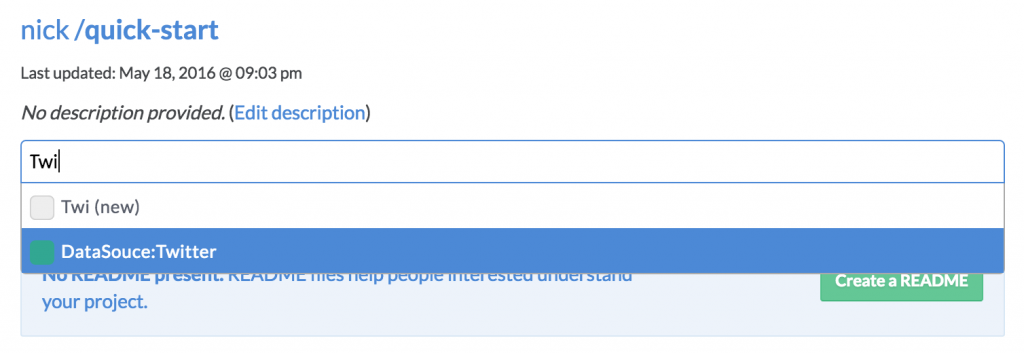
And when you search for a given tag, the Approved tags will render in green again, so you can be more confident in that classification:
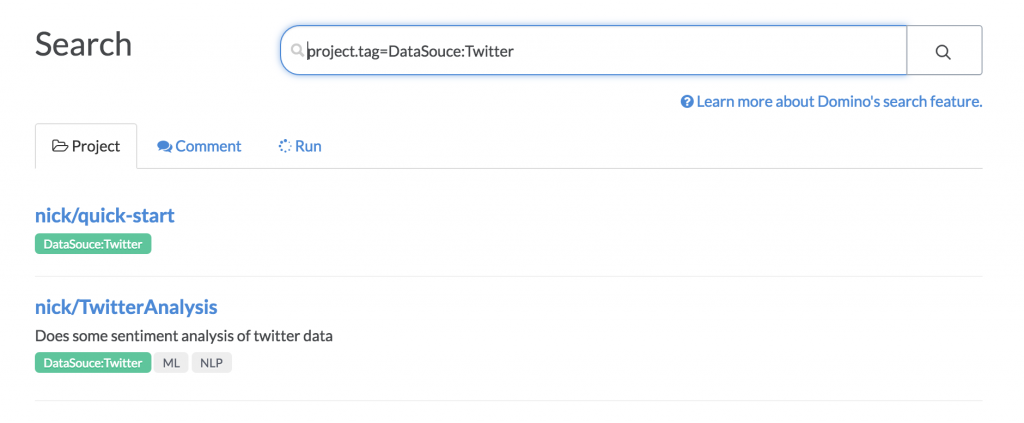
We think this “curation” capability provides the best of both worlds: it allows bottom up concept and hierarchy creation, along with top-down management to ensure that messes don’t get out of hand.
Context & Recommendations
Searching and browsing (by tag or otherwise) is great if you have the idea that you should look for something. Often, however, it won’t even cross one’s mind that there may be relevant work you should build upon.
To address this, the final piece of our Discoverability feature set is a more advanced Project Portal, that will show you not just your own projects, but also projects that may be relevant to what you’re working on. Because we know who you’ve collaborated with, and what topics your projects involve, we can make some basic recommendations about the other work that’s likely to be relevant to you.
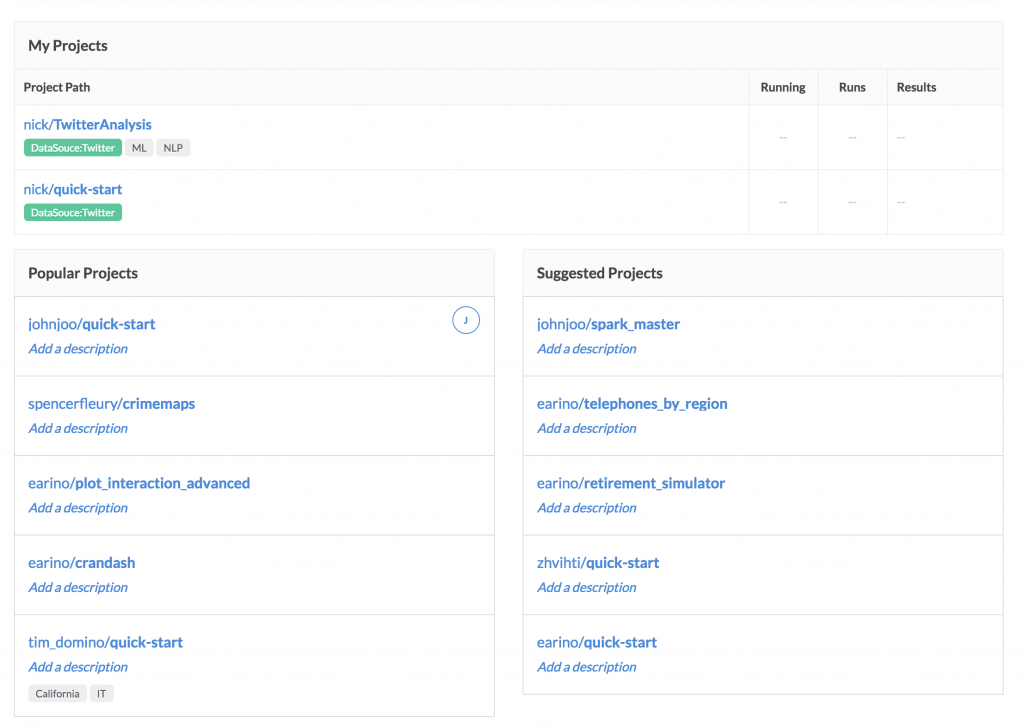
Learn More
We hear more and more organizations wanting to accelerate their pace of model improvement to stay ahead of competitors and drive business improvements faster. As those organizations grow, we believe “compound research” will be a critical to those efforts. To that end, we plan to continue investing in “discoverability” and knowledge management features in Domino
For now, these features are available in the Enterprise version of Domino, which you can use in your own AWS Virtual Private Cloud, or on premise on your own servers. If you’re interested in trying them out, let us know.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.