
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise.
Introduction
Welcome back to our monthly series about data science! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees. We had big surprises at several turns and have subsequently published a series of reports. Let’s look through some of the insights gained from those reports. Seriously, this entire article merely skims the surface of those reports. Meanwhile, the landscape is evolving rapidly. Check the end of this article for key guidance synthesized from the practices of the leaders in the field.
Surveying ABC adoption in enterprise
“When life gives you lemons, make limoncello.” After a data science conference, our marketing group wanted to follow-up by surveying 300 attendees from industry. However, a happy accident led to much bigger and better outcomes. By mistake, the survey had been sent out to 15,000 people in enterprise organizations worldwide. Then, when we received 11,400 responses, the next step became obvious to a duo of data scientists on the receiving end of that data collection. We began analyzing the serendipitously large-ish dataset, looking for trends, anomalies, unexpected insights, counter-intuitive surprises, and so on.
Over the past six months, Ben Lorica and I have conducted three surveys about “ABC” (AI, Big Data, Cloud) adoption in enterprise. Timing could hardly have been better, given how mainstream businesses have been embracing these three areas of technology in droves. O’Reilly Media published our analysis as free mini-books:
- The State of Machine Learning Adoption in the Enterprise (Aug 2018)
- Evolving Data Infrastructure: Tools and Best Practices for Advanced Analytics and AI (Jan 2019)
- AI Adoption in the Enterprise: How Companies Are Planning and Prioritizing AI Projects in Practice (Feb 2019)
Ben and I also wrote articles for each of the surveys, summarizing the highlights. In order, those are:
- “5 findings from O’Reilly’s machine learning adoption survey companies should know”
- “How companies are building sustainable AI and ML initiatives”
- “Three surveys of AI adoption reveal key advice from more mature practices”
The first survey started as a simple exploration into mainstream adoption of machine learning (ML). What’s been the impact of using ML models on culture and organization? Who builds their models? How are decisions and priorities set and by whom within the organization? What metrics are used to evaluate success? Given the timing—roughly one quarter after GDPR went into effect—it seemed like a good point in time to probe the prevailing wisdom among enterprise organizations. We were so glad that turned out to be several thousand enterprise organizations worldwide.
The second survey looked more at the data engineering aspects, specifically about frameworks being used (e.g., open source frameworks versus commercial offerings) and whether that work was migrating into the cloud.
For the third survey, we dug into details about AI among the firms which are already working with ML. What about their use cases, preferred technologies, anticipated budgets, hurdles to adoption, etc.
To design these surveys, we segmented the data using a few different dimensions. Geography was obvious, i.e., what’s the contrast between different regions of the world? Business vertical was another important priority for differentiating trends in ML practices: finance services, healthcare and lifesciences, telecom, retail, government, education, manufacturing, etc.
We also used maturity, in other words how long had an enterprise organization been deploying ML models in production? For this dimension we specified three categories, though our exact wording for them changed between each survey:
- Mature practice: “We’ve been doing this in production for 5+ years”
- Evaluation stage: “Yeah, we started a few years ago”
- Not quite yet: “Just looking, thank you very much”
Stated another way, the first category represents the “leaders” while the third category represents the “laggards” and the rest are effectively the middle-ground. This contrast provides a good basis for drawing distinctions between the leaders and the laggards.
Seriously, Ben gets credit for foresight on how to organize those surveys. I’m here mostly to provide McLuhan quotes and test the patience of our copy editors with hella Californian colloquialisms. Plus blatant overuse of intertextual parataxis. Or something.
Technologies
Companies are building data infrastructure in the cloud: 85% indicated they have data infrastructure in at least one cloud provider. Two-thirds (63%) use AWS for some portion of their data infrastructure, 37% use Microsoft Azure for some portion, and 28% use Google Cloud Platform (GCP) for some portion. Low double digits use AWS plus one other cloud, while 8% use all three of the major public clouds AWS, Azure, and GCP.
Open source frameworks commercialized as services by the cloud vendors has been a hot topic lately. Frankly, that’s been a long-term narrative arc in the evolution of cloud services—for example, I worked on a large-ish case study about Hadoop on EC2 which helped inform the launch of Elastic MapReduce. In our second survey, some interesting insights about cloud surfaced, as the following chart shows.
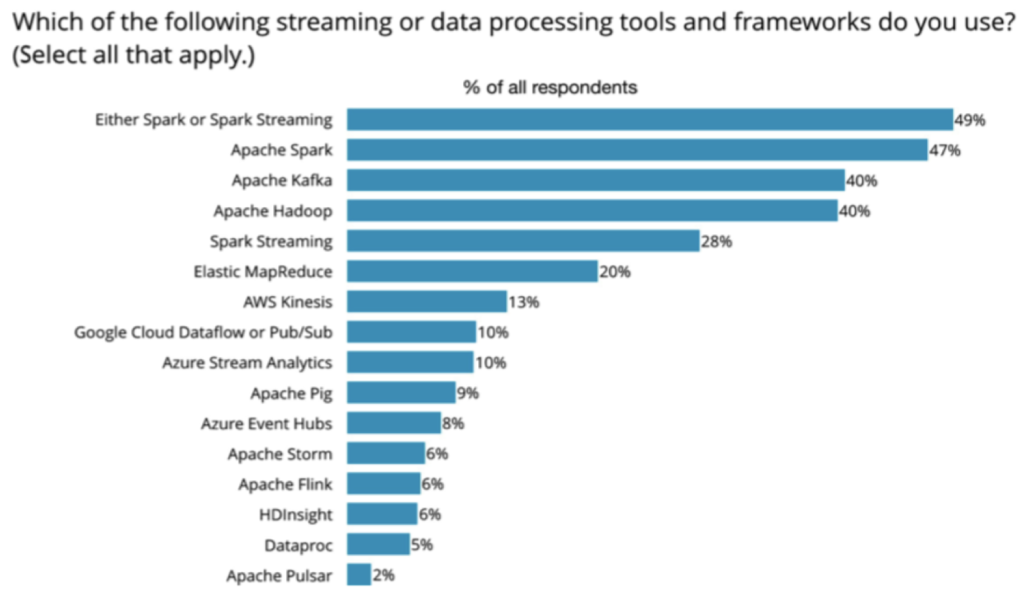
To wit, there are lots of open source frameworks used for data processing and streaming. While I hear so much about Snowflake adoption rates within mainstream IT, here we’re seeing Spark, Kafka, and Hadoop among the most popular data processing tools, along with their corresponding managed services in the cloud. Note how there’s roughly a 2:1 ratio between relying on open source and use of managed services.
Serverless is also very much on the radar. While many organizations are still in the early stages of adopting serverless technologies, among the sophisticated practices, 53% were already using serverless offerings from the major cloud vendors: AWS Lambda, GCP Cloud Functions, Azure Cloud Functions, etc. BTW, if you haven’t read the latest analysis and projects from UC Berkeley’s RISE Lab, stop what you’re doing and check out “Cloud Programming Simplified: A Berkeley View on Serverless Computing” by Dave Patterson, Ion Stoica, Eric Jonas, et al. Ten years earlier (to the day), the same set of professors published the seminal “Above the Clouds: A Berkeley View of Cloud Computing” paper which foresaw the shape of cloud adoption years ahead and guided the founding team for Apache Spark.
O’Reilly Media had an earlier survey about deep learning tools which showed the top three frameworks to be TensorFlow (61% of all respondents), Keras (25%), and PyTorch (20%)—and note that Keras in this case is likely used as an abstraction layer atop TensorFlow. This year, we’re seeing Keras (34%) and PyTorch (29%) gaining ground.
The data types used in deep learning are interesting. There are essentially four types encountered: image/video, audio, text, and structured data. While image data has been the stalwart for deep learning use cases since the proverbial “AlexNet moment” in 2011-2012, and a renaissance in NLP over the past 2-3 years has accelerated emphasis on text use cases, we note that structured data is at the top of the list in enterprise. That’s most likely a mix of devops, telematics, IoT, process control, and so on, although it has positive connotations for the adoption of reinforcement learning as well.

AI tech startups selling capabilities into enterprise, please take note. The following chart shows the ranking for ML workflow features planned over the upcoming year. Note how model visualization is bubbling up to the top, which has implications for model interpretability, cyber threats, etc.
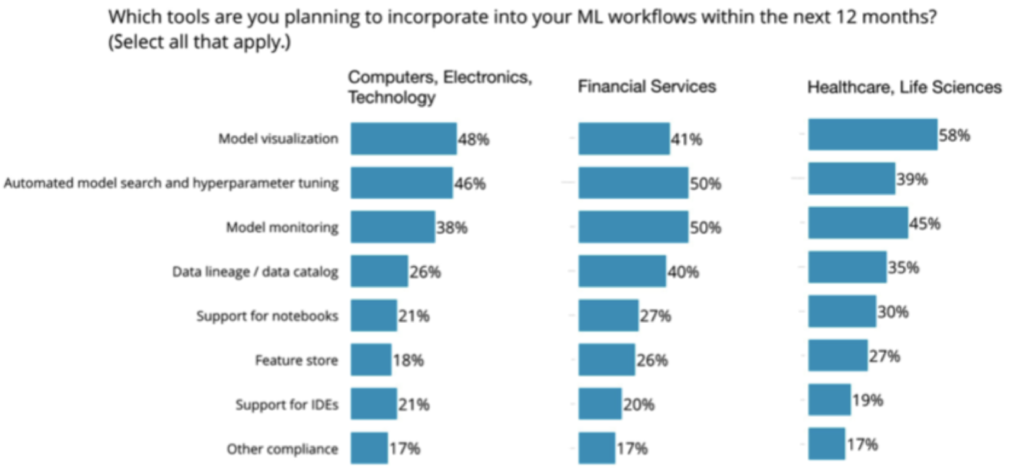
The second ranked category is also quite interesting—it ranks at the top, when you look specifically at the FinServ vertical. By mid-2018, use of AutoML had captured little interest in enterprise—only a single digit percentage among our respondents for the first survey. By November 2018, 43% reported that they planned to incorporate AutoML into their workflows sometime in 2019. Mature practices reported 86%, and within financial services the numbers were somewhat higher. That represents a significant shift in strategy and cloud providers stand to benefit. That said, AutoML does not address the full lifecycle of ML deployment.
Companies are applying AI in functional areas in which they likely have existing analytic applications, building atop that base. Meanwhile the scope of “AI” is expanding:

Half of the organizations in our survey already use deep learning. One-third use human-in-the-loop. One-quarter use knowledge graphs. One-fifth use reinforcement learning. Note that reinforcement learning is probably more widely used in production within industry than has been generally perceived, and watch for it to become much more pervasive among enterprise solutions. Also, transfer learning presents an interesting nuance, given how its use in production tends to require more experienced practitioners. We see mature practices making use of transfer learning at nearly three times the rate of evaluation stage companies. There’s value in applications of transfer learning, although those are perhaps not as apparent to the uninitiated.
Management
As one might expect, our first survey showed how the sophisticated organizations leverage their internal data science teams to build their ML models, while less experienced organizations tend to rely more on external consultants:
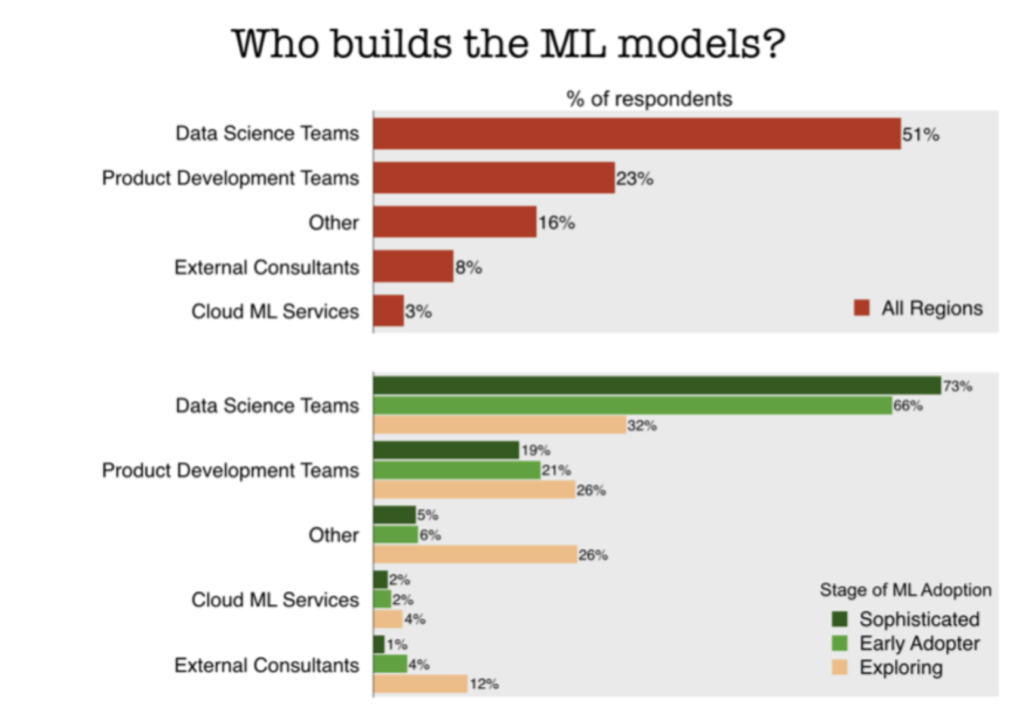
However, one surprise was that a large chunk of the more sophisticated organizations rely on data science leads to set project priorities and determine the key metrics for success:
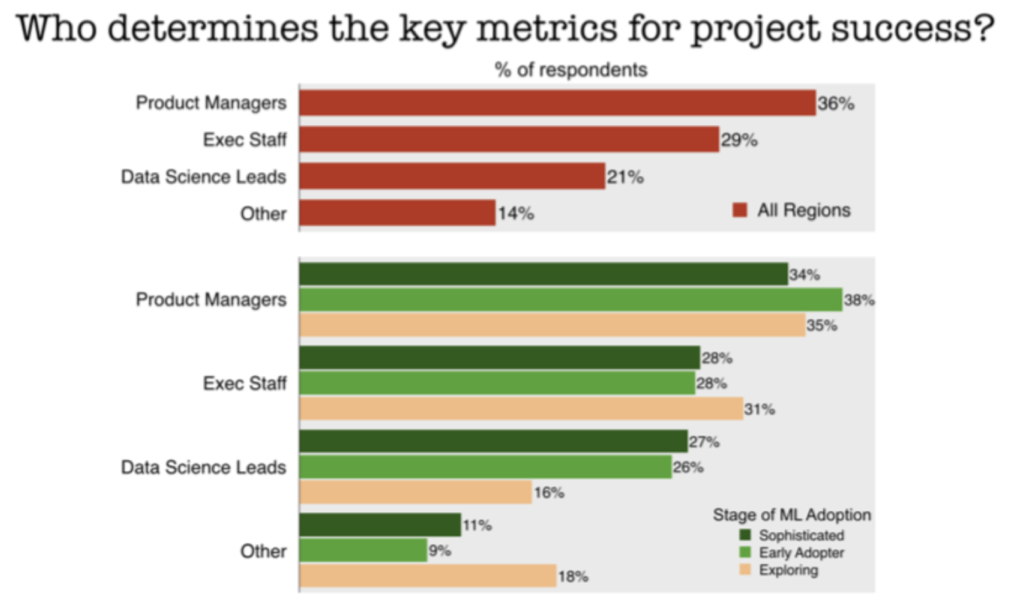
Those are traditionally the responsibilities of product managers or executives. Moreover, the more sophisticated organizations report they use “Other” methodology, instead of "Agile" methodology, substantially more. We didn't have a way to probe what that “Other” approach might be.
In any case, the introduction of ML models into production appears to run counter to “business as usual,” as we’re hearing from several directions. Typical product management and software engineering approaches simply don’t apply well to data practices. Instead, it appears that experienced companies are shifting key decisions over to the data science leads, who know their domain best.
Digging into more detail about process for ML models in production, overall 40% of respondents indicated their organizations check for model fairness and bias. Among the mature practices, that rate jumps up to 54% of respondents:
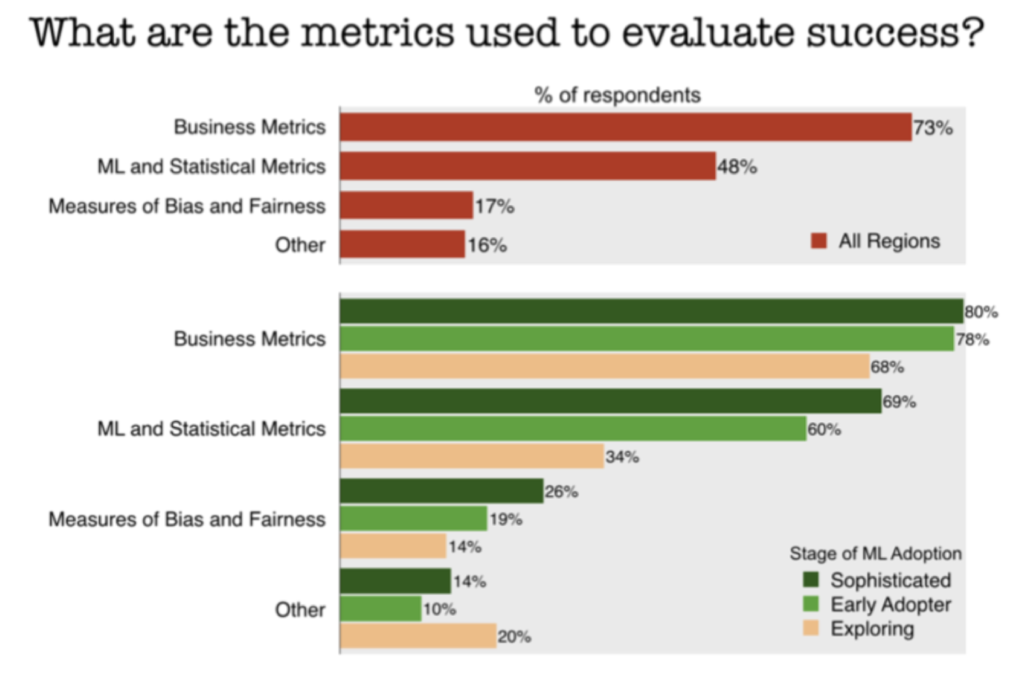
Similarly, 43% of respondents belong to companies which check for data privacy issues before moving ML models into production, and the number jumps to 53% among the mature practices.
There are far too many details within the three surveys to cover adequately in a single article. However, the punchline was saved for last:
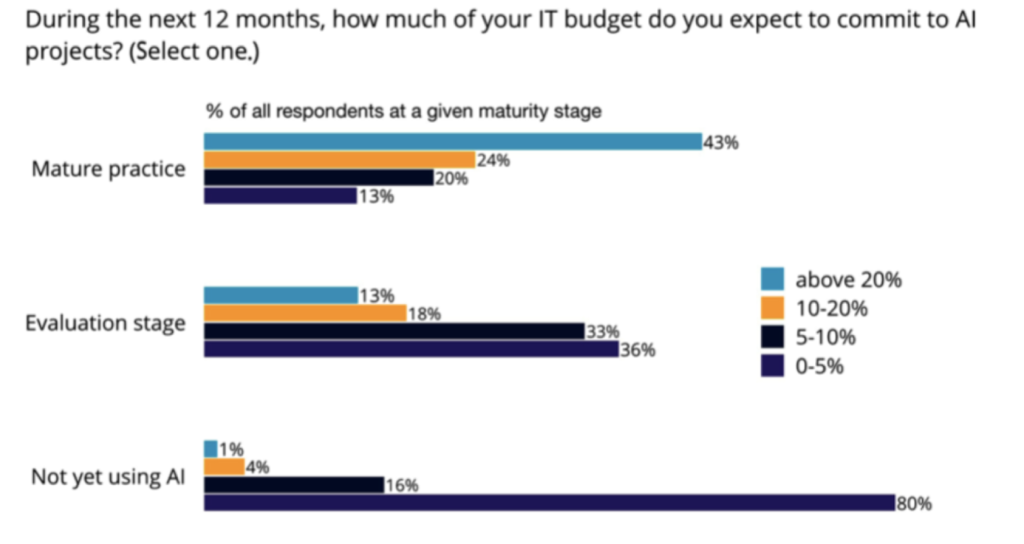
Notice how 43% of mature practices are investing 20% or more of their 2019 overall IT budget into ML projects. Translated, there’s a breakaway accelerating between the leaders and the laggards. The leaders have learned how to create ROI from ML—now they’re competitive and doubling down on their AI bets. However, the laggards have years’ worth of digital transformation, company culture detox, massive staffing hurdles, etc. to overcome before they become competitive as well.
Synthesis
As I’ve described in earlier articles, the foundations of data science represent “table stakes” for companies that intend to develop sophisticated data capabilities and eventually deploy AI applications. In other words, if a firm doesn’t first pay down tech debt and get its data infrastructure in order, it won’t progress to later stages of that journey. Those later stages are where organizations gain key insights, competitive capabilities, and recognize return on investment for data science.
In the third survey, we tried to quantify the risks encountered by enterprise organizations as they progress through the steps of that journey. The following diagram shows, in order, these steps alongside the percentage of respondents citing each step as their main bottleneck—which you can think of as survival analysis toward the successful outcome of competitive AI adoption in enterprise:
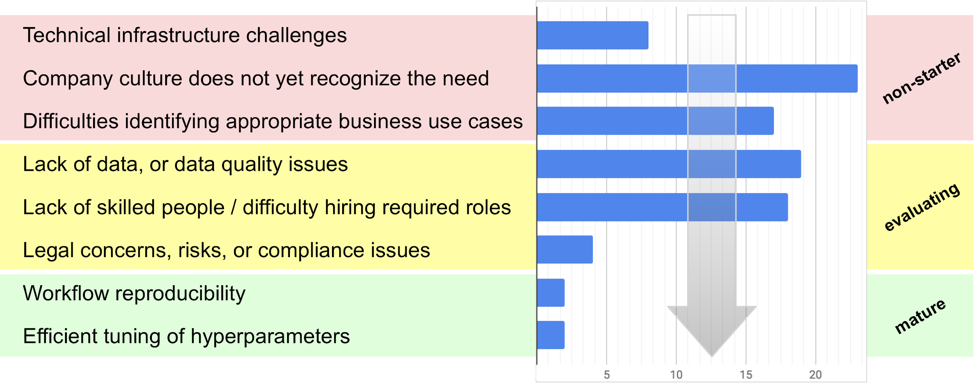
Keep in mind that 81% of respondents for the third survey work at companies which already have an interest in ML; while the sequence in the chart above applies across enterprise, the distribution of risks will be skewed more toward the problems of experienced data science practices. Also, I’m interpreting the sequence of steps based on segmenting by maturity: problems which are more prevalent among the less experienced teams get placed in the earlier steps of the journey, while latter steps are problems faced by the more experienced teams. Speaking of which, you might notice how the chart has two or three modes? These correspond to the stages of maturity—let’s drill down into those details.
The top three challenges represent “non-starter” scenarios which, as earlier studies have reported, are more commonly the stumbling points reported by the laggards. To wit, an organization first needs to fix its tech debt, break down silos, make sure that top execs are supportive, and learn how to identify the appropriate business use cases.
The next three challenges listed—lack of data, talent crunch, and compliance issues—are known to be problems even for the early adopters of ML, i.e., the more mature practices.
Frankly, I was surprised that workflow reproducibility did not get a larger share. Even so, it’s likely that reproducibility and hyperparameter optimization are problems which tend to show up after the earlier issues have been resolved and when there are larger, more complex ML projects underway.
In any case, there’s a kind of survival analysis for AI adoption. Where is your organization positioned in that journey? If you’re currently wrangling with data quality issues, you might start looking ahead at how staffing or legal concerns will be among the next hurdles to confront.
Some of those hurdles may show up at different points in the journey, depending on the organization. For example, the problems of identifying appropriate business use cases or fostering a supportive company culture may arise at later stages if a team takes a “bottom up” approach to building out their data capabilities. In other words, while your data science team may make lots of progress on its own, if product management doesn’t understand about using ML models in production or the exec staff remains skeptical, those risks can turn into strategic bottlenecks at later stages.
Meanwhile, there’s a story unfolding here in the contrast between the more mature data practices and the organizations which haven’t made as much progress. Our main takeaway from the three surveys is that the leaders are breaking away from the laggards at an accelerating rate. The proof point is how the mature practices are investing so heavily in 2019 in ML projects.
I’ve tried to summarize some overall guidance emerging from these mature practices:
- Work early toward overcoming challenges related to company culture or not being able to recognize the business use cases. Do the footwork, educate the other stakeholders, and build consensus.
- Your organization probably needs to invest more in infrastructure engineering than it thinks—perpetually. While it’s vitally important to do this, don’t let the tail wag the dog: the referenceable companies which “Do data science well” invest in good infra enough to move its concerns off center stage, empowering data science teams to be responsible for much more of the ML business lifecycle than simply handing off models to engineering teams. Stated another way, if your platform engineering tail is perpetually wagging the business use case dog, your firm will probably pay too much overhead to sustain its data science initiatives over the long term.
- Develop internal data science capabilities to build and curate ML models rather than outsourcing that work. Also, establish clear roles such as data scientist and data engineer rather than trying to shoehorn those responsibilities into legacy roles such as business analyst. I hear excellent arguments for citizen data science in organizations which are sincere about it—although not when the phrase translates in a legacy enterprise context to “Let’s just keep doing what we’ve done since the 1990s.”
- Be mindful that both the lack of data and the lack of skilled people will pose ongoing challenges. Keep investing in those. The required transformations in large enterprise take years. Having effective infrastructure is table stakes in this poker game, but players who tend to fold early won’t even win back their ante.
- When hiring data scientists and data engineers, complement by hiring people who can identify the appropriate business use cases for available ML technologies. There’s a dearth of proven recipes yet for “Product Management for AI,” and that expertise will take time to cultivate at the organizational level.
- It may work better, for now, to have data science leads set team priorities and determine key metrics for project success instead of retrofitting product managers who are unfamiliar with data science processes and concerns.
- Beyond simply optimizing for business metrics, also employ robust checklists for model transparency and interpretability, fairness and bias, ethics, privacy, security, reliability, and other aspects of compliance.
- Explore use cases beyond deep learning: other solutions are gaining significant traction, including human-in-the-loop, knowledge graphs, and reinforcement learning.
- Look for use cases where you can apply transfer learning, which is a nuanced technique in which the more advanced practices recognize much value.
One other thing…a point that I keep hearing preached is how there’s a looming disconnect between data scientists and engineers. Instead, the looming disconnect which you need to stay up late worrying about is at the gap between engineering deployment of ML and the “last mile” of business use cases. Spark, Kafka, TensorFlow, Snowflake, etc., will not save you there. AutoML will not save you there. That’s the point where models degrade once exposed to live customer data, and where it requires significant statistical expertise to answer even a simple “Why?” question from stakeholders. That’s the point where a large attack surface gets exposed to security exploits against the input data—with currently almost unimaginable magnitude of consequences. That’s where complex ethics and compliance issues arise which cause angry regulators to come knocking. Those are business issues. Stop bloating data engineering teams as a panacea when ultimately the business issues are what will cause your organization the most grief. We’re not enough years into AI adoption in enterprise yet for case studies about those issues to become standard HBS lectures, but they will be. Soon.

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.