Joshua Poduska provides a distilled overview of Ludwig including when to use Ludwig’s command-line syntax and when to use its Python API.
Introduction
New tools are constantly being added to the deep learning ecosystem. It can be fun and informative to look for trends in the type of tools being created. For example, there have been multiple promising tools created recently that have Python APIs, are built on top of TensorFlow or PyTorch, and encapsulate deep learning best practices to allow data scientists to speed up research. Examples include Ludwig and Fast.ai.
This blog post considers Ludwig, offering a brief overview of the package and providing tips for practitioners such as when to use Ludwig’s command-line syntax and when to use its Python API. This blog also provides code examples with a Jupyter notebook that you can download or run via hosting provided by Domino.
Ludwig Design Principles
I recently attended a meetup held at Uber HQ in San Francisco. Piero Molino, the main architect and maintainer of Ludwig, presented. He summarized the magic of Ludwig into three things:
- The data type abstraction
- The model definition via a YAML file
- The smart use of keyworded arguments (**kwargs)
I’ll briefly explain why Peiro made this statement, and you may find it helpful to view this graphic of Ludwig’s design workflow from the Uber engineering blog before you read my explanation.
Beginning their analytical strategy with a data type abstraction allowed the Uber engineering team to better integrate deep learning best practices for model training, validation, testing and deployment. Ludwig can leverage the same data preprocessing and postprocessing on different datasets with common types. This abstraction concept extends to the application of encoders. Encoders are simply deep nets -- parallel CNN, stacked CNN, stacked parallel CNN, RNN, etc. The same encoding and decoding models developed for one task can be reused for different tasks.
While an expert can play with the details of these networks, a novice can also access the proven default settings for model training. It is easy to plug in new encoders, decoders and combiners via the YAML file. Experts or intermediates also find it simple to tweak model behavior and hyperparameters with the many optional **kwargs found in the User’s Guide.
Ludwig allows users to train a model, load a model, predict using this model and run an experiment. These actions are run via command line or the programmatic API. Training a model in Ludwig only requires a CSV dataset and a model definition YAML file.
Ludwig Experiments and Output
The experiment feature captures the essence of the Ludwig package as it unifies all the design principles in one. In an experiment, Ludwig will create an intermediate preprocessed version of the input CSV with an hdf5 extension. This happens the first time a CSV file is used in the same directory with the same name, then the subsequent experiment runs leverage this data. Ludwig randomly splits the data and trains the model on the training set until accuracy on the validation set stops improving. Experiment logging and output can be found in a results directory with hyperparameters and summary statistics of the process. I have found this auto-logging to be very helpful. In my work, it is common for each run to represent a tweak of the model. The Ludwig output is auto-organized in directories. You can name each experiment or take the default names like I did.
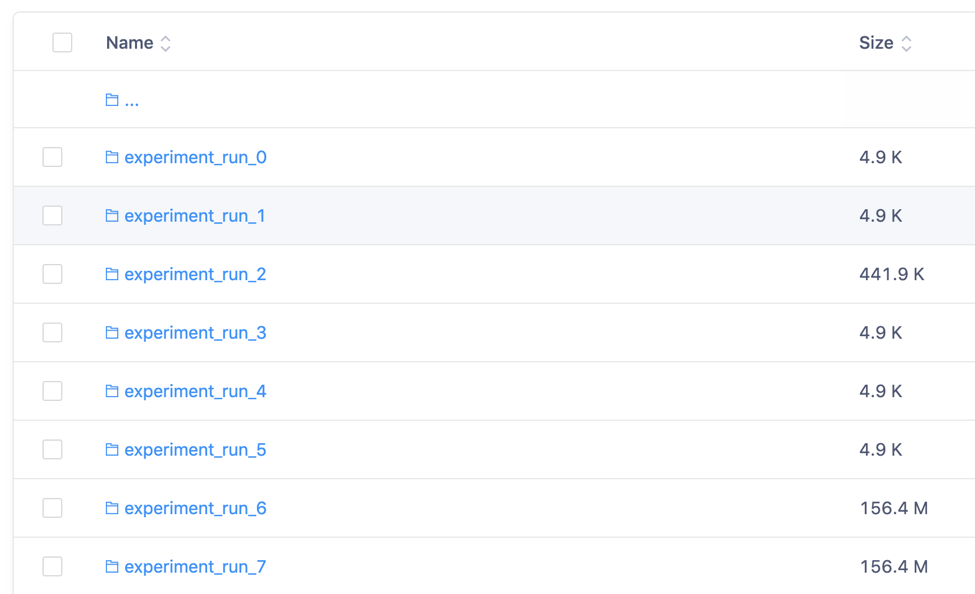
When working with Ludwig, it helps if you’re purposeful in the way you manage this auto-generated output. Syncing your output directory with a Git project and adding commit notes or using an automatic reproducibility engine like the one Domino offers can save a lot of headaches when you try to recreate results. The key is to organize your experiments in a way that you can remember what changed, run to run.
Ludwig Practitioner Tips
Using any new tool can create some growing pains before you figure out the optimal way to leverage it in your work. In this section, I summarize the lessons I learned while using Ludwig to help you get up to speed faster as you perform your own evaluation.
Practitioner Tip #1 - The command line is great for running experiments.
Most of Ludwig's features are available by command line or Python API. However, some of the programmatic API functions are technically accessible but not yet fully supported, as noted in this discussion thread. The command line is a bit more full-featured. One example of this is the Ludwig experiment. While it needs to be run step-by-step when working with the API, when called via command line Ludwig automatically splits the data and trains the model on the training set until accuracy on the validation set stops improving -- a nice feature.
Below is an example of the syntax to kick off an experiment via command line.
ludwig experiment \--data_csv sequence_tags.csv \--model_definition_file model_definition.yamlOn the other hand, you would need to train and test on your own via the Python API.
Practitioner Tip #2 - The command-line calls for visualizations can be difficult to use on some systems.
Getting the visualizations to display can be a frustrating exercise. Basic code improvements like including an option to save the image instead of only displaying it are in the works. You will have the ability to save images via the CLI if you install Ludwig from the GitHub master. See here for a discussion thread on this topic.
Practitioner Tip #3 - Experiment via command line and plot via the API calls.
I like to combine Tip #1 and Tip #2 to run experiments via command-line calls and build visualizations via Python API calls. My system did not cooperate when trying to display visualizations via command line, but plotting those via the API calls from a notebook worked just fine. It is easy to execute both command-line and API calls in a Jupyter notebook with the following syntax and output as an example.
!ludwig experiment \--data_csv ../data/raw/reuters-allcats.csv \--model_definition_file ../model_definition.yaml \--output_directory ../resultsfrom ludwig import visualizevisualize.learning_curves(['../results/experiment_run_7/training_statistics.json'],None)
An example notebook can be downloaded and/or run via hosting provided by Domino.
Summary
As deep learning methods and principles evolve, we will see more tools like Ludwig that extract best practices into a code-base built on top of deep learning frameworks like TensorFlow and are accessible via Python APIs. This will increase the adoption of deep learning approaches across industries and lead to exciting new deep learning applications.

Josh Poduska is the Chief Field Data Scientist at Domino Data Lab and has 20+ years of experience in analytics. Josh has built data science solutions across domains including manufacturing, public sector, and retail. Josh has also managed teams and led data science strategy at multiple companies, and he currently manages Domino’s Field Data Science team. Josh has a Masters in Applied Statistics from Cornell University. You can connect with Josh at https://www.linkedin.com/in/joshpoduska/
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.