
This post describes how Domino uses Docker to solve a number of interconnected problems for data scientists and researchers, related to environment agility and reproducibility of work.
Background
At Domino, we rely heavily on Docker. But while most discussions about Docker focus on how engineers use Docker to ship their software, we use Docker in our product itself, to allow data scientists to easily control what sort of environment (packages, libraries, etc.) to use when they work. In other words, we expose Docker as a user-facing feature (in addition to using it internally as a DevOps tool).
Quick background for those who aren’t familiar with Domino: it's a platform where data scientists run their code (e.g., R, Python, etc), track their experiments, share their work and deploy models. Centralized infrastructure and knowledge management makes data scientists more productive and enables more reproducible, collaborative data science.
The Problem of Environment Management
A common pain point among researchers and data scientists is that of “environment management.” I use this term to describe a constellation of issues related to installing software and packages, and configuring settings, to doing analytical work individually or on a team. Some of the problems we see most often are:
- Researchers are often bottlenecked on central IT resources to install new packages. If this process is too slow or time consuming, organizations can't stay at the cutting edge of modern techniques and tools. More than ever before, there's rapid development in the open source ecosystem, and organizations need agility around testing and adopting new techniques and methods.
- Setting aside new packages, slow or bureaucratic processes can delay updates to standard tools and packages (new versions of R, Python, etc), resulting in critical components that are years out of date.
- Code works differently (or sometimes doesn’t work at all) for different people, because their environments are different (e.g., different versions of packages).
- Difficulty in on-boarding new hires or team members, because setting up their environment takes a long time.
- Old projects become unusable and old results become impossible to reproduce, because the environment has changed since the code was written.
- Upgrades (e.g., changing the underlying version of R or Python, or upgrading a particular package) is risky because it’s hard to know what will stop working.
Typically, companies follow one of two paths with respect to environment management. Each of which solves some of the problems above, but exacerbates the others:
- Companies let users control their own environments. That gives users flexibility and agility but inevitably leads to inconsistent environments. Often, this means work is siloed on researchers’ machines, making it harder to share and collaborate, and also limiting users’ compute resources.
- Companies lock down central environments, e.g., large shared "research servers". IT controls these machines. Users get access to consistent environments, but those environments are difficult to change.
Compute Environments Built on Docker
Domino defines a first-class notion of a Compute Environment: an environment that contains the set of software and configuration files that should be in place when analytical code is run. This is powerful for several reasons:
- Environments are attached to the project where your code lives. So, if someone revisits a project 12 months later or a new hire joins a project, you can be sure the code will work as expected, regardless of what's installed on your computer.
- Researchers can change environments, upgrade or install new libraries without going through IT, and, critically, without affecting anyone else’s environment.
- Unlike a design where researchers manipulate their own machines, Domino’s Environments are centrally stored and managed. Researchers can easily share environments, and environments can be upgraded for everyone at once.
Under the hood, a Compute Environment is built upon a Docker image. When a researcher runs code, their code is run in a container started from that image.
Using Docker is especially powerful, because it lets us preserve past version of the images, so that we can keep a record of the exact environment that was used to generate any past result.
New capabilities
Let’s take a look at some of the workflows this design enables.
Using different versions of common tools
Let's say some of your users work with Python 3 and some work with Python 2. Or some work with the standard R distribution and others work with a Revolution Analytics distribution of R. You can create environments for each of these configurations, and data scientists can choose whichever they want to use when they work:
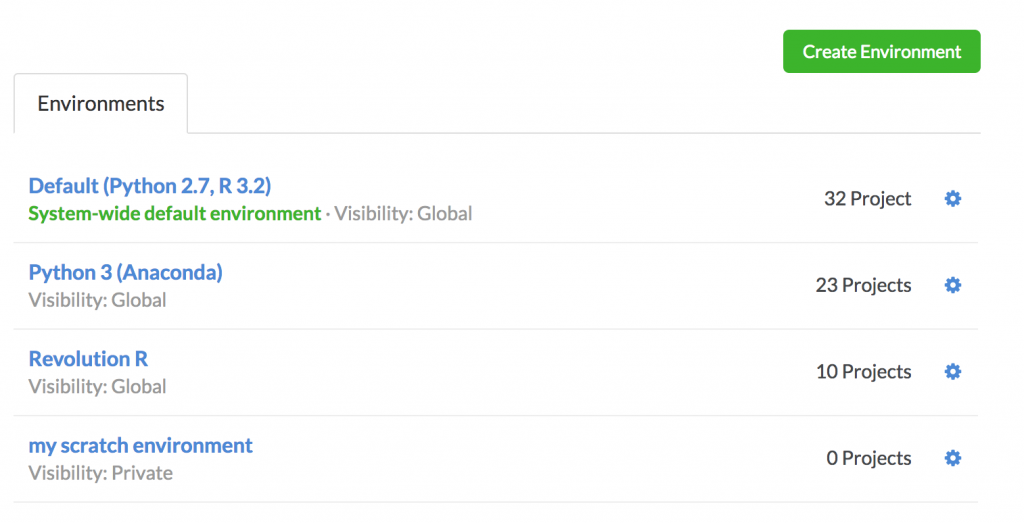
Create as many environments as you'd like, and manage how they are shared and permissioned, to create a variety of standard environment choices within your organization.
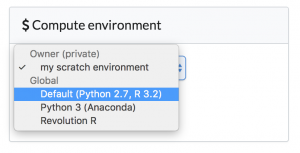
Upgrading an important library
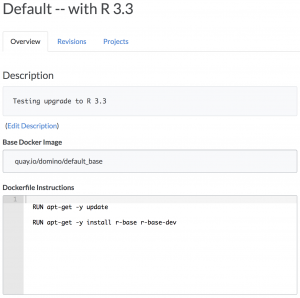
Under the hood, Domino lets you specify the contents of an environment by running Docker commands. To see this in action, let's say the Default environment has R 3.2 and you're interested in upgrading R 3.3. And because we're cautious, let's say we want to test this change out on our own project to verify it works properly before we roll it out to everyone.
We can make a copy of the "Default" environment and add whatever Docker commands we want to run on top of it.
Now we just change our project to use this new environment and re-run our code.
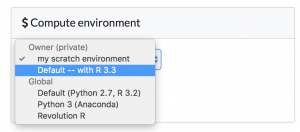
I have a regression test script I've run in the past, "test.R". Once I've changed selected the new environment, I can re-run that script. Critically, I can re-run the exact version I had run last time, so I can be sure that any differences I see in the results will be due entirely to the R upgrade, not changes in my code.
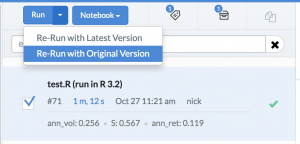
We can even compare the results from running in one environment and the other, to make sure nothing changed.
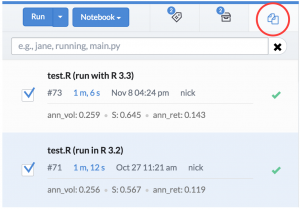
For a deeper dive on how to compare results from different experiments in Domino, check out our past posts about "unit testing" for data science and model tuning and experimentation.
Reproducing past work
In addition to giving data scientists much more agility, Domino keeps an immutable record of every execution of your code, including information about which environment it was run in. So it's easy to find and restore, for any past result, the exact set of software that was used to reproduce any past result.
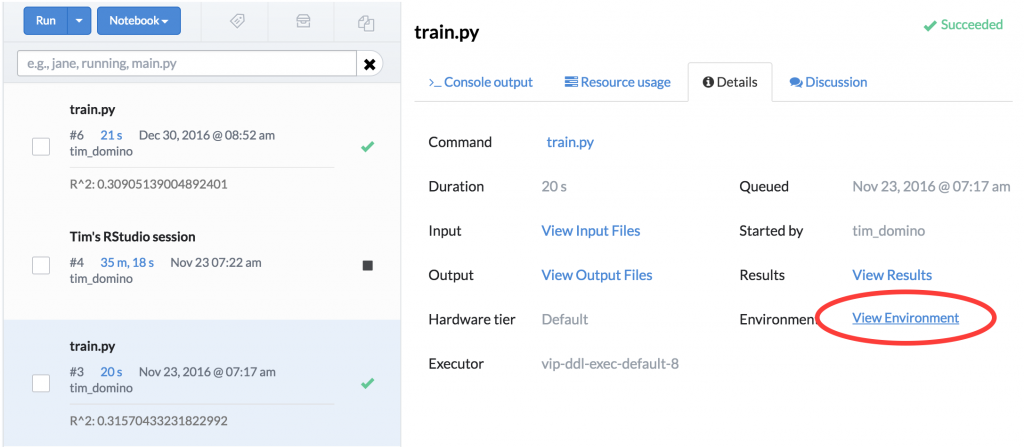
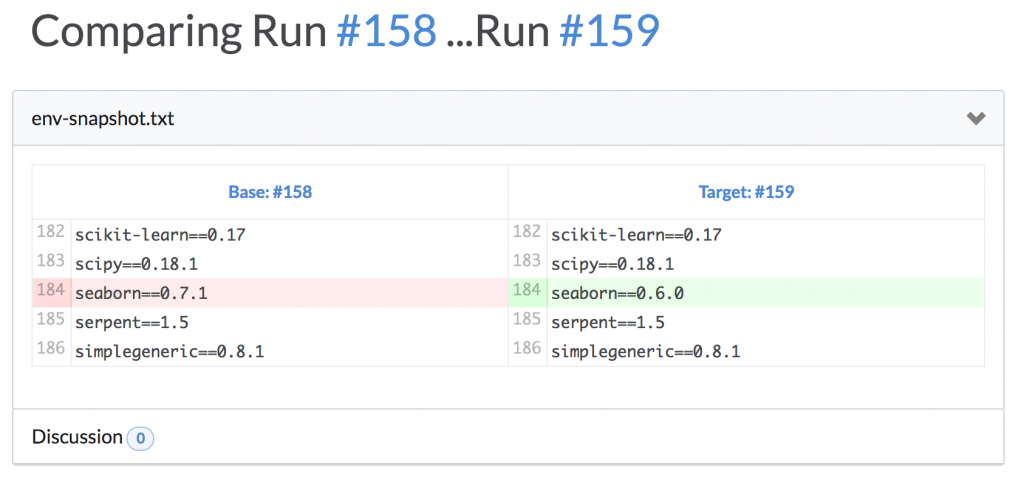
We can take this further. In addition to comparing the results of experiments after changing environments, Domino can be configured to preserve text snapshots of the state of your environment whenever you run code. This lets you use our diffing feature to inspect what packages or software might have changed between two different runs of the same experiment.
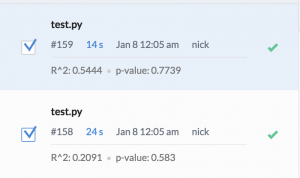
In this example, we had a python script that we ran at different times, and we were interested in identifying any changes in the underlying environment. Comparison can show us that, as well.
Conclusion
Docker is a tremendously powerful piece of technology. In addition to enabling new workflows for DevOps teams, it can elegantly solve a number of problems that face data scientists on a daily basis. Building upon Docker as a foundation, Domino's "Compute Environment" functionality gives researchers the agility to easily experiment with new packages without undermining stability of their colleagues' environments. At the same time, Compute Environments give researchers the ability to reproduce results and audit changes down the level of the set of installed software and packages.

Nick Elprin is the CEO and co-founder of Domino Data Lab, provider of the open data science platform that powers model-driven enterprises such as Allstate, Bristol Myers Squibb, Dell and Lockheed Martin. Before starting Domino, Nick built tools for quantitative researchers at Bridgewater, one of the world's largest hedge funds. He has over a decade of experience working with data scientists at advanced enterprises. He holds a BA and MS in computer science from Harvard.
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.