Machine Learning Modeling: How It Works and Why It’s Important
David Weedmark2021-08-10 | 11 min read

Models are the central output of data science, and they have tremendous power to transform companies, industries, and society. At the center of every machine learning or artificial intelligence application is the ML/AI model that is built with data, algorithms and code. Even though models look like software and involve data, models have different input materials, different development processes, and different behaviors. The process of creating models is called modeling.
What Is Machine Learning Modeling?
A model is a special type of algorithm. In software, an algorithm is a hard-coded set of instructions to calculate a deterministic answer. Models are algorithms whose instructions are induced from a set of data and are then used to make predictions, recommendations, or prescribe an action based on a probabilistic assessment. The model uses algorithms to identify patterns in the data that form a relationship with an output. Models can predict things before they happen more accurately than humans, such as catastrophic weather events or who is at risk of imminent death in a hospital.
Why Are ML Models Important?
Models dramatically lower the cost of prediction, similar to how semiconductors dramatically lowered the cost of arithmetic. This change makes models the new currency of competitive advantage, strategy, and growth. Models can build on each other. One model’s output acts as the input to another, more complex model and then creates a living, connected, trainable army of decision makers. And for better or worse, models can do so autonomously, with a level of speed and sophistication that humans can’t hope to match.
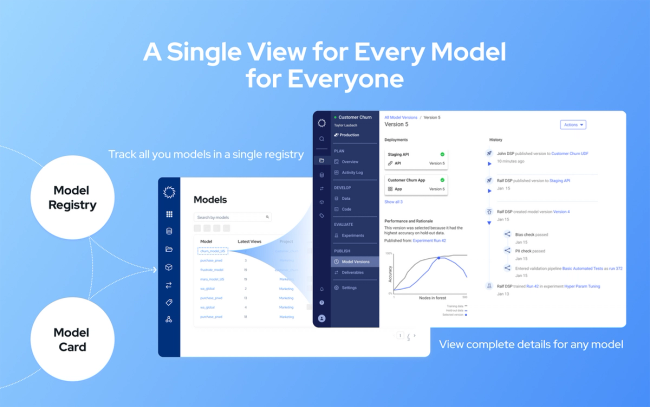
For organizations that are model-driven, modeling isn’t merely the process of creating models. It’s a framework of processes, tools and protocols that empower the data science team at every step of the data science lifecycle (DSLC).
Model governance is at the heart of modeling, which involves tracking model artifacts from the moment the first model version is constructed to the final model deployed in a production environment. Every time the model is altered or new data is used, the new versions are recorded. The health of models is continuously monitored to watch for anomalies that can creep up due changes in the input data, changes in the marketplace, or any other changes where the input data no longer parallels the data used when building the model. A model that isn’t monitored could begin producing inaccurate answers that lead to poor business performance and continue to do so without the business realizing it.
Types of Modeling Tools
Modeling tools are generally code based, although some commercial solutions exist to create simple models without code, and libraries and frameworks exist in multiple languages to help data scientists accelerate their work. These tools contain libraries of algorithms that can be leveraged to create models quickly and efficiently. Many modeling tools are open source and rely on Python, although other languages are commonly used such as R, C++, Java, Perl and many more. Some popular tool libraries and frameworks are:
- Scikit-Learn: used for machine learning and statistical modeling techniques including classification, regression, clustering and dimensionality reduction and predictive data analysis.
- XGBoost: is an open-source library that provides a regularizing gradient boosting framework for various programming languages.
- Apache Spark: is an open-source unified analytics engine designed for scaling data processing requirements.
- PyTorch: used for deep learning models, like natural language processing and computer vision. Based on Python, it was developed by Facebook’s AI Research lab as an open-source library.
- TensorFlow: similar to PyTorch, this is an open-source Python library created by Google that supports additional languages. It’s used for developing deep learning models.
- Keras: is an API built on top of TensorFlow that offers a simplified interface that requires minimal manual coding.
- Ray: is an open-source library framework that features a simple API for scaling applications from a single CPU to large clusters.
- Horovod: is a distributed deep learning training framework that can be used with PyTorch, TensorFlow, Keras, and other tools. It’s used for scaling across multiple GPUs at the same time.
There are thousands of tools available and most models require a multiple tools that are best suited for the type of data and business problem.
How Are ML Models Built?
In business environments, the inception of a new model is almost always rooted in a problem in need of a solution, like making better-informed decisions, automating procedures, or finding patterns within vast amounts of data.
Once a solution to that problem is identified, it is translated into a business goal, such as predicting inventory shortfalls, or determining credit limits for banking customers. This can then be translated into a technical problem to be solved using ML/AI models.
Depending on the type of business problem, and the available data, an approach is determined that is best suited for the problem. There are various types of machine learning approaches, including:
- Supervised learning: used when you know what the model needs to learn, typically in prediction, regression or classification. You expose the algorithm to training data, let the model analyze the output and adjust parameters until it achieves the desired goal.
- Unsupervised learning: the model is free to explore data and to identify patterns between variables. This is useful for grouping unstructured data based on statistical properties. Because it doesn’t require training, this is a much faster process.
- Reinforcement learning: used with AI, or neural networks, when a model needs to interact with an environment. When the model takes the desired action, its behavior is reinforced with a reward.
- Regression: used for training supervised models. It’s used to predict or explain a numerical value using a previous data set, like predicting changes in interest rates based on historical economic data.
- Classification: used for predicting or explaining class values in supervised learning. This is often used in ecommerce, like predicting customer purchases or responses to advertisements.
- Clustering: used with unsupervised development, these models group data according to similarities or shared properties. In business, these can be used to segment consumer markets. Social media and video platforms can use clustering to recommend new content.
- Decision Trees: use an algorithm to classify objects by answering questions about their attributes. Depending on the answer, such as “yes” or “no,” the model proceeds to another question and then another. These models can be used for predictive pricing and customer service bots.
- Deep Learning: designed to replicate the structure of the human brain. This is also called neural networks where millions of connected neurons create a complex structure that processes and reprocesses data multiple times to arrive at an answer.
Once data is acquired, it is prepared as needed for the specific approach and may include removing unnecessary or duplicate data from the data set. The data scientist will then conduct experiments with different algorithms and compare the performance on a different set of data. As an example, an image recognition model would be trained on one set of images and then tested on a fresh set of images to ensure it will perform as required. Once the performance meets the needs of the business problem, it will be ready for deployment.
Even after a model appears to be stable and is working within expected parameters, it still needs to be monitored. This can be done automatically using the Domino Model Monitor platform by specifying model accuracy metrics and then having the platform notify you if the model performs outside of those metrics. For example, if the model accuracy starts to decline, it will be necessary to investigate the cause and either retrain the model using an updated representation of the data, or even build a new model altogether.
Managing Model Risk
Model risk, whereby a model is used and fails to meet the desired outcome, can be exceptionally dangerous if safeguards are not implemented to manage it. This comes down to model risk management. If you’re familiar with finance, you’ll find that model risk management in data science is similar to risk management for financial models. There are five key aspects to model risk management, of which model governance is one.
- Model Definition: details the problem statement behind the model’s genesis, the purpose of the model’s output, as well as all development decisions, modifications and datasets used.
- Risk Governance: includes the policies, procedures, and controls to be implemented.
- Lifecycle Management: identifies model dependencies and factors that need to be heeded throughout the model’s lifecycle.
- Effective Challenge: an independent assessment and verification to ensure all decisions made during development are appropriate.
Regardless of the model performance, proper model risk management is needed to ensure that the model adheres to the desired and regulatory requirements for the organization.
Modeling in Enterprise MLOps
As organizations grow, the complexity required to manage, develop, deploy and monitor models across teams and tools can bring progress to a standstill. Enterprise MLOps platforms are purpose built to help scale data science across different teams and tools with common governance and model risk management frameworks, while supporting standardized development, deployment, and monitoring processes for all types of models. Model-driven organizations, fueled by Enterprise MLOps, are able to cash in on the new currency of competitive advantage, strategy, and growth - AI/ML models.


David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.


Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.