3 Key Components of the Interdisciplinary Field of Data Science
Amanda West2021-07-28 | 9 min read

Data science is an exciting, interdisciplinary field that is revolutionizing the way companies approach every facet of their business. Through a marriage of traditional statistics with fast-paced, code-first computer science doctrine and business acumen, data science teams can solve problems with more accuracy and precision than ever before, especially when combined with soft skills in creativity and communication.
In this article, we will provide an overview of the three overlapping components of data science, the importance of communication and collaboration, and how the Domino Data Lab Enterprise MLOps platform can help improve the speed and efficiency of your team.
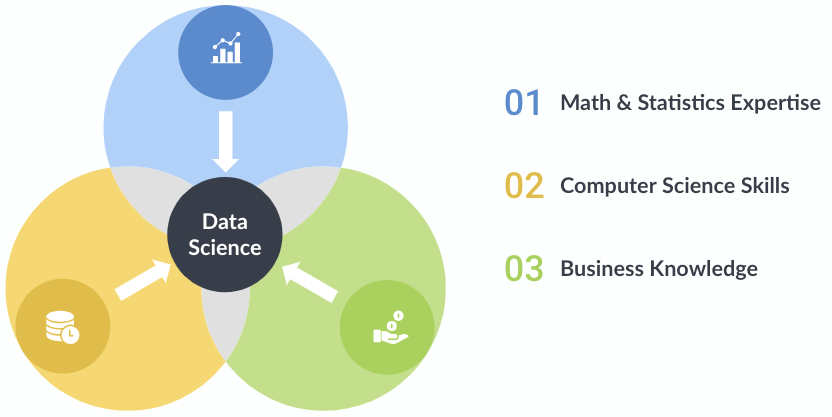
Data Science — A Venn Diagram of Skills
Data science encapsulates both old and new, traditional and cutting-edge. Many data science tools and techniques have been around for decades, with ideas and concepts repurposed from not just one field but many. This has led to rapid advancements, as the field’s interdisciplinary nature combines mathematics, statistics, computer science and business knowledge in new and novel ways.
Math and Statistics Expertise
Data science is a field that uses math and statistics as part of a scientific process to develop an algorithm that can extract insights from data. There are many software packages that allow anyone to build a predictive model, but without expertise in math and statistics, a practitioner runs the risk of creating a faulty, unethical, and even possibly illegal data science application.
All models are not made equal. Depending on what you are trying to accomplish, you will need a predictive or inferential, supervised or unsupervised or a parametric or nonparametric model. Universally, models have a basis in statistics and probability, from linear regression to decision trees to support vector machines. Further, tuning these models with regularization and k-fold cross-fold validation requires making slight changes to mathematical equations.
And here lies the importance of strong expertise in math and statistics. The differences between models can often be subtle yet drastically change accuracy and precision (the alternatives being bias and noise). Depending on the problem, it may be more important to reduce bias at the cost of precision or reduce noise at the expense of accuracy. These changes often personify themselves as square roots, lambdas or inverted matrices. It is the job of a data scientist to navigate these subtle differences, pick the model that aligns best with the problem statement, optimize and monitor performance and translate the findings back into a business context.
Math and statistics expertise is a fundamental component of data science that allows practitioners to find meaningful patterns in data that yield actionable insights.
Computer Science Skills
Computer science skills make up the second component for successful data science. Data scientists have to work with different types of data, interact with different types of computer systems, program in various languages, work in different development environments and stitch all of their work together across the entire data science lifecycle.
Before any groundbreaking data analysis is performed, data must first be acquired. This is usually through purchasing, downloading, querying or web scraping data. Websites will typically either provide an API for their data or else provide the data directly for download (usually in the form of a CSV, text or JSON).
Once data is acquired, it can then be integrated into the data science lifecycle. Most data starts as messy and must be molded to be usable. This is often no simple task; studies show that 50-80% of a data scientist's work consists of data wrangling. This can be as simple as recasting a string to a float32 or changing decimals to percent signs; however, in all cases, it is crucial to make sure you are not changing the data to mean something else entirely.
After cleaning, the data is now ready for processing. At this stage, data scientists begin writing code for computation and model-building. To model anything highly technical and computationally — machine learning, deep learning, big data analytics, and natural-language processing, to name a few — code-based tools (such as R and Python) are usually preferred. This is for many reasons; drag-and-drop programs do not typically interface with the terminal, allow the user to modify the number of cores/threads in use, nor have a plethora of open-source libraries within easy reach. Alternatively, code-based tools are more flexible and have larger online communities, which is crucial when searching through Stack Overflow to debug a few lines of code or find a better implementation for a current bottleneck.
Finally, the results from these tools are ready to be implemented in all stages of systems and processes within the organization. After thorough review, revision, possible unit-testing, code reviews and the greenlight from any relevant stakeholders.
Computer science skills empower practitioners to bring their math and science expertise to life and solve complex business problems.
Business Knowledge
The most important component of data science is business knowledge, or domain expertise. The importance of business context extends to all aspects of the data science lifecycle, from framing the problem, to imputing missing data, to incorporating the model into the business processes.
A simple example is the case of missing values. Should a practitioner delete rows with missing values, fill the values with zeros, use the average values of the adjacent rows, or just do nothing? The point is, one cannot know the best approach without the appropriate knowledge of the business scenario. There are many decisions that need to be made during the scientific process and without proper business context, it is easy to create a model with inaccurate results.
A strong understanding of the business will help a data scientist determine the best type of algorithm for the business problem, how to best prepare the data, how to evaluate and tune model performance, and ultimately how to communicate the model performance to the business stakeholders.
Communication & Collaboration
The three components of data science are critical to creating a powerful data science product, but user adoption and stakeholder buy-in requires strong communication and collaboration across teams.
When implementing a data science product, the organization and employees involved with the impacted business process must trust that the model is performing as intended. Throughout the development process, it is imperative that the business stakeholders understand the assumptions made, why the model works the way it does, and be able to understand the key drivers of any decision output. Including stakeholders in the testing and validation results, communicating the features that are most important when making predictions will help stakeholders understand and trust the model.
One of the most dangerous pitfalls a data scientist can encounter is to deliver a “black box” solution and just ask that the stakeholders trust their work. This almost always results in lack of adoption, and can also expose an organization to risk. A development process that is founded in communication and collaboration benefits the business, and can help the data science uncover business context that they did not originally hold - increasing the accuracy of the solution.
Summary
Data science has been steadily growing for the past ten years and shows no signs of stopping; a recent Dice Report found that despite the pandemic, the demand for senior data scientists across healthcare, telecommunications, entertainment, banking, and insurance sectors increased by 32% in 2020. Reasons for this may include the desire to plan for economic downturns using predictive analytics such as machine learning, better pinpoint consumer needs with clustering algorithms or improve marketing strategies through data visualization.
Domino Data Lab’s Enterprise MLOps platform strives to accelerate research, centralize infrastructure, expedite model deployment and increase collaboration in code-first data science teams. Watch a free demo to see how our platform works.

Amanda Christine West is a data scientist and writer residing in Boulder, Colorado. She received her bachelor’s from the University of Michigan and her master’s in data science from the University of Virginia. Within the field of data science, she is most passionate about predictive analytics, data visualization, big data and effective data science communication.
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.