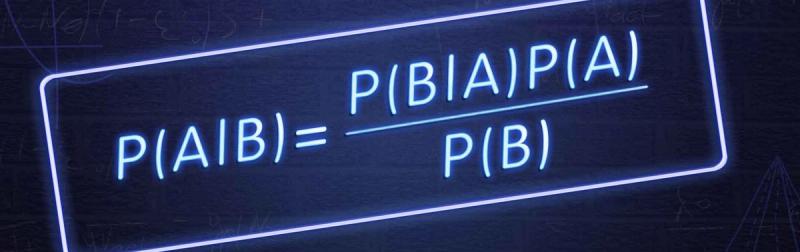
This blog post follows my journey from traditional statistical modeling to Machine Learning (ML) and introduces a new paradigm of ML called Model-Based Machine Learning (Bishop, 2013). Model-Based Machine Learning may be of particular interest to statisticians, engineers, or related professionals looking to implement machine learning in their research or practice.
During my Masters in Transportation Engineering (2011-2013), I used traditional statistical modeling in my research to study transportation-related problems such as highway crashes. When I started my Ph.D., I wanted to explore using machine learning because of the powerful academic and industry use cases I had read about. In particular, I wanted to develop methods that learned how people travel within cities, allowing for better planning of transportation infrastructure.
Challenges in Adopting Machine Learning
I, however, found this shift from traditional statistical modeling to machine learning to be daunting:
- There was a vast amount of literature to read, covering thousands of ML algorithms. There was also a new vocabulary to learn, with terms such as "features", "feature engineering", etc.
- I had to understand which algorithms to use, or why one would be better than another for my urban mobility research projects.
- What if my problem didn't seem to fit with any standard algorithm? Would I have to devise a new algorithm?
The Defining Moment
After having read a swathe of literature and watched several MOOCs on machine learning, I discovered Prof. Daphne Koller's course on Probabilistic Graphical Models (PGMs) on Coursera. This later led me to a textbook by Prof. Christopher Bishop titled "Pattern Recognition and Machine Learning" which I found easy to understand. So naturally, I looked up Bishop's other publications and that's when I found his paper titled "Model-Based Machine Learning". This was a career-defining moment for me: I fell in love with Bayesian Machine Learning. If you enjoy this blog post, you may be interested in a book on this topic (Winn et al., 2015) being written by Bishop and his colleagues at Microsoft Research - Cambridge.
What is Model-Based Machine Learning (MBML)?
The field of machine learning has seen the development of thousands of learning algorithms. Typically, scientists choose from these algorithms to solve specific problems. Their choices often being limited by their familiarity with these algorithms. In this classical/traditional framework of machine learning, scientists are constrained to making some assumptions so as to use an existing algorithm. This is in contrast to the model-based machine learning approach which seeks to create a bespoke solution tailored to each new problem.
The goal of MBML is "to provide a single development framework which supports the creation of a wide range of bespoke models". This framework emerged from an important convergence of three key ideas:
- the adoption of a Bayesian viewpoint,
- the use of factor graphs (a type of a probabilistic graphical model), and
- the application of fast, deterministic, efficient and approximate inference algorithms.
The core idea is that all assumptions about the problem domain are made explicit in the form of a model. In this framework, a model is simply a set of assumptions about the world expressed in a probabilistic graphical format with all the parameters and variables expressed as random components.
The Key Ideas of MBML
Bayesian Inference
The first key idea enabling this different framework for machine learning is Bayesian inference/learning. In MBML, latent/hidden parameters are expressed as random variables with probability distributions. This allows for a coherent and principled manner of quantification of uncertainty in the model parameters. Once the observed variables in the model are fixed to their observed values, initially assumed probability distributions (i.e. priors) are updated using the Bayes' theorem.
This is in contrast to the traditional/classical machine learning framework where model parameters are assigned average values that are determined by optimizing an objective function. Bayesian inference on large models over millions of variables is similarly implemented using the Bayes' theorem but in a more complex manner. This is because Bayes' theorem is an exact inference technique that is intractable over large datasets. In the past decade, the increase in the processing power of computers has enabled research and development of fast and efficient inference algorithms that can scale to large data like Belief Propagation (BP), Expectation Propagation (EP), and Variational Bayes (VB).
Factor Graphs
The second cornerstone to MBML is the use of Probabilistic Graphical Models (PGM), particularly factor graphs. A PGM is a diagrammatic representation of the joint probability distribution over all random variables in a model expressed as a graph. Factor graphs are a type of PGM that consist of circular nodes representing random variables, square nodes for the conditional probability distributions (factors), and vertices for conditional dependencies between nodes (Figure 1). They provide a general framework for modeling the joint distribution of a set of random variables.
The joint probability P(μ, X) over the whole model in Figure 1 is factorized as:
P(μ, X)=P(μ)*P(X|μ)
Where μ is the model parameter and X are the set of observed variables.
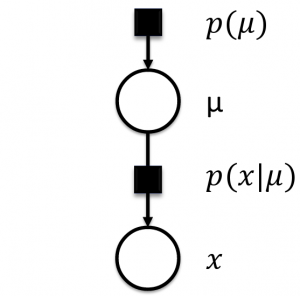
Figure 1: A Factor Graph
In factor graphs, we treat the latent parameters as random variables and learn their probability distributions using Bayesian inference algorithms along with graph. Inference/learning is simply the product of factors over a subset of variables in the graph. This allows for easy implementation of local message-passing algorithms.
Probabilistic Programming (PP)
There's a revolution in Computer Science called Probabilistic programming (PP) where programming languages are now built to compute with uncertainty in addition to computing with logic. This means that existing programming languages can now support random variables, constraints on variables and inference packages. Using a PP language, you can now describe a model of your problem in a compact form with a few lines of code. Then an inference engine is called to automatically generate inference routines (and even source code) to solve that problem. Some notable examples of PP languages include Infer.Net, Stan, BUGS, church, Figarro and PyMC. In this blog post, we will access Stan algorithms through the R interface.
Stages of MBML
There are 3 steps to model-based machine learning, namely:
- Describe the Model: Describe the process that generated the data using factor graphs.
- Condition on Observed Data: Condition the observed variables to their known quantities.
- Perform Inference: Perform backward reasoning to update the prior distribution over the latent variables or parameters. In other words, calculate the posterior probability distributions of latent variables conditioned on observed variables.
Case Study
A Simple Model for Predicting Traffic Congestion
We apply the model-based approach by following the three stages of MBML:
Stage 1: Build a model of our traffic congestion problem. We begin by listing the assumptions which our problem must satisfy. We assume that there's a latent traffic congestion state, represented by a mean (μ), that we are interested in learning. We further assume that this state has a Gaussian distribution with some mean and (known or unknown) standard deviation. This traffic congestion state will determine the observed speed measurement at the sensors (X). We then introduce a conditional probability P(X|μ) in which the probability of X is conditioned so that we have observed μ. We also know that traffic at some subsequent time period will depend on the previous traffic state. Therefore we introduce another factor graph at the next time step. We assume that its latent variable has a Gaussian distribution centered at the quantity of the previous state with some (known or unknown) standard deviation i.e. P(μ2|μ1). This simple model is shown in figure 2 below.
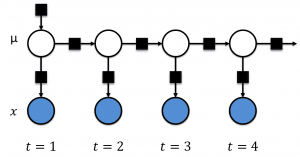
Figure 2. A Simple Model for Traffic Congestion
Stage 2: Incorporate the observed data. We condition the observed variable to their know quantities. This is represented by shading the node in blue, as shown in Figure 2 above.
Stage 3: Perform Bayesian Inference. By using a probabilistic programming language, we are able to write a compact piece of code that performs inference by simply calling a built-in inference algorithm.
The bespoke model we've built together with the inference algorithm constitutes our custom machine learning algorithm specific to our traffic prediction problem. If you are familiar with the literature, you might recognize that we have just developed a common algorithm called the Kalman filter. We can extend our model by adding other assumptions to account for weather, pavement, transportation network conditions, and sports events. These assumptions may obtain a variant of the Kalman filter, appropriate to our application. Whether this variant already exists, or whether it is a novel algorithm, is irrelevant if our goal is to find the best solution to our problem.
If we implemented our model-based algorithm and obtained less accurate results, we can easily examine and modify our model assumptions to produce a better model. In their experience, Winn et al. (2015) find it "far easier and more intuitive to understand and change the assumptions than it is to modify a machine learning algorithm directly. Even if your goal is simply to understand the Kalman filter, then starting with the model assumptions is by far the clearest and simplest way to derive the filtering algorithm, and to understand what Kalman filters are all about".
Learning the Model Parameters using a Probabilistic Programming Language
For this case study, we shall use Stan to learn the model parameters. Stan provides an R interface, RStan, which can be used to call Stan algorithms from within the R programming language Firstly, follow this link to get the prerequisites for installing RStan.
Then install the latest rstan package and the packages it depends on like this:
## omit the 's' in 'https' if your environment does not support https downloadsinstall.packages('rstan', repos = 'https://cloud.r-project.org/', dependencies = TRUE)## If all else fails, you can try to install rstan from source viainstall.packages("rstan", type = "source")You are recommended to restart R after the installation before loading the rstan package. Then load the rstan library like this:
library(rstan)Now we can describe our model for traffic congestion compactly using the Stan modeling language as follows:
- The first section of the below code specifies the data that is conditioned upon by Bayes' rule
- The second section of the code defines the parameters whose posterior distribution is sought using Bayes' rule
traffic_model <- "data {// the number of speed measurements, N; constrained to be non-negativeint<lower=0> N;// vector of observed speed measurements,y1, ..., yNvector[N] y;// the standard errors, σ1, ..., σN, of speed measurementsvector[N] sigma;}parameters {real mu; // the mean of the traffic speedsreal<lower=0> tau; // the standard deviation of the traffic speedsvector[N] theta; // the hidden statesreal<lower=0> eps; // the standard deviation of the transition pd}model {theta ~ normal(mu, tau); // the probability dbn of the hidden statesy ~ normal(theta, sigma); // the conditional probability dbn of the observed speedsfor (n in 2:N)theta[n] ~ normal(theta[n-1], eps); // the transition probability dbn}"It is recommended that we specify the above model in a separate text file with extension .stan. However, for this tutorial we shall combine it in the same R Markdown file.
After describing the model, you can perform inference by calling Stan inference engine as shown in the code chunk below. Calling the stan() function performs three fundamental operations:
- First, your Stan program is translated to C++ code using the
stanc()function, - Then the resulting C++ code is compiled to create a DSO (also called a dynamic link library (DLL)) that can be loaded by R,
- Finally, the DSO is run to sample from the posterior distribution.
The data file referred to below may be found here.
traffic <- read.table("data/traffic.txt", header = TRUE)traffic_data <- list(y = traffic[, "sensor_speed"],sigma = traffic[, "sigma"],N = nrow(traffic))traffic_model_fit <- stan(model_code = traffic_model, model_name = "traffic-prediction",data = traffic_data, iter = 1000, chains = 4, save_dso = TRUE)Evaluating Model Results
Now, we can use the print() function to check out the results in traffic_model_fit including a summary of the parameter of the model as well as the log-posterior.
print(traffic_model_fit, digits = 1)traceplot(traffic_model_fit)# extract samples# return a list of arrayse <- extract(traffic_model_fit, permuted = TRUE)mu <- e$mu# return an arraym <- extract(traffic_model_fit, permuted = FALSE, inc_warmup = FALSE)print(dimnames(m))# you can use as.array directly on our stanfit objectm2 <- as.array(traffic_model_fit)Conclusion
There are several potential benefits to using model-based machine learning, including;
- This approach provides a systematic process of developing bespoke models tailored to our specific problem.
- It provides transparency to our model as we explicitly defined our model assumptions by leveraging prior knowledge about traffic congestion.
- The approach allows the handling of uncertainty in a principled manner using probability theory.
- It does not suffer from overfitting as the model parameters are learned using Bayesian inference and not optimization.
- Finally, MBML separates the model development from inference which allows us to build several models and use the same inference algorithm to learn the model parameters. This in turn helps to quickly compare several alternative models and select the best model that is explained by the observed data.

References
For further reading, refer to the following references.
- J. Winn, C. Bishop, and T. Diethe, Model-Based Machine Learning, Microsoft Research, http://www.mbmlbook.com/, 2015.
- C. M. Bishop, “Model-based machine learning,” Phil Trans R Soc, A 371: 20120222. http://dx.doi.org/10.1098/rsta.2012.0222, Jan. 2013
- T. Minka, J. Winn, J. Guiver, and D. Knowles, Infer.NET, Microsoft Research Cambridge, http://research.microsoft.com/infernet, 2010.
- Stan Development Team, “Stan Modeling Language Users Guide and Reference Manual,” Version 2.9.0, http://mc-stan.org, 2016.
- J. Lunn, A.Thomas, N. Best, and D. Spiegelhalter, “WinBUGS --a Bayesian modeling framework: concepts, structure, and extensibility,”, Statistics and Computing, 10:325—337, 2000.
- N. D. Goodman, V. K. Mansinghka, D. M. Roy, K. Bonawitz, and J. B.Tenenbaum,“ Church: a language for generative models", In Uncertainty in Artificial Intelligence (UAI), pages 220–229, 2008.
- Patil, A., D. Huard and C.J. Fonnesbeck. 2010. PyMC: Bayesian Stochastic Modelling in Python. Journal of Statistical Software, 35(4), pp. 1-81, 2010.
- Stan Development Team, "RStan: the R interface to Stan,” Version 2.9.0".
- D. Emaasit, A. Paz, and J. Salzwedel (2016). "A Model-Based Machine Learning Approach for Capturing Activity-Based Mobility Patterns using Cellular Data". IEEE ITSC 2016. Under Review.

Daniel Emaasit is the Founder, CEO and Chief AI Officer of Logisify AI, a startup dedicated to accelerate Africa's progress towards food security, by helping suppliers of food & beverages reduce their cost of last-mile distribution. Daniel was previous a data scientist at Haystax and a PhD candidate at the University of Nevada, Las Vegas.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.