Answering Questions About Model Delivery on AWS at Strata
Domino Data Lab2017-10-11 | 7 min read

This post is a recap of the common questions Domino answered in the booth at Strata New York. We answered questions about access to EC2 machines, managing environments, and model delivery.
One of the best parts about being at an event like Strata is the chance to spend time with data scientists and data science managers. We heard firsthand about the challenges data scientists have in their day-to-day work, including time spent on DevOp-esque tasks. We heard a lot of data science managers talking about their drive to get more flexibility into their programs, so that data scientists have freedom in choosing tools and running experiments. We heard, from both data scientists and data science managers, how many companies are still figuring out the processes and infrastructure they need for data science to effectively deliver business value. We also heard a lot of companies starting to look at cloud migration as an important part of their long term strategy.
These types of meetings are great because they give us lots of ideas about features to build. Yet, these meetings at Strata were also great because they validate what we’re already shipping. In fact, our recent announcement about Model Delivery on AWS highlights only a few of the advantages of our combined solution with Amazon. Even what we think of as more basic features, including easy access to EC2 machines, environment management, and model delivery, are popular with Domino customers.
Easy Access to EC2 Machines
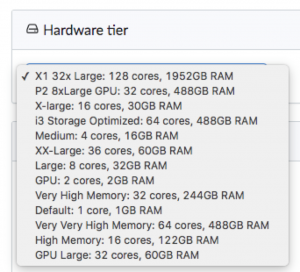
Take scalable compute, for example. Very few people working in data science today have access to compute power the way Domino provides it. Most data scientists are either still working on their personal machine, or stuck with a shared server they can’t control. As simple as the hardware tier selection menu is, it remains one of the most popular features in the demo for working data scientists.
Our partnership with AWS means that Domino customers have fast, easy access to as much compute power as they need to do their work. And of course, we also add in the reporting and IT management features that those supporting the data science team are looking for.
Environment Management and Workspaces
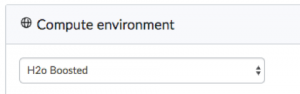
Paired with the compute management, Domino’s environment management also solves problems many companies are having. Because Strata was in New York, we spoke with people from a variety of financial services firms. Regulatory compliance was always an important topic. I asked people from several banks, “how does your model validation team recreate the environment the model was built in?” It turns out, no one had a good answer. It was a documentation challenge, there were restrictions on what tools data scientists could use, or perhaps it just added a lot of extra work.
Domino has this solved. Our customers in regulated industries love the fact that the environment travels with the model, from initial exploration to production. People who saw this appreciated the flexibility they gained in how they could work, combined with the guarantee that any environment they were using would be preserved and available for both internal and external auditors.
The environment management has additional benefit, which is that customers can choose which tools they load into the environment and make available to their team. It’s easy to give everyone access to Jupyter, RStudio, and tools for SQL, Spark, etc. Domino customers are also loading proprietary software like Matlab and SAS into their shared environments. The result is central management for all the tools that data science teams want to use.
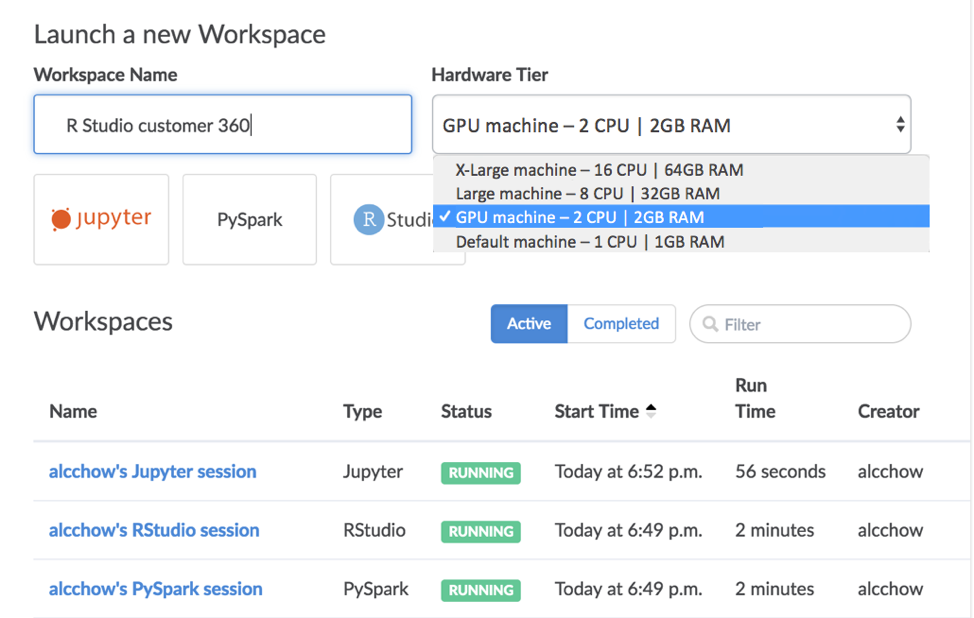
Sneak Peek of Upcoming Workspace within a Single Page View
Model Publishing
Because we just announced the new model delivery capabilities, this area generated a lot of interest. We often hear about the expensive lag between when a model is finished and when it goes into production. The cost isn’t just the DevOps cost, and it isn’t the cost of having an out-of-date model in production. The main cost is the reduction in iterations of models. A company’s ability to learn from deployed models is compromised, and so is the pace of improvement.
With Domino on AWS, the DevOps overhead is eliminated. People get high availability infrastructure, and a controlled process for deploying models at whatever scale they need, from small prototypes to web scale consumer facing applications. Of course, we still have a full model release management process, but without all the unnecessary overhead that costs so much.
There are several aspects of model publishing that people really appreciate. One is the ability to easily test the model in its production environment. Those building models can confirm that the model does exactly what they expect it to. Using Domino means that the model doesn’t need to get re-implemented in a new environment, and rounds of testing are eliminated.
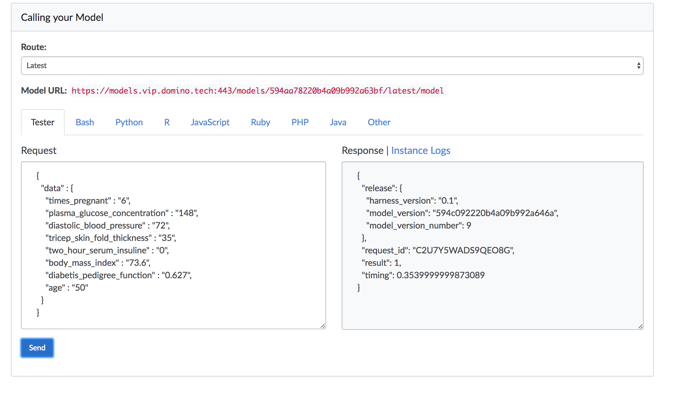
Next, we make it easy to assign resources to support the model in production. Deciding how much compute power should go into supporting a production model is as simple as using a pull down menu.
Finally, we make it easy to track everything about production models: who owns them, when they were built and put into production, when versions changed, etc. Domino’s collaboration features extend to monitoring and managing models so that mission critical predictive models can get the appropriate level of support.
Of course, there’s a lot more to Domino on AWS that our users get excited about. We already wrote about the 128 core X1 Instances we support. (And yes, you can configure who has access to them.) More recently, we covered the value of the G3 GPUs, and if the speed advantage is worth the cost. Distributed teams get faster and more effective with the centralized knowledge and easy ability to see what others are working on. CIOs and IT teams are happy to end shadow IT while still supporting data science work requirements.
If you weren’t able to join us at Strata, and you’re interested in learning more about how our customers are using the platform and moving to the cloud, download our “Data Science in the Cloud” whitepaper.

Domino powers model-driven businesses with its leading Enterprise MLOps platform that accelerates the development and deployment of data science work while increasing collaboration and governance. More than 20 percent of the Fortune 100 count on Domino to help scale data science, turning it into a competitive advantage. Founded in 2013, Domino is backed by Sequoia Capital and other leading investors.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.